


COMPOSITION
-
Composition – cinematography Cheat Sheet
Read more: Composition – cinematography Cheat Sheet
Where is our eye attracted first? Why?
Size. Focus. Lighting. Color.
Size. Mr. White (Harvey Keitel) on the right.
Focus. He’s one of the two objects in focus.
Lighting. Mr. White is large and in focus and Mr. Pink (Steve Buscemi) is highlighted by
a shaft of light.
Color. Both are black and white but the read on Mr. White’s shirt now really stands out.
(more…)
What type of lighting?
















DESIGN
-
The illusion of sex 2009
Read more: The illusion of sex 2009
Richard Russell Harvard University, USA
In the Illusion of Sex, two faces are perceived as male and female.
However, both faces are actually versions of the same androgynous face.
One face was created by increasing the contrast of the androgynous face, while the other face was created by decreasing the contrast. The face with more contrast is perceived as female, while the face with less contrast is perceived as male. The Illusion of Sex demonstrates that contrast is an important cue for perceiving the sex of a face, with greater contrast appearing feminine, and lesser contrast appearing masculine.
Russell, R. (2009) A sex difference in facial pigmentation and its exaggeration by cosmetics. Perception, (38)1211-1219.
-
Arminas Valunas – “Coca-Cola: Wherever you are.”
Read more: Arminas Valunas – “Coca-Cola: Wherever you are.”Arminas created this using Juggernaut Xl model and QR Code Monster SDXL ControlNet.
His pipeline:
Static Images – Forge UI.
Upscaled with Leonardo AI universal upscaler.
Animated with Runway ML and Minimax.
Video upscale – Topaz Video AI.
Composited in Adobe Premiere.
Juggernaut Xl download here:
https://civitai.com/models/133005/juggernaut-xl
QR Code Monster SDXL:
https://civitai.com/models/197247?modelVersionId=221829 -
How to paint a boardgame miniatures
Read more: How to paint a boardgame miniatures
Steps:
- soap wash cleaning
- primer
- base-coat layer (black/white)
- detailing
- washing aka shade (could be done after highlighting)
- highlights aka dry brushing (could be done after washing)
- varnish (gloss/satin/matte)











COLOR
-
Weta Digital – Manuka Raytracer and Gazebo GPU renderers – pipeline
Read more: Weta Digital – Manuka Raytracer and Gazebo GPU renderers – pipelinehttps://jo.dreggn.org/home/2018_manuka.pdf
http://www.fxguide.com/featured/manuka-weta-digitals-new-renderer/

The Manuka rendering architecture has been designed in the spirit of the classic reyes rendering architecture. In its core, reyes is based on stochastic rasterisation of micropolygons, facilitating depth of field, motion blur, high geometric complexity,and programmable shading.
This is commonly achieved with Monte Carlo path tracing, using a paradigm often called shade-on-hit, in which the renderer alternates tracing rays with running shaders on the various ray hits. The shaders take the role of generating the inputs of the local material structure which is then used bypath sampling logic to evaluate contributions and to inform what further rays to cast through the scene.
Over the years, however, the expectations have risen substantially when it comes to image quality. Computing pictures which are indistinguishable from real footage requires accurate simulation of light transport, which is most often performed using some variant of Monte Carlo path tracing. Unfortunately this paradigm requires random memory accesses to the whole scene and does not lend itself well to a rasterisation approach at all.
Manuka is both a uni-directional and bidirectional path tracer and encompasses multiple importance sampling (MIS). Interestingly, and importantly for production character skin work, it is the first major production renderer to incorporate spectral MIS in the form of a new ‘Hero Spectral Sampling’ technique, which was recently published at Eurographics Symposium on Rendering 2014.
Manuka propose a shade-before-hit paradigm in-stead and minimise I/O strain (and some memory costs) on the system, leveraging locality of reference by running pattern generation shaders before we execute light transport simulation by path sampling, “compressing” any bvh structure as needed, and as such also limiting duplication of source data.
The difference with reyes is that instead of baking colors into the geometry like in Reyes, manuka bakes surface closures. This means that light transport is still calculated with path tracing, but all texture lookups etc. are done up-front and baked into the geometry.The main drawback with this method is that geometry has to be tessellated to its highest, stable topology before shading can be evaluated properly. As such, the high cost to first pixel. Even a basic 4 vertices square becomes a much more complex model with this approach.

Manuka use the RenderMan Shading Language (rsl) for programmable shading [Pixar Animation Studios 2015], but we do not invoke rsl shaders when intersecting a ray with a surface (often called shade-on-hit). Instead, we pre-tessellate and pre-shade all the input geometry in the front end of the renderer.
This way, we can efficiently order shading computations to sup-port near-optimal texture locality, vectorisation, and parallelism. This system avoids repeated evaluation of shaders at the same surface point, and presents a minimal amount of memory to be accessed during light transport time. An added benefit is that the acceleration structure for ray tracing (abounding volume hierarchy, bvh) is built once on the final tessellated geometry, which allows us to ray trace more efficiently than multi-level bvhs and avoids costly caching of on-demand tessellated micropolygons and the associated scheduling issues.For the shading reasons above, in terms of AOVs, the studio approach is to succeed at combining complex shading with ray paths in the render rather than pass a multi-pass render to compositing.
For the Spectral Rendering component. The light transport stage is fully spectral, using a continuously sampled wavelength which is traced with each path and used to apply the spectral camera sensitivity of the sensor. This allows for faithfully support any degree of observer metamerism as the camera footage they are intended to match as well as complex materials which require wavelength dependent phenomena such as diffraction, dispersion, interference, iridescence, or chromatic extinction and Rayleigh scattering in participating media.
As opposed to the original reyes paper, we use bilinear interpolation of these bsdf inputs later when evaluating bsdfs per pathv ertex during light transport4. This improves temporal stability of geometry which moves very slowly with respect to the pixel raster
In terms of the pipeline, everything rendered at Weta was already completely interwoven with their deep data pipeline. Manuka very much was written with deep data in mind. Here, Manuka not so much extends the deep capabilities, rather it fully matches the already extremely complex and powerful setup Weta Digital already enjoy with RenderMan. For example, an ape in a scene can be selected, its ID is available and a NUKE artist can then paint in 3D say a hand and part of the way up the neutral posed ape.
We called our system Manuka, as a respectful nod to reyes: we had heard a story froma former ILM employee about how reyes got its name from how fond the early Pixar people were of their lunches at Point Reyes, and decided to name our system after our surrounding natural environment, too. Manuka is a kind of tea tree very common in New Zealand which has very many very small leaves, in analogy to micropolygons ina tree structure for ray tracing. It also happens to be the case that Weta Digital’s main site is on Manuka Street.

-
If a blind person gained sight, could they recognize objects previously touched?
Read more: If a blind person gained sight, could they recognize objects previously touched?Blind people who regain their sight may find themselves in a world they don’t immediately comprehend. “It would be more like a sighted person trying to rely on tactile information,” Moore says.
Learning to see is a developmental process, just like learning language, Prof Cathleen Moore continues. “As far as vision goes, a three-and-a-half year old child is already a well-calibrated system.”
-
Tim Kang – calibrated white light values in sRGB color space
Read more: Tim Kang – calibrated white light values in sRGB color space8bit sRGB encoded
2000K 255 139 22
2700K 255 172 89
3000K 255 184 109
3200K 255 190 122
4000K 255 211 165
4300K 255 219 178
D50 255 235 205
D55 255 243 224
D5600 255 244 227
D6000 255 249 240
D65 255 255 255
D10000 202 221 255
D20000 166 196 2558bit Rec709 Gamma 2.4
2000K 255 145 34
2700K 255 177 97
3000K 255 187 117
3200K 255 193 129
4000K 255 214 170
4300K 255 221 182
D50 255 236 208
D55 255 243 226
D5600 255 245 229
D6000 255 250 241
D65 255 255 255
D10000 204 222 255
D20000 170 199 2558bit Display P3 encoded
2000K 255 154 63
2700K 255 185 109
3000K 255 195 127
3200K 255 201 138
4000K 255 219 176
4300K 255 225 187
D50 255 239 212
D55 255 245 228
D5600 255 246 231
D6000 255 251 242
D65 255 255 255
D10000 208 223 255
D20000 175 199 25510bit Rec2020 PQ (100 nits)
2000K 520 435 273
2700K 520 466 358
3000K 520 475 384
3200K 520 480 399
4000K 520 495 446
4300K 520 500 458
D50 520 510 482
D55 520 514 497
D5600 520 514 500
D6000 520 517 509
D65 520 520 520
D10000 479 489 520
D20000 448 464 520
-
What light is best to illuminate gems for resale
Read more: What light is best to illuminate gems for resalewww.palagems.com/gem-lighting2
Artificial light sources, not unlike the diverse phases of natural light, vary considerably in their properties. As a result, some lamps render an object’s color better than others do.
The most important criterion for assessing the color-rendering ability of any lamp is its spectral power distribution curve.
Natural daylight varies too much in strength and spectral composition to be taken seriously as a lighting standard for grading and dealing colored stones. For anything to be a standard, it must be constant in its properties, which natural light is not.
For dealers in particular to make the transition from natural light to an artificial light source, that source must offer:
1- A degree of illuminance at least as strong as the common phases of natural daylight.
2- Spectral properties identical or comparable to a phase of natural daylight.A source combining these two things makes gems appear much the same as when viewed under a given phase of natural light. From the viewpoint of many dealers, this corresponds to a naturalappearance.
The 6000° Kelvin xenon short-arc lamp appears closest to meeting the criteria for a standard light source. Besides the strong illuminance this lamp affords, its spectrum is very similar to CIE standard illuminants of similar color temperature.

















LIGHTING
-
Black Body color aka the Planckian Locus curve for white point eye perception
Read more: Black Body color aka the Planckian Locus curve for white point eye perceptionhttp://en.wikipedia.org/wiki/Black-body_radiation

Black-body radiation is the type of electromagnetic radiation within or surrounding a body in thermodynamic equilibrium with its environment, or emitted by a black body (an opaque and non-reflective body) held at constant, uniform temperature. The radiation has a specific spectrum and intensity that depends only on the temperature of the body.
A black-body at room temperature appears black, as most of the energy it radiates is infra-red and cannot be perceived by the human eye. At higher temperatures, black bodies glow with increasing intensity and colors that range from dull red to blindingly brilliant blue-white as the temperature increases.
The Black Body Ultraviolet Catastrophe Experiment

In photography, color temperature describes the spectrum of light which is radiated from a “blackbody” with that surface temperature. A blackbody is an object which absorbs all incident light — neither reflecting it nor allowing it to pass through.
The Sun closely approximates a black-body radiator. Another rough analogue of blackbody radiation in our day to day experience might be in heating a metal or stone: these are said to become “red hot” when they attain one temperature, and then “white hot” for even higher temperatures. Similarly, black bodies at different temperatures also have varying color temperatures of “white light.”
Despite its name, light which may appear white does not necessarily contain an even distribution of colors across the visible spectrum.
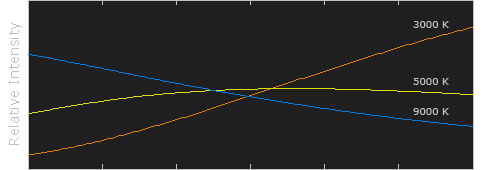
Although planets and stars are neither in thermal equilibrium with their surroundings nor perfect black bodies, black-body radiation is used as a first approximation for the energy they emit. Black holes are near-perfect black bodies, and it is believed that they emit black-body radiation (called Hawking radiation), with a temperature that depends on the mass of the hole.
-
Free HDRI libraries
Read more: Free HDRI librariesnoahwitchell.com
http://www.noahwitchell.com/freebieslocationtextures.com
https://locationtextures.com/panoramas/maxroz.com
https://www.maxroz.com/hdri/listHDRI Haven
https://hdrihaven.com/Poly Haven
https://polyhaven.com/hdrisDomeble
https://www.domeble.com/IHDRI
https://www.ihdri.com/HDRMaps
https://hdrmaps.com/NoEmotionHdrs.net
http://noemotionhdrs.net/hdrday.htmlOpenFootage.net
https://www.openfootage.net/hdri-panorama/HDRI-hub
https://www.hdri-hub.com/hdrishop/hdri.zwischendrin
https://www.zwischendrin.com/en/browse/hdriLonger list here:
https://cgtricks.com/list-sites-free-hdri/

-
Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental process
Read more: Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental processhttps://www.chrbutler.com/understanding-the-eye-mind-connection
The intricate relationship between the eyes and the brain, often termed the eye-mind connection, reveals that vision is predominantly a cognitive process. This understanding has profound implications for fields such as design, where capturing and maintaining attention is paramount. This essay delves into the nuances of visual perception, the brain’s role in interpreting visual data, and how this knowledge can be applied to effective design strategies.
This cognitive aspect of vision is evident in phenomena such as optical illusions, where the brain interprets visual information in a way that contradicts physical reality. These illusions underscore that what we “see” is not merely a direct recording of the external world but a constructed experience shaped by cognitive processes.
Understanding the cognitive nature of vision is crucial for effective design. Designers must consider how the brain processes visual information to create compelling and engaging visuals. This involves several key principles:
- Attention and Engagement
- Visual Hierarchy
- Cognitive Load Management
- Context and Meaning
-
9 Best Hacks to Make a Cinematic Video with Any Camera
Read more: 9 Best Hacks to Make a Cinematic Video with Any Camerahttps://www.flexclip.com/learn/cinematic-video.html
- Frame Your Shots to Create Depth
- Create Shallow Depth of Field
- Avoid Shaky Footage and Use Flexible Camera Movements
- Properly Use Slow Motion
- Use Cinematic Lighting Techniques
- Apply Color Grading
- Use Cinematic Music and SFX
- Add Cinematic Fonts and Text Effects
- Create the Cinematic Bar at the Top and the Bottom

-
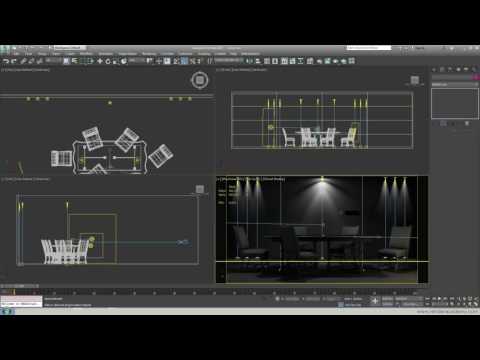
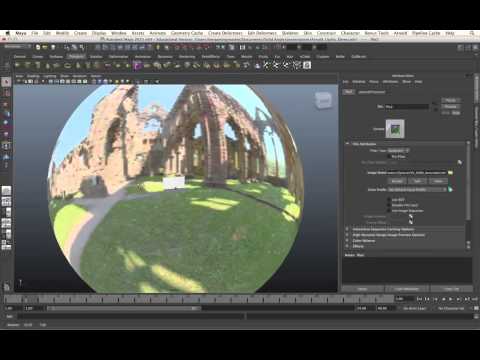
IES Light Profiles and editing software
Read more: IES Light Profiles and editing softwarehttp://www.derekjenson.com/3d-blog/ies-light-profiles
https://ieslibrary.com/en/browse#ies
https://leomoon.com/store/shaders/ies-lights-pack
https://docs.arnoldrenderer.com/display/a5afmug/ai+photometric+light
IES profiles are useful for creating life-like lighting, as they can represent the physical distribution of light from any light source.
The IES format was created by the Illumination Engineering Society, and most lighting manufacturers provide IES profile for the lights they manufacture.











COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
What’s the Difference Between Ray Casting, Ray Tracing, Path Tracing and Rasterization? Physical light tracing…
-
Types of Film Lights and their efficiency – CRI, Color Temperature and Luminous Efficacy
-
Emmanuel Tsekleves – Writing Research Papers
-
Kling 1.6 and competitors – advanced tests and comparisons
-
Photography basics: Color Temperature and White Balance
-
NVidia – High-Fidelity 3D Mesh Generation at Scale with Meshtron
-
SourceTree vs Github Desktop – Which one to use
-
MiniMax-Remover – Taming Bad Noise Helps Video Object Removal Rotoscoping
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
