


COMPOSITION
-
Composition – cinematography Cheat Sheet
Read more: Composition – cinematography Cheat Sheet
Where is our eye attracted first? Why?
Size. Focus. Lighting. Color.
Size. Mr. White (Harvey Keitel) on the right.
Focus. He’s one of the two objects in focus.
Lighting. Mr. White is large and in focus and Mr. Pink (Steve Buscemi) is highlighted by
a shaft of light.
Color. Both are black and white but the read on Mr. White’s shirt now really stands out.
(more…)
What type of lighting? -
Types of Film Lights and their efficiency – CRI, Color Temperature and Luminous Efficacy
Read more: Types of Film Lights and their efficiency – CRI, Color Temperature and Luminous Efficacynofilmschool.com/types-of-film-lights
“Not every light performs the same way. Lights and lighting are tricky to handle. You have to plan for every circumstance. But the good news is, lighting can be adjusted. Let’s look at different factors that affect lighting in every scene you shoot. “
Use CRI, Luminous Efficacy and color temperature controls to match your needs.
Color Temperature
Color temperature describes the “color” of white light by a light source radiated by a perfect black body at a given temperature measured in degrees Kelvinhttps://www.pixelsham.com/2019/10/18/color-temperature/
CRI
“The Color Rendering Index is a measurement of how faithfully a light source reveals the colors of whatever it illuminates, it describes the ability of a light source to reveal the color of an object, as compared to the color a natural light source would provide. The highest possible CRI is 100. A CRI of 100 generally refers to a perfect black body, like a tungsten light source or the sun. “https://www.studiobinder.com/blog/what-is-color-rendering-index
(more…)













DESIGN




















COLOR
-
Capturing the world in HDR for real time projects – Call of Duty: Advanced Warfare
Read more: Capturing the world in HDR for real time projects – Call of Duty: Advanced WarfareReal-World Measurements for Call of Duty: Advanced Warfare
www.activision.com/cdn/research/Real_World_Measurements_for_Call_of_Duty_Advanced_Warfare.pdf
Local version
Real_World_Measurements_for_Call_of_Duty_Advanced_Warfare.pdf

-
Yasuharu YOSHIZAWA – Comparison of sRGB vs ACREScg in Nuke
Read more: Yasuharu YOSHIZAWA – Comparison of sRGB vs ACREScg in NukeAnswering the question that is often asked, “Do I need to use ACEScg to display an sRGB monitor in the end?” (Demonstration shown at an in-house seminar)
Comparison of scanlineRender output with extreme color lights on color charts with sRGB/ACREScg in color – OCIO -working space in NukeDownload the Nuke script:
-
mmColorTarget – Nuke Gizmo for color matching a MacBeth chart
Read more: mmColorTarget – Nuke Gizmo for color matching a MacBeth charthttps://www.marcomeyer-vfx.de/posts/2014-04-11-mmcolortarget-nuke-gizmo/
https://www.marcomeyer-vfx.de/posts/mmcolortarget-nuke-gizmo/
https://vimeo.com/9.1652466e+07
https://www.nukepedia.com/gizmos/colour/mmcolortarget
-
PBR Color Reference List for Materials – by Grzegorz Baran
Read more: PBR Color Reference List for Materials – by Grzegorz Baran
“The list should be helpful for every material artist who work on PBR materials as it contains over 200 color values measured with PCE-RGB2 1002 Color Spectrometer device and presented in linear and sRGB (2.2) gamma space.
All color values, HUE and Saturation in this list come from measurements taken with PCE-RGB2 1002 Color Spectrometer device and are presented in linear and sRGB (2.2) gamma space (more info at the end of this video) I calculated Relative Luminance and Luminance values based on captured color using my own equation which takes color based luminance perception into consideration. Bare in mind that there is no ‘one’ color per substance as nothing in nature is even 100% uniform and any value in +/-10% range from these should be considered as correct one. Therefore this list should be always considered as a color reference for material’s albedos, not ulitimate and absolute truth.“











LIGHTING
-
Willem Zwarthoed – Aces gamut in VFX production pdf
Read more: Willem Zwarthoed – Aces gamut in VFX production pdfhttps://www.provideocoalition.com/color-management-part-12-introducing-aces/
Local copy:
https://www.slideshare.net/hpduiker/acescg-a-common-color-encoding-for-visual-effects-applications
-
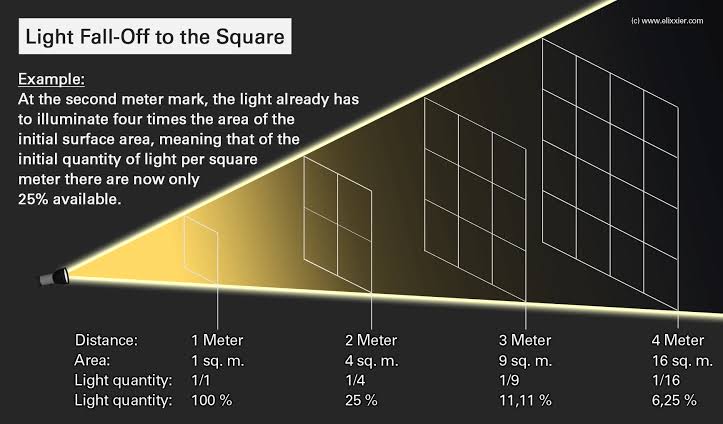
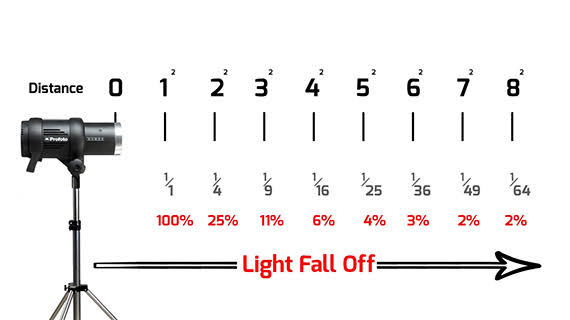
Convert between light exposure and intensity
Read more: Convert between light exposure and intensityimport math,sys def Exposure2Intensity(exposure): exp = float(exposure) result = math.pow(2,exp) print(result) Exposure2Intensity(0) def Intensity2Exposure(intensity): inarg = float(intensity) if inarg == 0: print("Exposure of zero intensity is undefined.") return if inarg < 1e-323: inarg = max(inarg, 1e-323) print("Exposure of negative intensities is undefined. Clamping to a very small value instead (1e-323)") result = math.log(inarg, 2) print(result) Intensity2Exposure(0.1)Why Exposure?
Exposure is a stop value that multiplies the intensity by 2 to the power of the stop. Increasing exposure by 1 results in double the amount of light.
Artists think in “stops.” Doubling or halving brightness is easy math and common in grading and look-dev.
Exposure counts doublings in whole stops:- +1 stop = ×2 brightness
- −1 stop = ×0.5 brightness
This gives perceptually even controls across both bright and dark values.
Why Intensity?
Intensity is linear.
It’s what render engines and compositors expect when:- Summing values
- Averaging pixels
- Multiplying or filtering pixel data
Use intensity when you need the actual math on pixel/light data.
Formulas (from your Python)
- Intensity from exposure: intensity = 2**exposure
- Exposure from intensity: exposure = log₂(intensity)
Guardrails:
- Intensity must be > 0 to compute exposure.
- If intensity = 0 → exposure is undefined.
- Clamp tiny values (e.g.
1e−323) before using log₂.
Use Exposure (stops) when…
- You want artist-friendly sliders (−5…+5 stops)
- Adjusting look-dev or grading in even stops
- Matching plates with quick ±1 stop tweaks
- Tweening brightness changes smoothly across ranges
Use Intensity (linear) when…
- Storing raw pixel/light values
- Multiplying textures or lights by a gain
- Performing sums, averages, and filters
- Feeding values to render engines expecting linear data
Examples
- +2 stops → 2**2 = 4.0 (×4)
- +1 stop → 2**1 = 2.0 (×2)
- 0 stop → 2**0 = 1.0 (×1)
- −1 stop → 2**(−1) = 0.5 (×0.5)
- −2 stops → 2**(−2) = 0.25 (×0.25)
- Intensity 0.1 → exposure = log₂(0.1) ≈ −3.32
Rule of thumb
Think in stops (exposure) for controls and matching.
Compute in linear (intensity) for rendering and math. -
DiffusionLight: HDRI Light Probes for Free by Painting a Chrome Ball
Read more: DiffusionLight: HDRI Light Probes for Free by Painting a Chrome Ballhttps://diffusionlight.github.io/
https://github.com/DiffusionLight/DiffusionLight
https://github.com/DiffusionLight/DiffusionLight?tab=MIT-1-ov-file#readme
https://colab.research.google.com/drive/15pC4qb9mEtRYsW3utXkk-jnaeVxUy-0S
“a simple yet effective technique to estimate lighting in a single input image. Current techniques rely heavily on HDR panorama datasets to train neural networks to regress an input with limited field-of-view to a full environment map. However, these approaches often struggle with real-world, uncontrolled settings due to the limited diversity and size of their datasets. To address this problem, we leverage diffusion models trained on billions of standard images to render a chrome ball into the input image. Despite its simplicity, this task remains challenging: the diffusion models often insert incorrect or inconsistent objects and cannot readily generate images in HDR format. Our research uncovers a surprising relationship between the appearance of chrome balls and the initial diffusion noise map, which we utilize to consistently generate high-quality chrome balls. We further fine-tune an LDR difusion model (Stable Diffusion XL) with LoRA, enabling it to perform exposure bracketing for HDR light estimation. Our method produces convincing light estimates across diverse settings and demonstrates superior generalization to in-the-wild scenarios.”






















{kind=link}
{kind=link}
COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
AI Data Laundering: How Academic and Nonprofit Researchers Shield Tech Companies from Accountability
-
Jesse Zumstein – Jobs in games
-
Methods for creating motion blur in Stop motion
-
NVidia – High-Fidelity 3D Mesh Generation at Scale with Meshtron
-
Types of Film Lights and their efficiency – CRI, Color Temperature and Luminous Efficacy
-
Principles of Animation with Alan Becker, Dermot OConnor and Shaun Keenan
-
Rec-2020 – TVs new color gamut standard used by Dolby Vision?
-
AI Search – Find The Best AI Tools & Apps
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
