


COMPOSITION
-
9 Best Hacks to Make a Cinematic Video with Any Camera
Read more: 9 Best Hacks to Make a Cinematic Video with Any Camerahttps://www.flexclip.com/learn/cinematic-video.html
- Frame Your Shots to Create Depth
- Create Shallow Depth of Field
- Avoid Shaky Footage and Use Flexible Camera Movements
- Properly Use Slow Motion
- Use Cinematic Lighting Techniques
- Apply Color Grading
- Use Cinematic Music and SFX
- Add Cinematic Fonts and Text Effects
- Create the Cinematic Bar at the Top and the Bottom
















DESIGN
-
Principles of Interior Design – Balance
Read more: Principles of Interior Design – Balancehttps://www.yankodesign.com/2024/09/18/principles-of-interior-design-balance
The three types of balance include:
- Symmetrical Balance
- Asymmetrical Balance
- Radial Balance














COLOR
-
Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental process
Read more: Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental processhttps://www.chrbutler.com/understanding-the-eye-mind-connection
The intricate relationship between the eyes and the brain, often termed the eye-mind connection, reveals that vision is predominantly a cognitive process. This understanding has profound implications for fields such as design, where capturing and maintaining attention is paramount. This essay delves into the nuances of visual perception, the brain’s role in interpreting visual data, and how this knowledge can be applied to effective design strategies.
This cognitive aspect of vision is evident in phenomena such as optical illusions, where the brain interprets visual information in a way that contradicts physical reality. These illusions underscore that what we “see” is not merely a direct recording of the external world but a constructed experience shaped by cognitive processes.
Understanding the cognitive nature of vision is crucial for effective design. Designers must consider how the brain processes visual information to create compelling and engaging visuals. This involves several key principles:
- Attention and Engagement
- Visual Hierarchy
- Cognitive Load Management
- Context and Meaning

-
Colour – MacBeth Chart Checker Detection
Read more: Colour – MacBeth Chart Checker Detectiongithub.com/colour-science/colour-checker-detection
A Python package implementing various colour checker detection algorithms and related utilities.

-
PTGui 13 beta adds control through a Patch Editor
Read more: PTGui 13 beta adds control through a Patch EditorAdditions:
- Patch Editor (PTGui Pro)
- DNG output
- Improved RAW / DNG handling
- JPEG 2000 support
- Performance improvements

-
Akiyoshi Kitaoka – Surround biased illumination perception
Read more: Akiyoshi Kitaoka – Surround biased illumination perceptionhttps://x.com/AkiyoshiKitaoka/status/1798705648001327209
The left face appears whitish and the right one blackish, but they are made up of the same luminance.

https://community.wolfram.com/groups/-/m/t/3191015
Illusory staircase Gelb effect
https://www.psy.ritsumei.ac.jp/akitaoka/illgelbe.html










LIGHTING
-
Arto T. – A workflow for creating photorealistic, equirectangular 360° panoramas in ComfyUI using Flux
Read more: Arto T. – A workflow for creating photorealistic, equirectangular 360° panoramas in ComfyUI using Fluxhttps://civitai.com/models/735980/flux-equirectangular-360-panorama
https://civitai.com/models/745010?modelVersionId=833115
The trigger phrase is “equirectangular 360 degree panorama”. I would avoid saying “spherical projection” since that tends to result in non-equirectangular spherical images.
Image resolution should always be a 2:1 aspect ratio. 1024 x 512 or 1408 x 704 work quite well and were used in the training data. 2048 x 1024 also works.
I suggest using a weight of 0.5 – 1.5. If you are having issues with the image generating too flat instead of having the necessary spherical distortion, try increasing the weight above 1, though this could negatively impact small details of the image. For Flux guidance, I recommend a value of about 2.5 for realistic scenes.
8-bit output at the moment


-
Magnific.ai Relight – change the entire lighting of a scene
Read more: Magnific.ai Relight – change the entire lighting of a scene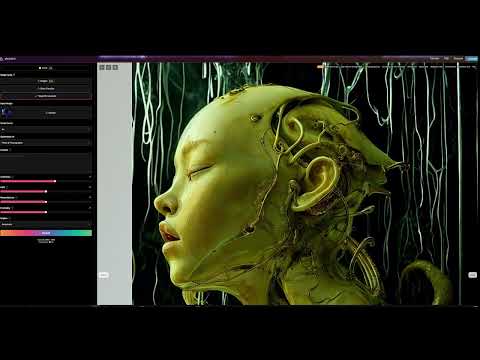
It’s a new Magnific spell that allows you to change the entire lighting of a scene and, optionally, the background with just:
1/ A prompt OR
2/ A reference image OR
3/ A light map (drawing your own lights)https://x.com/javilopen/status/1805274155065176489



-
HDRI shooting and editing by Xuan Prada and Greg Zaal
Read more: HDRI shooting and editing by Xuan Prada and Greg Zaalwww.xuanprada.com/blog/2014/11/3/hdri-shooting
http://blog.gregzaal.com/2016/03/16/make-your-own-hdri/
http://blog.hdrihaven.com/how-to-create-high-quality-hdri/

Shooting checklist
- Full coverage of the scene (fish-eye shots)
- Backplates for look-development (including ground or floor)
- Macbeth chart for white balance
- Grey ball for lighting calibration
- Chrome ball for lighting orientation
- Basic scene measurements
- Material samples
- Individual HDR artificial lighting sources if required
Methodology
(more…) -
Aputure AL-F7 – dimmable Led Video Light, CRI95+, 3200-9500K
Read more: Aputure AL-F7 – dimmable Led Video Light, CRI95+, 3200-9500KHigh CRI of ≥95
256 LEDs with 45° beam angle
3200 to 9500K variable color temperature
1 to 100% Stepless Dimming, 1500 Lux Brightness at 3.3′
LCD Info Screen. Powered by an L-series battery, D-Tap, or USB-C
Because the light has a variable color range of 3200 to 9500K, when the light is set to 5500K (daylight balanced) both sets of LEDs are on at full, providing the maximum brightness from this fixture when compared to using the light at 3200 or 9500K.
The LCD screen provides information on the fixture’s output as well as the charge state of the battery. The screen also indicates whether the adjustment knob is controlling brightness or color temperature. To switch from brightness to CCT or CCT to brightness, just apply a short press to the adjustment knob.
The included cold shoe ball joint adapter enables mounting the light to your camera’s accessory shoe via the 1/4″-20 threaded hole on the fixture. In addition, the bottom of the cold shoe foot features a 3/8″-16 threaded hole, and includes a 3/8″-16 to 1/4″-20 reducing bushing.


-
domeble – Hi-Resolution CGI Backplates and 360° HDRI
Read more: domeble – Hi-Resolution CGI Backplates and 360° HDRIWhen collecting hdri make sure the data supports basic metadata, such as:
- Iso
- Aperture
- Exposure time or shutter time
- Color temperature
- Color space Exposure value (what the sensor receives of the sun intensity in lux)
- 7+ brackets (with 5 or 6 being the perceived balanced exposure)
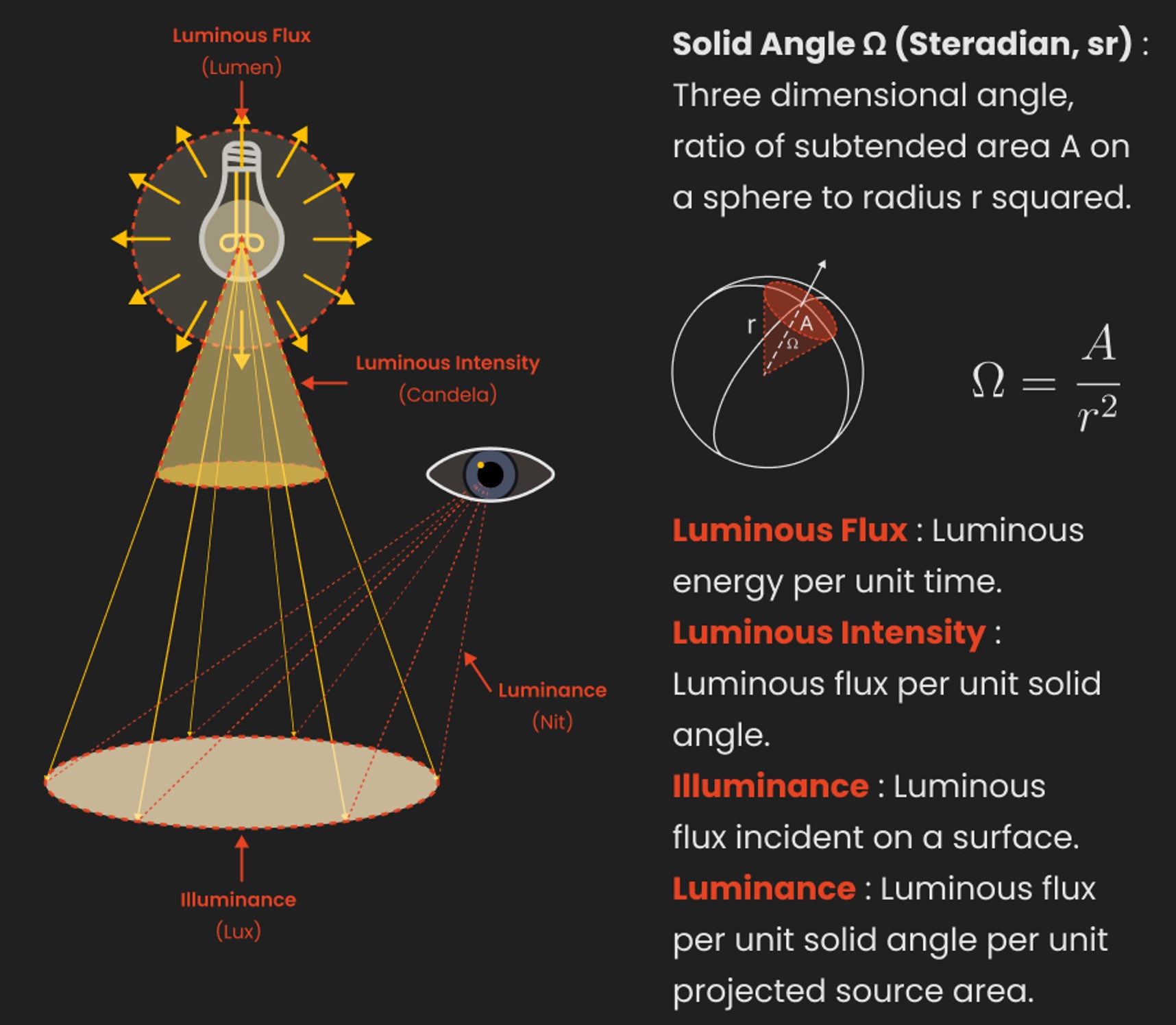
In image processing, computer graphics, and photography, high dynamic range imaging (HDRI or just HDR) is a set of techniques that allow a greater dynamic range of luminances (a Photometry measure of the luminous intensity per unit area of light travelling in a given direction. It describes the amount of light that passes through or is emitted from a particular area, and falls within a given solid angle) between the lightest and darkest areas of an image than standard digital imaging techniques or photographic methods. This wider dynamic range allows HDR images to represent more accurately the wide range of intensity levels found in real scenes ranging from direct sunlight to faint starlight and to the deepest shadows.
The two main sources of HDR imagery are computer renderings and merging of multiple photographs, which in turn are known as low dynamic range (LDR) or standard dynamic range (SDR) images. Tone Mapping (Look-up) techniques, which reduce overall contrast to facilitate display of HDR images on devices with lower dynamic range, can be applied to produce images with preserved or exaggerated local contrast for artistic effect. Photography
In photography, dynamic range is measured in Exposure Values (in photography, exposure value denotes all combinations of camera shutter speed and relative aperture that give the same exposure. The concept was developed in Germany in the 1950s) differences or stops, between the brightest and darkest parts of the image that show detail. An increase of one EV or one stop is a doubling of the amount of light.
The human response to brightness is well approximated by a Steven’s power law, which over a reasonable range is close to logarithmic, as described by the Weber�Fechner law, which is one reason that logarithmic measures of light intensity are often used as well.
HDR is short for High Dynamic Range. It’s a term used to describe an image which contains a greater exposure range than the “black” to “white” that 8 or 16-bit integer formats (JPEG, TIFF, PNG) can describe. Whereas these Low Dynamic Range images (LDR) can hold perhaps 8 to 10 f-stops of image information, HDR images can describe beyond 30 stops and stored in 32 bit images.














COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Types of Film Lights and their efficiency – CRI, Color Temperature and Luminous Efficacy
-
copypastecharacter.com – alphabets, special characters, alt codes and symbols library
-
Alejandro Villabón and Rafał Kaniewski – Recover Highlights With 8-Bit to High Dynamic Range Half Float Copycat – Nuke
-
PixelSham – Introduction to Python 2022
-
Google – Artificial Intelligence free courses
-
AI Search – Find The Best AI Tools & Apps
-
Animation/VFX/Game Industry JOB POSTINGS by Chris Mayne
-
The Public Domain Is Working Again — No Thanks To Disney
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
