


COMPOSITION
-
Composition and The Expressive Nature Of Light
Read more: Composition and The Expressive Nature Of Lighthttp://www.huffingtonpost.com/bill-danskin/post_12457_b_10777222.html
George Sand once said “ The artist vocation is to send light into the human heart.”






















DESIGN
-
Mariko Mori – Kamitate Stone at Sean Kelly Gallery
Read more: Mariko Mori – Kamitate Stone at Sean Kelly Gallery
Mariko Mori, the internationally celebrated artist who blends technology, spirituality, and nature, debuts Kamitate Stone I this October at Sean Kelly Gallery in New York. The work continues her exploration of luminous form, energy, and transcendence.

-
Mike Mitchell x Marvel x Mondo – Iconic portraits of Marvel’s huge stable of heroes and villains
Read more: Mike Mitchell x Marvel x Mondo – Iconic portraits of Marvel’s huge stable of heroes and villainshttps://mondoshop.com/blogs/gallery/16910155-mike-mitchell-x-marvel-x-mondo
https://time.com/69659/marvel-comics-mike-mitchell-artist-portraits/
















COLOR
-
Types of Film Lights and their efficiency – CRI, Color Temperature and Luminous Efficacy
Read more: Types of Film Lights and their efficiency – CRI, Color Temperature and Luminous Efficacynofilmschool.com/types-of-film-lights
“Not every light performs the same way. Lights and lighting are tricky to handle. You have to plan for every circumstance. But the good news is, lighting can be adjusted. Let’s look at different factors that affect lighting in every scene you shoot. “
Use CRI, Luminous Efficacy and color temperature controls to match your needs.
Color Temperature
Color temperature describes the “color” of white light by a light source radiated by a perfect black body at a given temperature measured in degrees Kelvinhttps://www.pixelsham.com/2019/10/18/color-temperature/
CRI
“The Color Rendering Index is a measurement of how faithfully a light source reveals the colors of whatever it illuminates, it describes the ability of a light source to reveal the color of an object, as compared to the color a natural light source would provide. The highest possible CRI is 100. A CRI of 100 generally refers to a perfect black body, like a tungsten light source or the sun. “https://www.studiobinder.com/blog/what-is-color-rendering-index
(more…) -
Victor Perez – ACES Color Management in DaVinci Resolve
Read more: Victor Perez – ACES Color Management in DaVinci Resolvehttpv://www.youtube.com/watch?v=i–TS88-6xA
-
Light and Matter : The 2018 theory of Physically-Based Rendering and Shading by Allegorithmic
Read more: Light and Matter : The 2018 theory of Physically-Based Rendering and Shading by Allegorithmicacademy.substance3d.com/courses/the-pbr-guide-part-1
academy.substance3d.com/courses/the-pbr-guide-part-2

 Local copy:
Local copy:
-
VES Cinematic Color – Motion-Picture Color Management
Read more: VES Cinematic Color – Motion-Picture Color ManagementThis paper presents an introduction to the color pipelines behind modern feature-film visual-effects and animation.
Authored by Jeremy Selan, and reviewed by the members of the VES Technology Committee including Rob Bredow, Dan Candela, Nick Cannon, Paul Debevec, Ray Feeney, Andy Hendrickson, Gautham Krishnamurti, Sam Richards, Jordan Soles, and Sebastian Sylwan.











LIGHTING
-
Photography basics: Lumens vs Candelas (candle) vs Lux vs FootCandle vs Watts vs Irradiance vs Illuminance
Read more: Photography basics: Lumens vs Candelas (candle) vs Lux vs FootCandle vs Watts vs Irradiance vs Illuminancehttps://www.translatorscafe.com/unit-converter/en-US/illumination/1-11/

The power output of a light source is measured using the unit of watts W. This is a direct measure to calculate how much power the light is going to drain from your socket and it is not relatable to the light brightness itself.
The amount of energy emitted from it per second. That energy comes out in a form of photons which we can crudely represent with rays of light coming out of the source. The higher the power the more rays emitted from the source in a unit of time.
Not all energy emitted is visible to the human eye, so we often rely on photometric measurements, which takes in account the sensitivity of human eye to different wavelenghts


Details in the post
(more…) -
Composition – 5 tips for creating perfect cinematic lighting and making your work look stunning
Read more: Composition – 5 tips for creating perfect cinematic lighting and making your work look stunning
http://www.diyphotography.net/5-tips-creating-perfect-cinematic-lighting-making-work-look-stunning/
1. Learn the rules of lighting
2. Learn when to break the rules
3. Make your key light larger
4. Reverse keying
5. Always be backlighting
-
PTGui 13 beta adds control through a Patch Editor
Read more: PTGui 13 beta adds control through a Patch EditorAdditions:
- Patch Editor (PTGui Pro)
- DNG output
- Improved RAW / DNG handling
- JPEG 2000 support
- Performance improvements

-
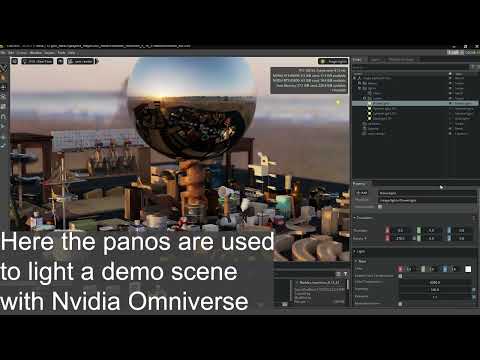
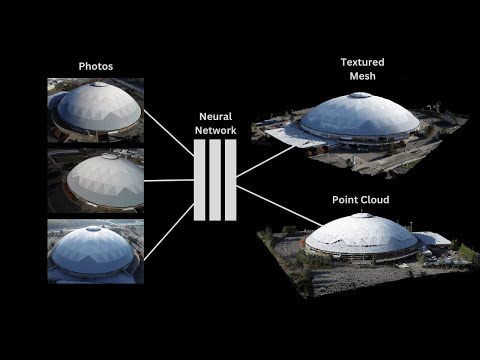
Neural Microfacet Fields for Inverse Rendering
Read more: Neural Microfacet Fields for Inverse Renderinghttps://half-potato.gitlab.io/posts/nmf/




















COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
SourceTree vs Github Desktop – Which one to use
-
WhatDreamsCost Spline-Path-Control – Create motion controls for ComfyUI
-
AI Search – Find The Best AI Tools & Apps
-
Convert 2D Images or Text to 3D Models
-
Game Development tips
-
Black Body color aka the Planckian Locus curve for white point eye perception
-
Decart AI Mirage – The first ever World Transformation Model – turning any video, game, or camera feed into a new digital world, in real time
-
Kling 1.6 and competitors – advanced tests and comparisons
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
