


COMPOSITION
-
9 Best Hacks to Make a Cinematic Video with Any Camera
Read more: 9 Best Hacks to Make a Cinematic Video with Any Camerahttps://www.flexclip.com/learn/cinematic-video.html
- Frame Your Shots to Create Depth
- Create Shallow Depth of Field
- Avoid Shaky Footage and Use Flexible Camera Movements
- Properly Use Slow Motion
- Use Cinematic Lighting Techniques
- Apply Color Grading
- Use Cinematic Music and SFX
- Add Cinematic Fonts and Text Effects
- Create the Cinematic Bar at the Top and the Bottom






















DESIGN
-
Kristina Kashtanova – “This is how GPT-4 sees and hears itself”
Read more: Kristina Kashtanova – “This is how GPT-4 sees and hears itself”“I used GPT-4 to describe itself. Then I used its description to generate an image, a video based on this image and a soundtrack.
Tools I used: GPT-4, Midjourney, Kaiber AI, Mubert, RunwayML
This is the description I used that GPT-4 had of itself as a prompt to text-to-image, image-to-video, and text-to-music. I put the video and sound together in RunwayML.
GPT-4 described itself as: “Imagine a sleek, metallic sphere with a smooth surface, representing the vast knowledge contained within the model. The sphere emits a soft, pulsating glow that shifts between various colors, symbolizing the dynamic nature of the AI as it processes information and generates responses. The sphere appears to float in a digital environment, surrounded by streams of data and code, reflecting the complex algorithms and computing power behind the AI”















COLOR
-
Stefan Ringelschwandtner – LUT Inspector tool
Read more: Stefan Ringelschwandtner – LUT Inspector toolIt lets you load any .cube LUT right in your browser, see the RGB curves, and use a split view on the Granger Test Image to compare the original vs. LUT-applied version in real time — perfect for spotting hue shifts, saturation changes, and contrast tweaks.
https://mononodes.com/lut-inspector/


-
GretagMacbeth Color Checker Numeric Values and Middle Gray
Read more: GretagMacbeth Color Checker Numeric Values and Middle GrayThe human eye perceives half scene brightness not as the linear 50% of the present energy (linear nature values) but as 18% of the overall brightness. We are biased to perceive more information in the dark and contrast areas. A Macbeth chart helps with calibrating back into a photographic capture into this “human perspective” of the world.
https://en.wikipedia.org/wiki/Middle_gray
In photography, painting, and other visual arts, middle gray or middle grey is a tone that is perceptually about halfway between black and white on a lightness scale in photography and printing, it is typically defined as 18% reflectance in visible light

Light meters, cameras, and pictures are often calibrated using an 18% gray card[4][5][6] or a color reference card such as a ColorChecker. On the assumption that 18% is similar to the average reflectance of a scene, a grey card can be used to estimate the required exposure of the film.
https://en.wikipedia.org/wiki/ColorChecker
(more…) -
What Is The Resolution and view coverage Of The human Eye. And what distance is TV at best?
Read more: What Is The Resolution and view coverage Of The human Eye. And what distance is TV at best?
https://www.discovery.com/science/mexapixels-in-human-eye
About 576 megapixels for the entire field of view.
Consider a view in front of you that is 90 degrees by 90 degrees, like looking through an open window at a scene. The number of pixels would be:
90 degrees * 60 arc-minutes/degree * 1/0.3 * 90 * 60 * 1/0.3 = 324,000,000 pixels (324 megapixels).At any one moment, you actually do not perceive that many pixels, but your eye moves around the scene to see all the detail you want. But the human eye really sees a larger field of view, close to 180 degrees. Let’s be conservative and use 120 degrees for the field of view. Then we would see:
120 * 120 * 60 * 60 / (0.3 * 0.3) = 576 megapixels.
Or.
7 megapixels for the 2 degree focus arc… + 1 megapixel for the rest.
https://clarkvision.com/articles/eye-resolution.html
Details in the post
-
If a blind person gained sight, could they recognize objects previously touched?
Read more: If a blind person gained sight, could they recognize objects previously touched?Blind people who regain their sight may find themselves in a world they don’t immediately comprehend. “It would be more like a sighted person trying to rely on tactile information,” Moore says.
Learning to see is a developmental process, just like learning language, Prof Cathleen Moore continues. “As far as vision goes, a three-and-a-half year old child is already a well-calibrated system.”
-
The Forbidden colors – Red-Green & Blue-Yellow: The Stunning Colors You Can’t See
Read more: The Forbidden colors – Red-Green & Blue-Yellow: The Stunning Colors You Can’t Seewww.livescience.com/17948-red-green-blue-yellow-stunning-colors.html

While the human eye has red, green, and blue-sensing cones, those cones are cross-wired in the retina to produce a luminance channel plus a red-green and a blue-yellow channel, and it’s data in that color space (known technically as “LAB”) that goes to the brain. That’s why we can’t perceive a reddish-green or a yellowish-blue, whereas such colors can be represented in the RGB color space used by digital cameras.
https://en.rockcontent.com/blog/the-use-of-yellow-in-data-design
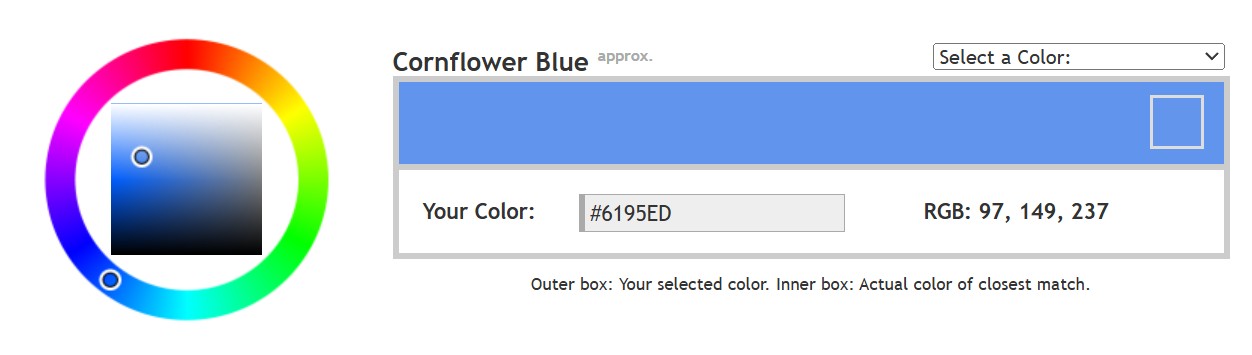
The back of the retina is covered in light-sensitive neurons known as cone cells and rod cells. There are three types of cone cells, each sensitive to different ranges of light. These ranges overlap, but for convenience the cones are referred to as blue (short-wavelength), green (medium-wavelength), and red (long-wavelength). The rod cells are primarily used in low-light situations, so we’ll ignore those for now.
When light enters the eye and hits the cone cells, the cones get excited and send signals to the brain through the visual cortex. Different wavelengths of light excite different combinations of cones to varying levels, which generates our perception of color. You can see that the red cones are most sensitive to light, and the blue cones are least sensitive. The sensitivity of green and red cones overlaps for most of the visible spectrum.

Here’s how your brain takes the signals of light intensity from the cones and turns it into color information. To see red or green, your brain finds the difference between the levels of excitement in your red and green cones. This is the red-green channel.
To get “brightness,” your brain combines the excitement of your red and green cones. This creates the luminance, or black-white, channel. To see yellow or blue, your brain then finds the difference between this luminance signal and the excitement of your blue cones. This is the yellow-blue channel.
From the calculations made in the brain along those three channels, we get four basic colors: blue, green, yellow, and red. Seeing blue is what you experience when low-wavelength light excites the blue cones more than the green and red.
Seeing green happens when light excites the green cones more than the red cones. Seeing red happens when only the red cones are excited by high-wavelength light.
Here’s where it gets interesting. Seeing yellow is what happens when BOTH the green AND red cones are highly excited near their peak sensitivity. This is the biggest collective excitement that your cones ever have, aside from seeing pure white.
Notice that yellow occurs at peak intensity in the graph to the right. Further, the lens and cornea of the eye happen to block shorter wavelengths, reducing sensitivity to blue and violet light.










LIGHTING
-
Composition – These are the basic lighting techniques you need to know for photography and film
Read more: Composition – These are the basic lighting techniques you need to know for photography and film
http://www.diyphotography.net/basic-lighting-techniques-need-know-photography-film/
Amongst the basic techniques, there’s…
1- Side lighting – Literally how it sounds, lighting a subject from the side when they’re faced toward you
2- Rembrandt lighting – Here the light is at around 45 degrees over from the front of the subject, raised and pointing down at 45 degrees
3- Back lighting – Again, how it sounds, lighting a subject from behind. This can help to add drama with silouettes
4- Rim lighting – This produces a light glowing outline around your subject
5- Key light – The main light source, and it’s not necessarily always the brightest light source
6- Fill light – This is used to fill in the shadows and provide detail that would otherwise be blackness
7- Cross lighting – Using two lights placed opposite from each other to light two subjects
-
Photography basics: Exposure Value vs Photographic Exposure vs Il/Luminance vs Pixel luminance measurements
Read more: Photography basics: Exposure Value vs Photographic Exposure vs Il/Luminance vs Pixel luminance measurementsAlso see: https://www.pixelsham.com/2015/05/16/how-aperture-shutter-speed-and-iso-affect-your-photos/
In photography, exposure value (EV) is a number that represents a combination of a camera’s shutter speed and f-number, such that all combinations that yield the same exposure have the same EV (for any fixed scene luminance).
The EV concept was developed in an attempt to simplify choosing among combinations of equivalent camera settings. Although all camera settings with the same EV nominally give the same exposure, they do not necessarily give the same picture. EV is also used to indicate an interval on the photographic exposure scale. 1 EV corresponding to a standard power-of-2 exposure step, commonly referred to as a stop
EV 0 corresponds to an exposure time of 1 sec and a relative aperture of f/1.0. If the EV is known, it can be used to select combinations of exposure time and f-number.Note EV does not equal to photographic exposure. Photographic Exposure is defined as how much light hits the camera’s sensor. It depends on the camera settings mainly aperture and shutter speed. Exposure value (known as EV) is a number that represents the exposure setting of the camera.
Thus, strictly, EV is not a measure of luminance (indirect or reflected exposure) or illuminance (incidentl exposure); rather, an EV corresponds to a luminance (or illuminance) for which a camera with a given ISO speed would use the indicated EV to obtain the nominally correct exposure. Nonetheless, it is common practice among photographic equipment manufacturers to express luminance in EV for ISO 100 speed, as when specifying metering range or autofocus sensitivity.
The exposure depends on two things: how much light gets through the lenses to the camera’s sensor and for how long the sensor is exposed. The former is a function of the aperture value while the latter is a function of the shutter speed. Exposure value is a number that represents this potential amount of light that could hit the sensor. It is important to understand that exposure value is a measure of how exposed the sensor is to light and not a measure of how much light actually hits the sensor. The exposure value is independent of how lit the scene is. For example a pair of aperture value and shutter speed represents the same exposure value both if the camera is used during a very bright day or during a dark night.
Each exposure value number represents all the possible shutter and aperture settings that result in the same exposure. Although the exposure value is the same for different combinations of aperture values and shutter speeds the resulting photo can be very different (the aperture controls the depth of field while shutter speed controls how much motion is captured).
EV 0.0 is defined as the exposure when setting the aperture to f-number 1.0 and the shutter speed to 1 second. All other exposure values are relative to that number. Exposure values are on a base two logarithmic scale. This means that every single step of EV – plus or minus 1 – represents the exposure (actual light that hits the sensor) being halved or doubled.Formulas
(more…) -
What is physically correct lighting all about?
Read more: What is physically correct lighting all about?http://gamedev.stackexchange.com/questions/60638/what-is-physically-correct-lighting-all-about
2012-08 Nathan Reed wrote:
Physically-based shading means leaving behind phenomenological models, like the Phong shading model, which are simply built to “look good” subjectively without being based on physics in any real way, and moving to lighting and shading models that are derived from the laws of physics and/or from actual measurements of the real world, and rigorously obey physical constraints such as energy conservation.
For example, in many older rendering systems, shading models included separate controls for specular highlights from point lights and reflection of the environment via a cubemap. You could create a shader with the specular and the reflection set to wildly different values, even though those are both instances of the same physical process. In addition, you could set the specular to any arbitrary brightness, even if it would cause the surface to reflect more energy than it actually received.
In a physically-based system, both the point light specular and the environment reflection would be controlled by the same parameter, and the system would be set up to automatically adjust the brightness of both the specular and diffuse components to maintain overall energy conservation. Moreover you would want to set the specular brightness to a realistic value for the material you’re trying to simulate, based on measurements.
Physically-based lighting or shading includes physically-based BRDFs, which are usually based on microfacet theory, and physically correct light transport, which is based on the rendering equation (although heavily approximated in the case of real-time games).
It also includes the necessary changes in the art process to make use of these features. Switching to a physically-based system can cause some upsets for artists. First of all it requires full HDR lighting with a realistic level of brightness for light sources, the sky, etc. and this can take some getting used to for the lighting artists. It also requires texture/material artists to do some things differently (particularly for specular), and they can be frustrated by the apparent loss of control (e.g. locking together the specular highlight and environment reflection as mentioned above; artists will complain about this). They will need some time and guidance to adapt to the physically-based system.
On the plus side, once artists have adapted and gained trust in the physically-based system, they usually end up liking it better, because there are fewer parameters overall (less work for them to tweak). Also, materials created in one lighting environment generally look fine in other lighting environments too. This is unlike more ad-hoc models, where a set of material parameters might look good during daytime, but it comes out ridiculously glowy at night, or something like that.
Here are some resources to look at for physically-based lighting in games:
SIGGRAPH 2013 Physically Based Shading Course, particularly the background talk by Naty Hoffman at the beginning. You can also check out the previous incarnations of this course for more resources.
Sébastien Lagarde, Adopting a physically-based shading model and Feeding a physically-based shading model
And of course, I would be remiss if I didn’t mention Physically-Based Rendering by Pharr and Humphreys, an amazing reference on this whole subject and well worth your time, although it focuses on offline rather than real-time rendering.
-
Neural Microfacet Fields for Inverse Rendering
Read more: Neural Microfacet Fields for Inverse Renderinghttps://half-potato.gitlab.io/posts/nmf/

-
DiffusionLight: HDRI Light Probes for Free by Painting a Chrome Ball
Read more: DiffusionLight: HDRI Light Probes for Free by Painting a Chrome Ballhttps://diffusionlight.github.io/
https://github.com/DiffusionLight/DiffusionLight
https://github.com/DiffusionLight/DiffusionLight?tab=MIT-1-ov-file#readme
https://colab.research.google.com/drive/15pC4qb9mEtRYsW3utXkk-jnaeVxUy-0S
“a simple yet effective technique to estimate lighting in a single input image. Current techniques rely heavily on HDR panorama datasets to train neural networks to regress an input with limited field-of-view to a full environment map. However, these approaches often struggle with real-world, uncontrolled settings due to the limited diversity and size of their datasets. To address this problem, we leverage diffusion models trained on billions of standard images to render a chrome ball into the input image. Despite its simplicity, this task remains challenging: the diffusion models often insert incorrect or inconsistent objects and cannot readily generate images in HDR format. Our research uncovers a surprising relationship between the appearance of chrome balls and the initial diffusion noise map, which we utilize to consistently generate high-quality chrome balls. We further fine-tune an LDR difusion model (Stable Diffusion XL) with LoRA, enabling it to perform exposure bracketing for HDR light estimation. Our method produces convincing light estimates across diverse settings and demonstrates superior generalization to in-the-wild scenarios.”












COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Film Production walk-through – pipeline – I want to make a … movie
-
JavaScript how-to free resources
-
Advanced Computer Vision with Python OpenCV and Mediapipe
-
FFmpeg – examples and convenience lines
-
Most common ways to smooth 3D prints
-
WhatDreamsCost Spline-Path-Control – Create motion controls for ComfyUI
-
NVidia – High-Fidelity 3D Mesh Generation at Scale with Meshtron
-
Alejandro Villabón and Rafał Kaniewski – Recover Highlights With 8-Bit to High Dynamic Range Half Float Copycat – Nuke
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
