


COMPOSITION
-
Photography basics: Depth of Field and composition
Read more: Photography basics: Depth of Field and compositionDepth of field is the range within which focusing is resolved in a photo.
Aperture has a huge affect on to the depth of field.
Changing the f-stops (f/#) of a lens will change aperture and as such the DOF.
f-stops are a just certain number which is telling you the size of the aperture. That’s how f-stop is related to aperture (and DOF).
If you increase f-stops, it will increase DOF, the area in focus (and decrease the aperture). On the other hand, decreasing the f-stop it will decrease DOF (and increase the aperture).
The red cone in the figure is an angular representation of the resolution of the system. Versus the dotted lines, which indicate the aperture coverage. Where the lines of the two cones intersect defines the total range of the depth of field.
This image explains why the longer the depth of field, the greater the range of clarity.

-
Composition – These are the basic lighting techniques you need to know for photography and film
Read more: Composition – These are the basic lighting techniques you need to know for photography and film
http://www.diyphotography.net/basic-lighting-techniques-need-know-photography-film/
Amongst the basic techniques, there’s…
1- Side lighting – Literally how it sounds, lighting a subject from the side when they’re faced toward you
2- Rembrandt lighting – Here the light is at around 45 degrees over from the front of the subject, raised and pointing down at 45 degrees
3- Back lighting – Again, how it sounds, lighting a subject from behind. This can help to add drama with silouettes
4- Rim lighting – This produces a light glowing outline around your subject
5- Key light – The main light source, and it’s not necessarily always the brightest light source
6- Fill light – This is used to fill in the shadows and provide detail that would otherwise be blackness
7- Cross lighting – Using two lights placed opposite from each other to light two subjects




















DESIGN
-
Magic Carpet by artist Daniel Wurtzel
Read more: Magic Carpet by artist Daniel Wurtzelhttps://www.youtube.com/watch?v=1C_40B9m4tI http://www.danielwurtzel.com














COLOR
-
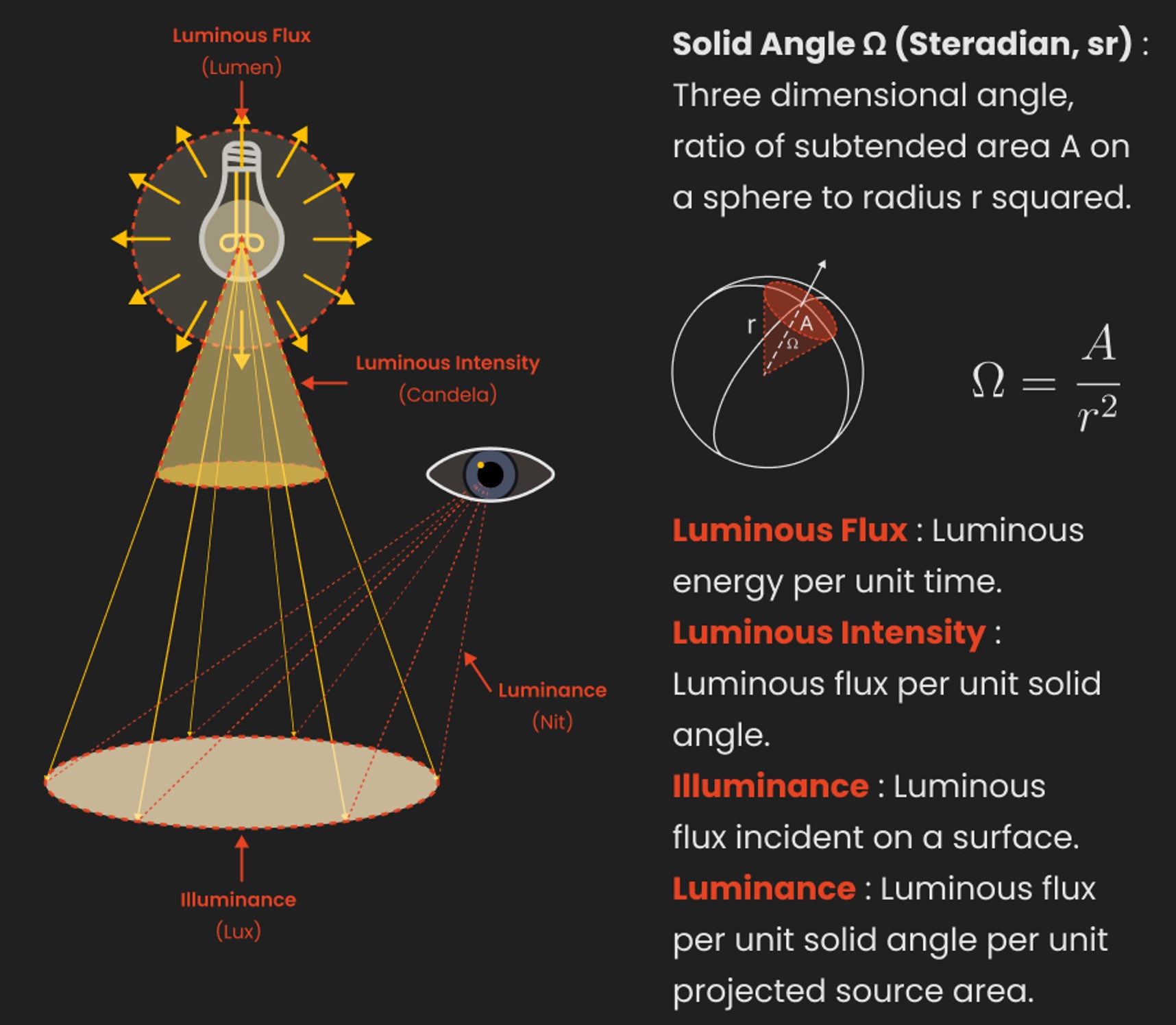
Photography basics: Lumens vs Candelas (candle) vs Lux vs FootCandle vs Watts vs Irradiance vs Illuminance
Read more: Photography basics: Lumens vs Candelas (candle) vs Lux vs FootCandle vs Watts vs Irradiance vs Illuminancehttps://www.translatorscafe.com/unit-converter/en-US/illumination/1-11/

The power output of a light source is measured using the unit of watts W. This is a direct measure to calculate how much power the light is going to drain from your socket and it is not relatable to the light brightness itself.
The amount of energy emitted from it per second. That energy comes out in a form of photons which we can crudely represent with rays of light coming out of the source. The higher the power the more rays emitted from the source in a unit of time.
Not all energy emitted is visible to the human eye, so we often rely on photometric measurements, which takes in account the sensitivity of human eye to different wavelenghts


Details in the post
(more…) -
Types of Film Lights and their efficiency – CRI, Color Temperature and Luminous Efficacy
Read more: Types of Film Lights and their efficiency – CRI, Color Temperature and Luminous Efficacynofilmschool.com/types-of-film-lights
“Not every light performs the same way. Lights and lighting are tricky to handle. You have to plan for every circumstance. But the good news is, lighting can be adjusted. Let’s look at different factors that affect lighting in every scene you shoot. “
Use CRI, Luminous Efficacy and color temperature controls to match your needs.
Color Temperature
Color temperature describes the “color” of white light by a light source radiated by a perfect black body at a given temperature measured in degrees Kelvinhttps://www.pixelsham.com/2019/10/18/color-temperature/
CRI
“The Color Rendering Index is a measurement of how faithfully a light source reveals the colors of whatever it illuminates, it describes the ability of a light source to reveal the color of an object, as compared to the color a natural light source would provide. The highest possible CRI is 100. A CRI of 100 generally refers to a perfect black body, like a tungsten light source or the sun. “https://www.studiobinder.com/blog/what-is-color-rendering-index
(more…) -
The Forbidden colors – Red-Green & Blue-Yellow: The Stunning Colors You Can’t See
Read more: The Forbidden colors – Red-Green & Blue-Yellow: The Stunning Colors You Can’t Seewww.livescience.com/17948-red-green-blue-yellow-stunning-colors.html

While the human eye has red, green, and blue-sensing cones, those cones are cross-wired in the retina to produce a luminance channel plus a red-green and a blue-yellow channel, and it’s data in that color space (known technically as “LAB”) that goes to the brain. That’s why we can’t perceive a reddish-green or a yellowish-blue, whereas such colors can be represented in the RGB color space used by digital cameras.
https://en.rockcontent.com/blog/the-use-of-yellow-in-data-design
The back of the retina is covered in light-sensitive neurons known as cone cells and rod cells. There are three types of cone cells, each sensitive to different ranges of light. These ranges overlap, but for convenience the cones are referred to as blue (short-wavelength), green (medium-wavelength), and red (long-wavelength). The rod cells are primarily used in low-light situations, so we’ll ignore those for now.
When light enters the eye and hits the cone cells, the cones get excited and send signals to the brain through the visual cortex. Different wavelengths of light excite different combinations of cones to varying levels, which generates our perception of color. You can see that the red cones are most sensitive to light, and the blue cones are least sensitive. The sensitivity of green and red cones overlaps for most of the visible spectrum.

Here’s how your brain takes the signals of light intensity from the cones and turns it into color information. To see red or green, your brain finds the difference between the levels of excitement in your red and green cones. This is the red-green channel.
To get “brightness,” your brain combines the excitement of your red and green cones. This creates the luminance, or black-white, channel. To see yellow or blue, your brain then finds the difference between this luminance signal and the excitement of your blue cones. This is the yellow-blue channel.
From the calculations made in the brain along those three channels, we get four basic colors: blue, green, yellow, and red. Seeing blue is what you experience when low-wavelength light excites the blue cones more than the green and red.
Seeing green happens when light excites the green cones more than the red cones. Seeing red happens when only the red cones are excited by high-wavelength light.
Here’s where it gets interesting. Seeing yellow is what happens when BOTH the green AND red cones are highly excited near their peak sensitivity. This is the biggest collective excitement that your cones ever have, aside from seeing pure white.
Notice that yellow occurs at peak intensity in the graph to the right. Further, the lens and cornea of the eye happen to block shorter wavelengths, reducing sensitivity to blue and violet light.
-
About color: What is a LUT
Read more: About color: What is a LUThttp://www.lightillusion.com/luts.html
https://www.shutterstock.com/blog/how-use-luts-color-grading
A LUT (Lookup Table) is essentially the modifier between two images, the original image and the displayed image, based on a mathematical formula. Basically conversion matrices of different complexities. There are different types of LUTS – viewing, transform, calibration, 1D and 3D.


-
colorhunt.co
Read more: colorhunt.coColor Hunt is a free and open platform for color inspiration with thousands of trendy hand-picked color palettes.









LIGHTING
-
9 Best Hacks to Make a Cinematic Video with Any Camera
Read more: 9 Best Hacks to Make a Cinematic Video with Any Camerahttps://www.flexclip.com/learn/cinematic-video.html
- Frame Your Shots to Create Depth
- Create Shallow Depth of Field
- Avoid Shaky Footage and Use Flexible Camera Movements
- Properly Use Slow Motion
- Use Cinematic Lighting Techniques
- Apply Color Grading
- Use Cinematic Music and SFX
- Add Cinematic Fonts and Text Effects
- Create the Cinematic Bar at the Top and the Bottom

-
What light is best to illuminate gems for resale
Read more: What light is best to illuminate gems for resalewww.palagems.com/gem-lighting2
Artificial light sources, not unlike the diverse phases of natural light, vary considerably in their properties. As a result, some lamps render an object’s color better than others do.
The most important criterion for assessing the color-rendering ability of any lamp is its spectral power distribution curve.
Natural daylight varies too much in strength and spectral composition to be taken seriously as a lighting standard for grading and dealing colored stones. For anything to be a standard, it must be constant in its properties, which natural light is not.
For dealers in particular to make the transition from natural light to an artificial light source, that source must offer:
1- A degree of illuminance at least as strong as the common phases of natural daylight.
2- Spectral properties identical or comparable to a phase of natural daylight.A source combining these two things makes gems appear much the same as when viewed under a given phase of natural light. From the viewpoint of many dealers, this corresponds to a naturalappearance.
The 6000° Kelvin xenon short-arc lamp appears closest to meeting the criteria for a standard light source. Besides the strong illuminance this lamp affords, its spectrum is very similar to CIE standard illuminants of similar color temperature.


-
Ethan Roffler interviews CG Supervisor Daniele Tosti
Read more: Ethan Roffler interviews CG Supervisor Daniele TostiEthan Roffler
I recently had the honor of interviewing this VFX genius and gained great insight into what it takes to work in the entertainment industry. Keep in mind, these questions are coming from an artist’s perspective but can be applied to any creative individual looking for some wisdom from a professional. So grab a drink, sit back, and enjoy this fun and insightful conversation.
Ethan
To start, I just wanted to say thank you so much for taking the time for this interview!Daniele
My pleasure.
When I started my career I struggled to find help. Even people in the industry at the time were not that helpful. Because of that, I decided very early on that I was going to do exactly the opposite. I spend most of my weekends talking or helping students. ;)Ethan
(more…)
That’s awesome! I have also come across the same struggle! Just a heads up, this will probably be the most informal interview you’ll ever have haha! Okay, so let’s start with a small introduction! -
Composition – cinematography Cheat Sheet
Read more: Composition – cinematography Cheat Sheet
Where is our eye attracted first? Why?
Size. Focus. Lighting. Color.
Size. Mr. White (Harvey Keitel) on the right.
Focus. He’s one of the two objects in focus.
Lighting. Mr. White is large and in focus and Mr. Pink (Steve Buscemi) is highlighted by
a shaft of light.
Color. Both are black and white but the read on Mr. White’s shirt now really stands out.
(more…)
What type of lighting?









COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Eddie Yoon – There’s a big misconception about AI creative
-
ComfyDock – The Easiest (Free) Way to Safely Run ComfyUI Sessions in a Boxed Container
-
The Public Domain Is Working Again — No Thanks To Disney
-
Black Forest Labs released FLUX.1 Kontext
-
Most common ways to smooth 3D prints
-
How does Stable Diffusion work?
-
AI Search – Find The Best AI Tools & Apps
-
Eyeline Labs VChain – Chain-of-Visual-Thought for Reasoning in Video Generation for better AI physics
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
