


COMPOSITION










DESIGN
COLOR
-
Weta Digital – Manuka Raytracer and Gazebo GPU renderers – pipeline
Read more: Weta Digital – Manuka Raytracer and Gazebo GPU renderers – pipelinehttps://jo.dreggn.org/home/2018_manuka.pdf
http://www.fxguide.com/featured/manuka-weta-digitals-new-renderer/

The Manuka rendering architecture has been designed in the spirit of the classic reyes rendering architecture. In its core, reyes is based on stochastic rasterisation of micropolygons, facilitating depth of field, motion blur, high geometric complexity,and programmable shading.
This is commonly achieved with Monte Carlo path tracing, using a paradigm often called shade-on-hit, in which the renderer alternates tracing rays with running shaders on the various ray hits. The shaders take the role of generating the inputs of the local material structure which is then used bypath sampling logic to evaluate contributions and to inform what further rays to cast through the scene.
Over the years, however, the expectations have risen substantially when it comes to image quality. Computing pictures which are indistinguishable from real footage requires accurate simulation of light transport, which is most often performed using some variant of Monte Carlo path tracing. Unfortunately this paradigm requires random memory accesses to the whole scene and does not lend itself well to a rasterisation approach at all.
Manuka is both a uni-directional and bidirectional path tracer and encompasses multiple importance sampling (MIS). Interestingly, and importantly for production character skin work, it is the first major production renderer to incorporate spectral MIS in the form of a new ‘Hero Spectral Sampling’ technique, which was recently published at Eurographics Symposium on Rendering 2014.
Manuka propose a shade-before-hit paradigm in-stead and minimise I/O strain (and some memory costs) on the system, leveraging locality of reference by running pattern generation shaders before we execute light transport simulation by path sampling, “compressing” any bvh structure as needed, and as such also limiting duplication of source data.
The difference with reyes is that instead of baking colors into the geometry like in Reyes, manuka bakes surface closures. This means that light transport is still calculated with path tracing, but all texture lookups etc. are done up-front and baked into the geometry.The main drawback with this method is that geometry has to be tessellated to its highest, stable topology before shading can be evaluated properly. As such, the high cost to first pixel. Even a basic 4 vertices square becomes a much more complex model with this approach.

Manuka use the RenderMan Shading Language (rsl) for programmable shading [Pixar Animation Studios 2015], but we do not invoke rsl shaders when intersecting a ray with a surface (often called shade-on-hit). Instead, we pre-tessellate and pre-shade all the input geometry in the front end of the renderer.
This way, we can efficiently order shading computations to sup-port near-optimal texture locality, vectorisation, and parallelism. This system avoids repeated evaluation of shaders at the same surface point, and presents a minimal amount of memory to be accessed during light transport time. An added benefit is that the acceleration structure for ray tracing (abounding volume hierarchy, bvh) is built once on the final tessellated geometry, which allows us to ray trace more efficiently than multi-level bvhs and avoids costly caching of on-demand tessellated micropolygons and the associated scheduling issues.For the shading reasons above, in terms of AOVs, the studio approach is to succeed at combining complex shading with ray paths in the render rather than pass a multi-pass render to compositing.
For the Spectral Rendering component. The light transport stage is fully spectral, using a continuously sampled wavelength which is traced with each path and used to apply the spectral camera sensitivity of the sensor. This allows for faithfully support any degree of observer metamerism as the camera footage they are intended to match as well as complex materials which require wavelength dependent phenomena such as diffraction, dispersion, interference, iridescence, or chromatic extinction and Rayleigh scattering in participating media.
As opposed to the original reyes paper, we use bilinear interpolation of these bsdf inputs later when evaluating bsdfs per pathv ertex during light transport4. This improves temporal stability of geometry which moves very slowly with respect to the pixel raster
In terms of the pipeline, everything rendered at Weta was already completely interwoven with their deep data pipeline. Manuka very much was written with deep data in mind. Here, Manuka not so much extends the deep capabilities, rather it fully matches the already extremely complex and powerful setup Weta Digital already enjoy with RenderMan. For example, an ape in a scene can be selected, its ID is available and a NUKE artist can then paint in 3D say a hand and part of the way up the neutral posed ape.
We called our system Manuka, as a respectful nod to reyes: we had heard a story froma former ILM employee about how reyes got its name from how fond the early Pixar people were of their lunches at Point Reyes, and decided to name our system after our surrounding natural environment, too. Manuka is a kind of tea tree very common in New Zealand which has very many very small leaves, in analogy to micropolygons ina tree structure for ray tracing. It also happens to be the case that Weta Digital’s main site is on Manuka Street.

-
OpenColorIO standard
Read more: OpenColorIO standardhttps://www.provideocoalition.com/color-management-part-11-introducing-opencolorio/
OpenColorIO (OCIO) is a new open source project from Sony Imageworks.
Based on development started in 2003, OCIO enables color transforms and image display to be handled in a consistent manner across multiple graphics applications. Unlike other color management solutions, OCIO is geared towards motion-picture post production, with an emphasis on visual effects and animation color pipelines.

-
Photography basics: Color Temperature and White Balance
Read more: Photography basics: Color Temperature and White Balance

Color Temperature of a light source describes the spectrum of light which is radiated from a theoretical “blackbody” (an ideal physical body that absorbs all radiation and incident light – neither reflecting it nor allowing it to pass through) with a given surface temperature.
https://en.wikipedia.org/wiki/Color_temperature
Or. Most simply it is a method of describing the color characteristics of light through a numerical value that corresponds to the color emitted by a light source, measured in degrees of Kelvin (K) on a scale from 1,000 to 10,000.
More accurately. The color temperature of a light source is the temperature of an ideal backbody that radiates light of comparable hue to that of the light source.
(more…) -
Is it possible to get a dark yellow
Read more: Is it possible to get a dark yellowhttps://www.patreon.com/posts/102660674
https://www.linkedin.com/posts/stephenwestland_here-is-a-post-about-the-dark-yellow-problem-activity-7187131643764092929-7uCL



-
Colormaxxing – What if I told you that rgb(255, 0, 0) is not actually the reddest red you can have in your browser?
Read more: Colormaxxing – What if I told you that rgb(255, 0, 0) is not actually the reddest red you can have in your browser?https://karuna.dev/colormaxxing
https://webkit.org/blog-files/color-gamut/comparison.html
https://oklch.com/#70,0.1,197,100

-
What is a Gamut or Color Space and why do I need to know about CIE
Read more: What is a Gamut or Color Space and why do I need to know about CIE

http://www.xdcam-user.com/2014/05/what-is-a-gamut-or-color-space-and-why-do-i-need-to-know-about-it/
In video terms gamut is normally related to as the full range of colours and brightness that can be either captured or displayed.
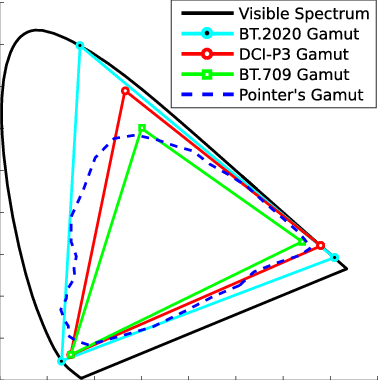
Generally speaking all color gamuts recommendations are trying to define a reasonable level of color representation based on available technology and hardware. REC-601 represents the old TVs. REC-709 is currently the most distributed solution. P3 is mainly available in movie theaters and is now being adopted in some of the best new 4K HDR TVs. Rec2020 (a wider space than P3 that improves on visibke color representation) and ACES (the full coverage of visible color) are other common standards which see major hardware development these days.
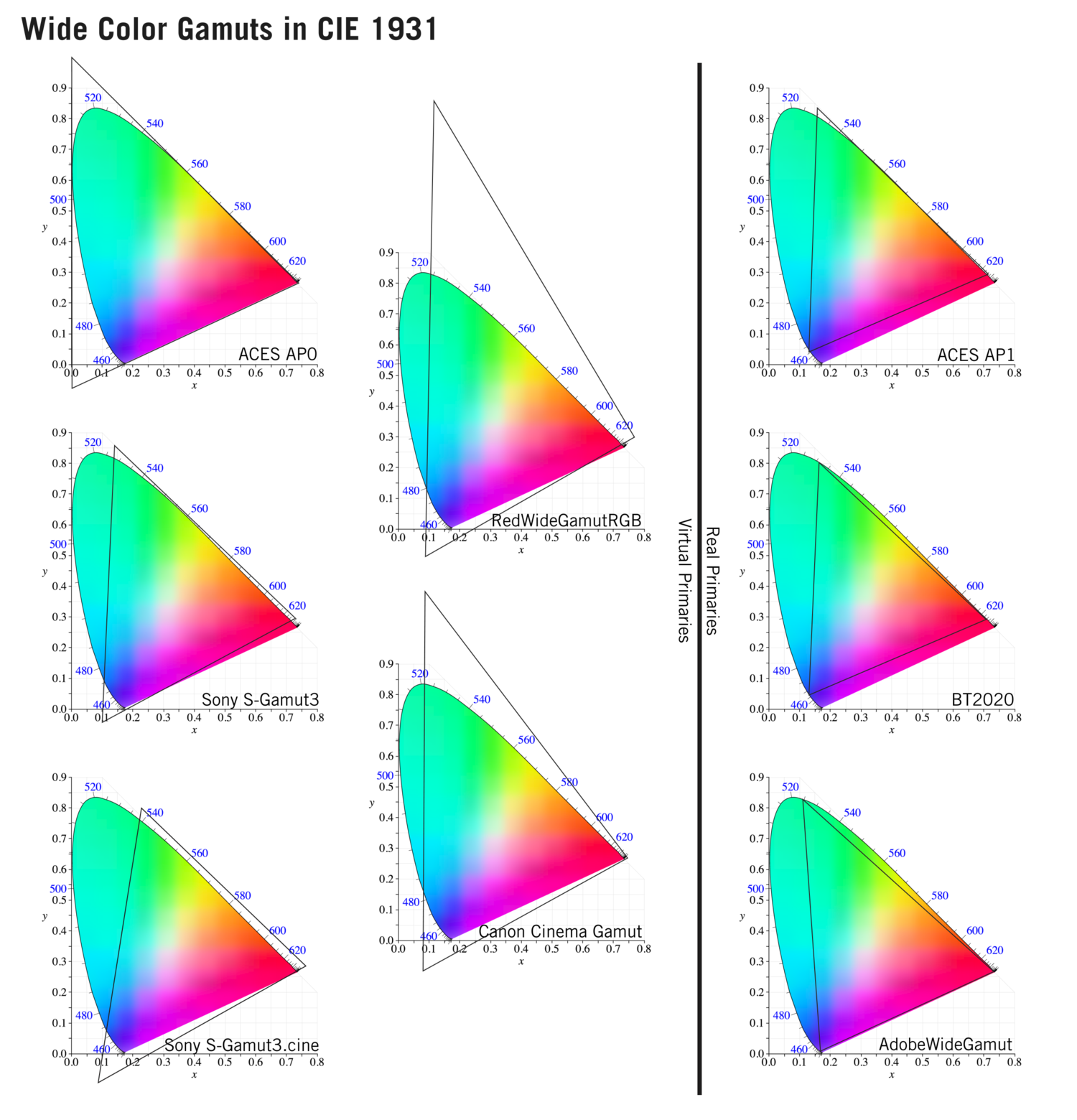
To compare and visualize different solution (across video and printing solutions), most developers use the CIE color model chart as a reference.
The CIE color model is a color space model created by the International Commission on Illumination known as the Commission Internationale de l’Elcairage (CIE) in 1931. It is also known as the CIE XYZ color space or the CIE 1931 XYZ color space.
This chart represents the first defined quantitative link between distributions of wavelengths in the electromagnetic visible spectrum, and physiologically perceived colors in human color vision. Or basically, the range of color a typical human eye can perceive through visible light.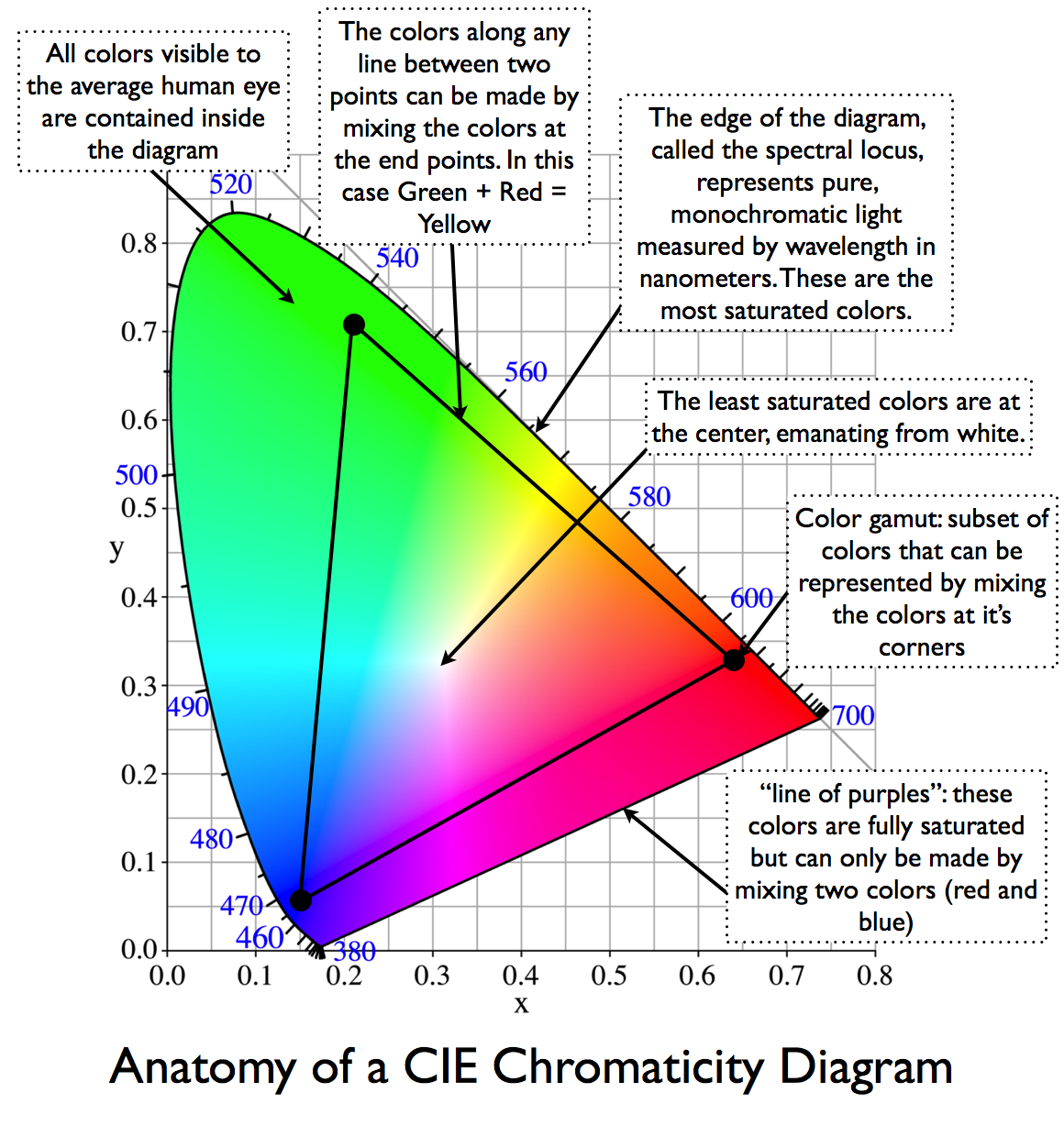
Note that while the human perception is quite wide, and generally speaking biased towards greens (we are apes after all), the amount of colors available through nature, generated through light reflection, tend to be a much smaller section. This is defined by the Pointer’s Chart.

In short. Color gamut is a representation of color coverage, used to describe data stored in images against available hardware and viewer technologies.
Camera color encoding from
https://www.slideshare.net/hpduiker/acescg-a-common-color-encoding-for-visual-effects-applications
CIE 1976
http://bernardsmith.eu/computatrum/scan_and_restore_archive_and_print/scanning/
https://store.yujiintl.com/blogs/high-cri-led/understanding-cie1931-and-cie-1976
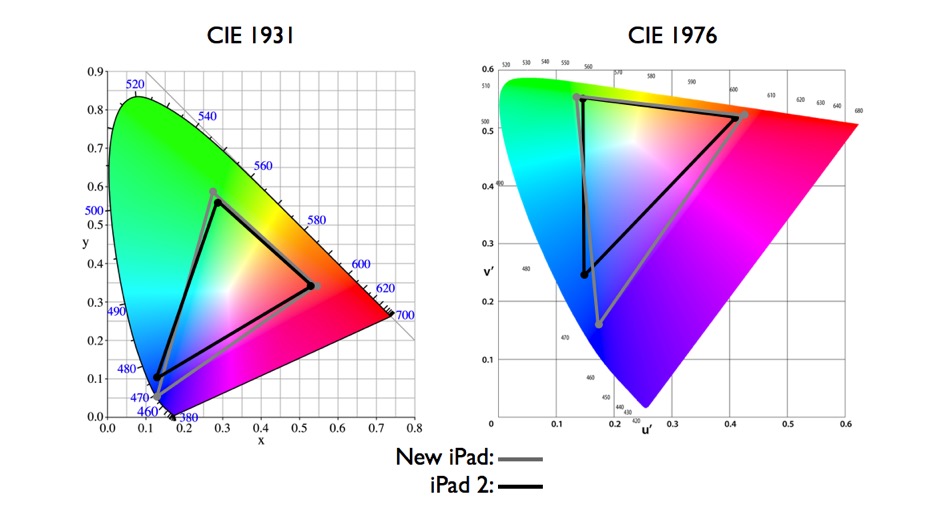
The CIE 1931 standard has been replaced by a CIE 1976 standard. Below we can see the significance of this.
People have observed that the biggest issue with CIE 1931 is the lack of uniformity with chromaticity, the three dimension color space in rectangular coordinates is not visually uniformed.
The CIE 1976 (also called CIELUV) was created by the CIE in 1976. It was put forward in an attempt to provide a more uniform color spacing than CIE 1931 for colors at approximately the same luminance
The CIE 1976 standard colour space is more linear and variations in perceived colour between different people has also been reduced. The disproportionately large green-turquoise area in CIE 1931, which cannot be generated with existing computer screens, has been reduced.
If we move from CIE 1931 to the CIE 1976 standard colour space we can see that the improvements made in the gamut for the “new” iPad screen (as compared to the “old” iPad 2) are more evident in the CIE 1976 colour space than in the CIE 1931 colour space, particularly in the blues from aqua to deep blue.
https://dot-color.com/2012/08/14/color-space-confusion/
Despite its age, CIE 1931, named for the year of its adoption, remains a well-worn and familiar shorthand throughout the display industry. CIE 1931 is the primary language of customers. When a customer says that their current display “can do 72% of NTSC,” they implicitly mean 72% of NTSC 1953 color gamut as mapped against CIE 1931.
-
mmColorTarget – Nuke Gizmo for color matching a MacBeth chart
Read more: mmColorTarget – Nuke Gizmo for color matching a MacBeth charthttps://www.marcomeyer-vfx.de/posts/2014-04-11-mmcolortarget-nuke-gizmo/
https://www.marcomeyer-vfx.de/posts/mmcolortarget-nuke-gizmo/
https://vimeo.com/9.1652466e+07
https://www.nukepedia.com/gizmos/colour/mmcolortarget
-
PBR Color Reference List for Materials – by Grzegorz Baran
Read more: PBR Color Reference List for Materials – by Grzegorz Baran
“The list should be helpful for every material artist who work on PBR materials as it contains over 200 color values measured with PCE-RGB2 1002 Color Spectrometer device and presented in linear and sRGB (2.2) gamma space.
All color values, HUE and Saturation in this list come from measurements taken with PCE-RGB2 1002 Color Spectrometer device and are presented in linear and sRGB (2.2) gamma space (more info at the end of this video) I calculated Relative Luminance and Luminance values based on captured color using my own equation which takes color based luminance perception into consideration. Bare in mind that there is no ‘one’ color per substance as nothing in nature is even 100% uniform and any value in +/-10% range from these should be considered as correct one. Therefore this list should be always considered as a color reference for material’s albedos, not ulitimate and absolute truth.“








LIGHTING
-
Rec-2020 – TVs new color gamut standard used by Dolby Vision?
Read more: Rec-2020 – TVs new color gamut standard used by Dolby Vision?https://www.hdrsoft.com/resources/dri.html#bit-depth

The dynamic range is a ratio between the maximum and minimum values of a physical measurement. Its definition depends on what the dynamic range refers to.
For a scene: Dynamic range is the ratio between the brightest and darkest parts of the scene.
For a camera: Dynamic range is the ratio of saturation to noise. More specifically, the ratio of the intensity that just saturates the camera to the intensity that just lifts the camera response one standard deviation above camera noise.
For a display: Dynamic range is the ratio between the maximum and minimum intensities emitted from the screen.
The Dynamic Range of real-world scenes can be quite high — ratios of 100,000:1 are common in the natural world. An HDR (High Dynamic Range) image stores pixel values that span the whole tonal range of real-world scenes. Therefore, an HDR image is encoded in a format that allows the largest range of values, e.g. floating-point values stored with 32 bits per color channel. Another characteristics of an HDR image is that it stores linear values. This means that the value of a pixel from an HDR image is proportional to the amount of light measured by the camera.
For TVs HDR is great, but it’s not the only new TV feature worth discussing.
(more…) -
Debayer – A free command line tool to convert camera raw images into scene-linear exr
Read more: Debayer – A free command line tool to convert camera raw images into scene-linear exr
https://github.com/jedypod/debayer
The only required dependency is oiiotool. However other “debayer engines” are also supported.
- OpenImageIO – oiiotool is used for converting debayered tif images to exr.
- Debayer Engines
- RawTherapee – Powerful raw development software used to decode raw images. High quality, good selection of debayer algorithms, and more advanced raw processing like chromatic aberration removal.
- LibRaw – dcraw_emu commandline utility included with LibRaw. Optional alternative for debayer. Simple, fast and effective.
- Darktable – Uses darktable-cli plus an xmp config to process.
- vkdt – uses vkdt-cli to debayer. Pretty experimental still. Uses Vulkan for image processing. Stupidly fast. Pretty limited.
-
Photography basics: Why Use a (MacBeth) Color Chart?
Read more: Photography basics: Why Use a (MacBeth) Color Chart?Start here: https://www.pixelsham.com/2013/05/09/gretagmacbeth-color-checker-numeric-values/
https://www.studiobinder.com/blog/what-is-a-color-checker-tool/



In LightRoom

in Final Cut

in Nuke
Note: In Foundry’s Nuke, the software will map 18% gray to whatever your center f/stop is set to in the viewer settings (f/8 by default… change that to EV by following the instructions below).
You can experiment with this by attaching an Exposure node to a Constant set to 0.18, setting your viewer read-out to Spotmeter, and adjusting the stops in the node up and down. You will see that a full stop up or down will give you the respective next value on the aperture scale (f8, f11, f16 etc.).One stop doubles or halves the amount or light that hits the filmback/ccd, so everything works in powers of 2.
So starting with 0.18 in your constant, you will see that raising it by a stop will give you .36 as a floating point number (in linear space), while your f/stop will be f/11 and so on.If you set your center stop to 0 (see below) you will get a relative readout in EVs, where EV 0 again equals 18% constant gray.

In other words. Setting the center f-stop to 0 means that in a neutral plate, the middle gray in the macbeth chart will equal to exposure value 0. EV 0 corresponds to an exposure time of 1 sec and an aperture of f/1.0.
This will set the sun usually around EV12-17 and the sky EV1-4 , depending on cloud coverage.
To switch Foundry’s Nuke’s SpotMeter to return the EV of an image, click on the main viewport, and then press s, this opens the viewer’s properties. Now set the center f-stop to 0 in there. And the SpotMeter in the viewport will change from aperture and fstops to EV.













COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
59 AI Filmmaking Tools For Your Workflow
-
Methods for creating motion blur in Stop motion
-
ComfyUI FLOAT – A container for FLOAT Generative Motion Latent Flow Matching for Audio-driven Talking Portrait – lip sync
-
AnimationXpress.com interviews Daniele Tosti for TheCgCareer.com channel
-
NVidia – High-Fidelity 3D Mesh Generation at Scale with Meshtron
-
Scene Referred vs Display Referred color workflows
-
Rec-2020 – TVs new color gamut standard used by Dolby Vision?
-
HDRI Median Cut plugin
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
