Depth of field is the range within which focusing is resolved in a photo.
Aperture has a huge affect on to the depth of field.
Changing the f-stops (f/#) of a lens will change aperture and as such the DOF.
f-stops are a just certain number which is telling you the size of the aperture. That’s how f-stop is related to aperture (and DOF).
If you increase f-stops, it will increase DOF, the area in focus (and decrease the aperture). On the other hand, decreasing the f-stop it will decrease DOF (and increase the aperture).
The red cone in the figure is an angular representation of the resolution of the system. Versus the dotted lines, which indicate the aperture coverage. Where the lines of the two cones intersect defines the total range of the depth of field.
This image explains why the longer the depth of field, the greater the range of clarity.
Size. Mr. White (Harvey Keitel) on the right. Focus. He’s one of the two objects in focus. Lighting. Mr. White is large and in focus and Mr. Pink (Steve Buscemi) is highlighted by a shaft of light. Color. Both are black and white but the read on Mr. White’s shirt now really stands out.
In the retina, photoreceptors, bipolar cells, and horizontal cells work together to process visual information before it reaches the brain. Here’s how each cell type contributes to vision:
About 576 megapixels for the entire field of view.
Consider a view in front of you that is 90 degrees by 90 degrees, like looking through an open window at a scene. The number of pixels would be:
90 degrees * 60 arc-minutes/degree * 1/0.3 * 90 * 60 * 1/0.3 = 324,000,000 pixels (324 megapixels).
At any one moment, you actually do not perceive that many pixels, but your eye moves around the scene to see all the detail you want. But the human eye really sees a larger field of view, close to 180 degrees. Let’s be conservative and use 120 degrees for the field of view. Then we would see:
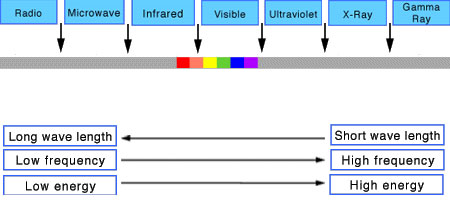
Black-body radiation is the type of electromagnetic radiation within or surrounding a body in thermodynamic equilibrium with its environment, or emitted by a black body (an opaque and non-reflective body) held at constant, uniform temperature. The radiation has a specific spectrum and intensity that depends only on the temperature of the body.
A black-body at room temperature appears black, as most of the energy it radiates is infra-red and cannot be perceived by the human eye. At higher temperatures, black bodies glow with increasing intensity and colors that range from dull red to blindingly brilliant blue-white as the temperature increases.
To measure the contrast ratio you will need a light meter. The process starts with you measuring the main source of light, or the key light.
Get a reading from the brightest area on the face of your subject. Then, measure the area lit by the secondary light, or fill light. To make sense of what you have just measured you have to understand that the information you have just gathered is in F-stops, a measure of light. With each additional F-stop, for example going one stop from f/1.4 to f/2.0, you create a doubling of light. The reverse is also true; moving one stop from f/8.0 to f/5.6 results in a halving of the light.
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.










































































{kind=link}
