Size. Mr. White (Harvey Keitel) on the right. Focus. He’s one of the two objects in focus. Lighting. Mr. White is large and in focus and Mr. Pink (Steve Buscemi) is highlighted by a shaft of light. Color. Both are black and white but the read on Mr. White’s shirt now really stands out.
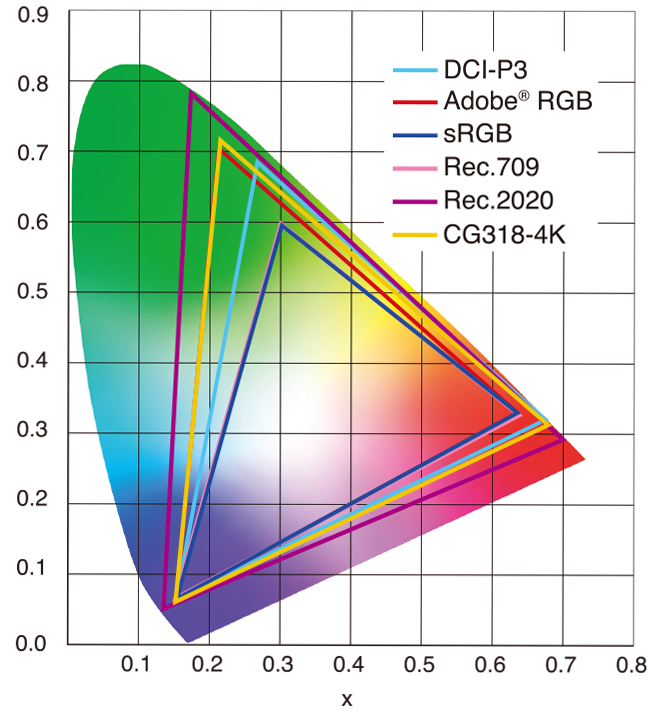
sRGB: A standard “web”/computer-display RGB color space defined by IEC 61966-2-1. It’s used for most monitors, cameras, printers, and the vast majority of images on the Internet.
Rec. 709: An HD-video color space defined by ITU-R BT.709. It’s the go-to standard for HDTV broadcasts, Blu-ray discs, and professional video pipelines.
Why they exist
sRGB: Ensures consistent colors across different consumer devices (PCs, phones, webcams).
Rec. 709: Ensures consistent colors across video production and playback chains (cameras → editing → broadcast → TV).
What you’ll see
On your desktop or phone, images tagged sRGB will look “right” without extra tweaking.
On an HDTV or video-editing timeline, footage tagged Rec. 709 will display accurate contrast and hue on broadcast-grade monitors.
Colour is an open-source Python package providing a comprehensive number of algorithms and datasets for colour science. It is freely available under the BSD-3-Clause terms.
Color Temperature of a light source describes the spectrum of light which is radiated from a theoretical “blackbody” (an ideal physical body that absorbs all radiation and incident light – neither reflecting it nor allowing it to pass through) with a given surface temperature.
Or. Most simply it is a method of describing the color characteristics of light through a numerical value that corresponds to the color emitted by a light source, measured in degrees of Kelvin (K) on a scale from 1,000 to 10,000.
More accurately. The color temperature of a light source is the temperature of an ideal backbody that radiates light of comparable hue to that of the light source.
It lets you load any .cube LUT right in your browser, see the RGB curves, and use a split view on the Granger Test Image to compare the original vs. LUT-applied version in real time — perfect for spotting hue shifts, saturation changes, and contrast tweaks.
To measure the contrast ratio you will need a light meter. The process starts with you measuring the main source of light, or the key light.
Get a reading from the brightest area on the face of your subject. Then, measure the area lit by the secondary light, or fill light. To make sense of what you have just measured you have to understand that the information you have just gathered is in F-stops, a measure of light. With each additional F-stop, for example going one stop from f/1.4 to f/2.0, you create a doubling of light. The reverse is also true; moving one stop from f/8.0 to f/5.6 results in a halving of the light.
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.






























































 Local copy:
Local copy: