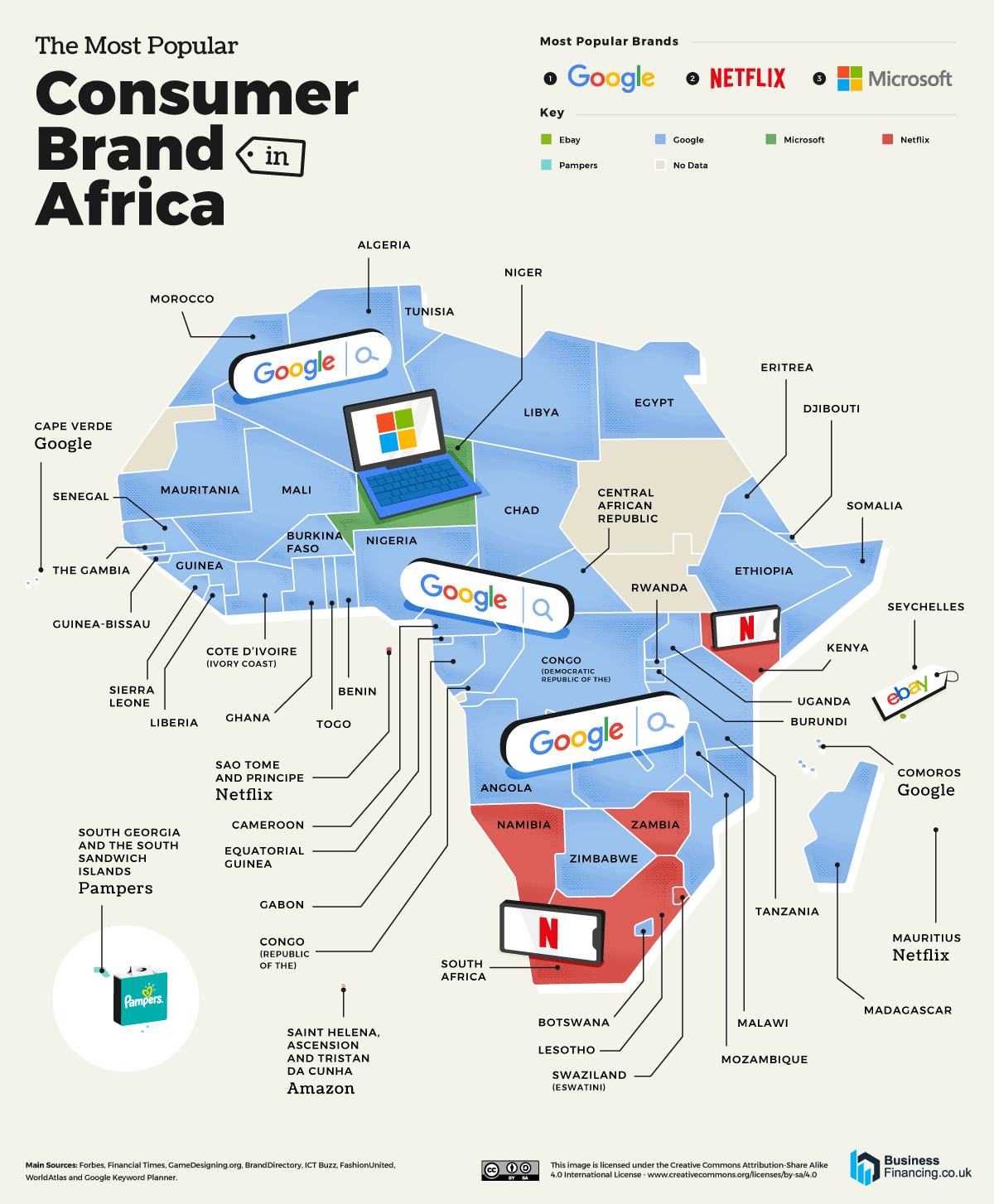
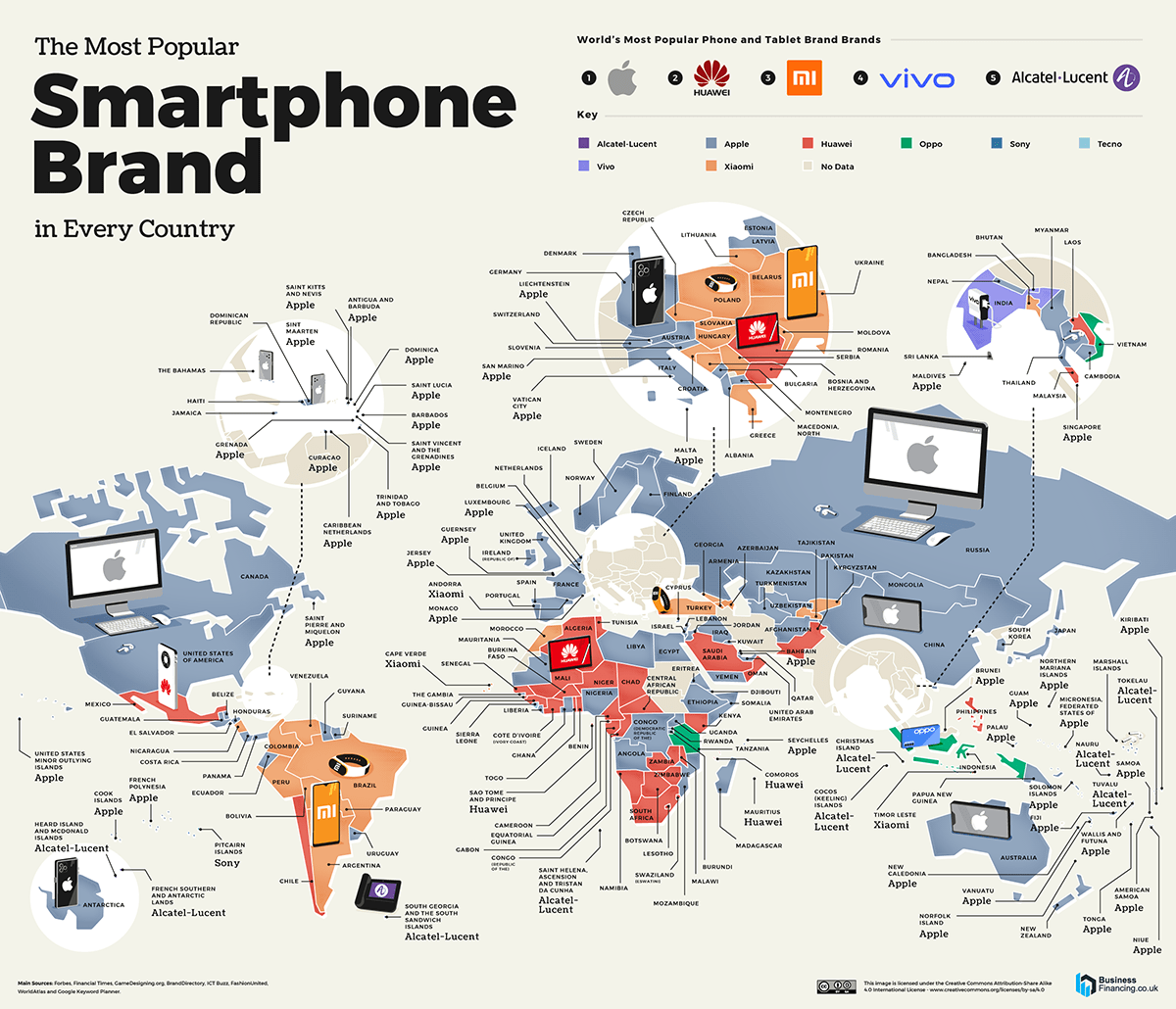
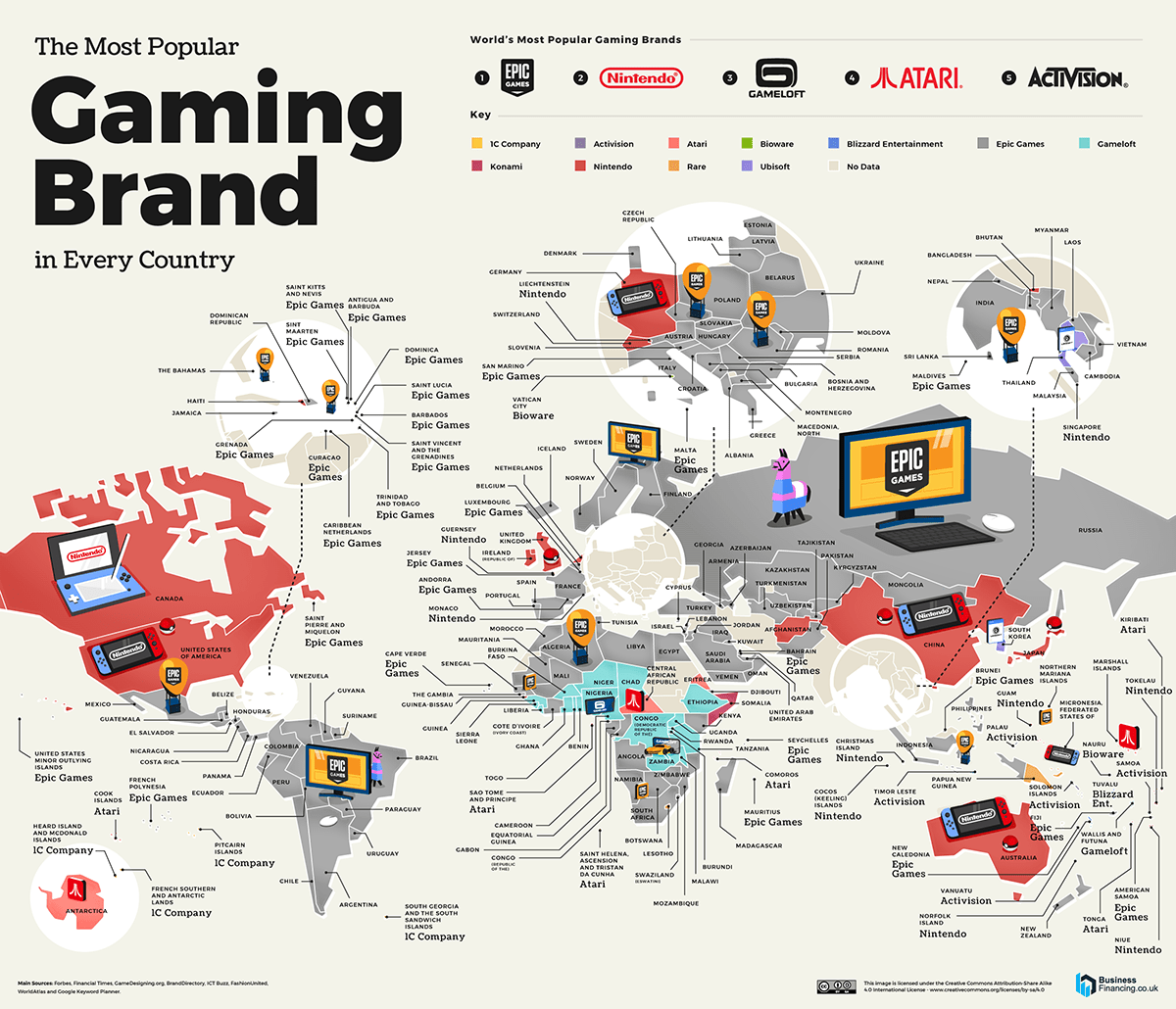
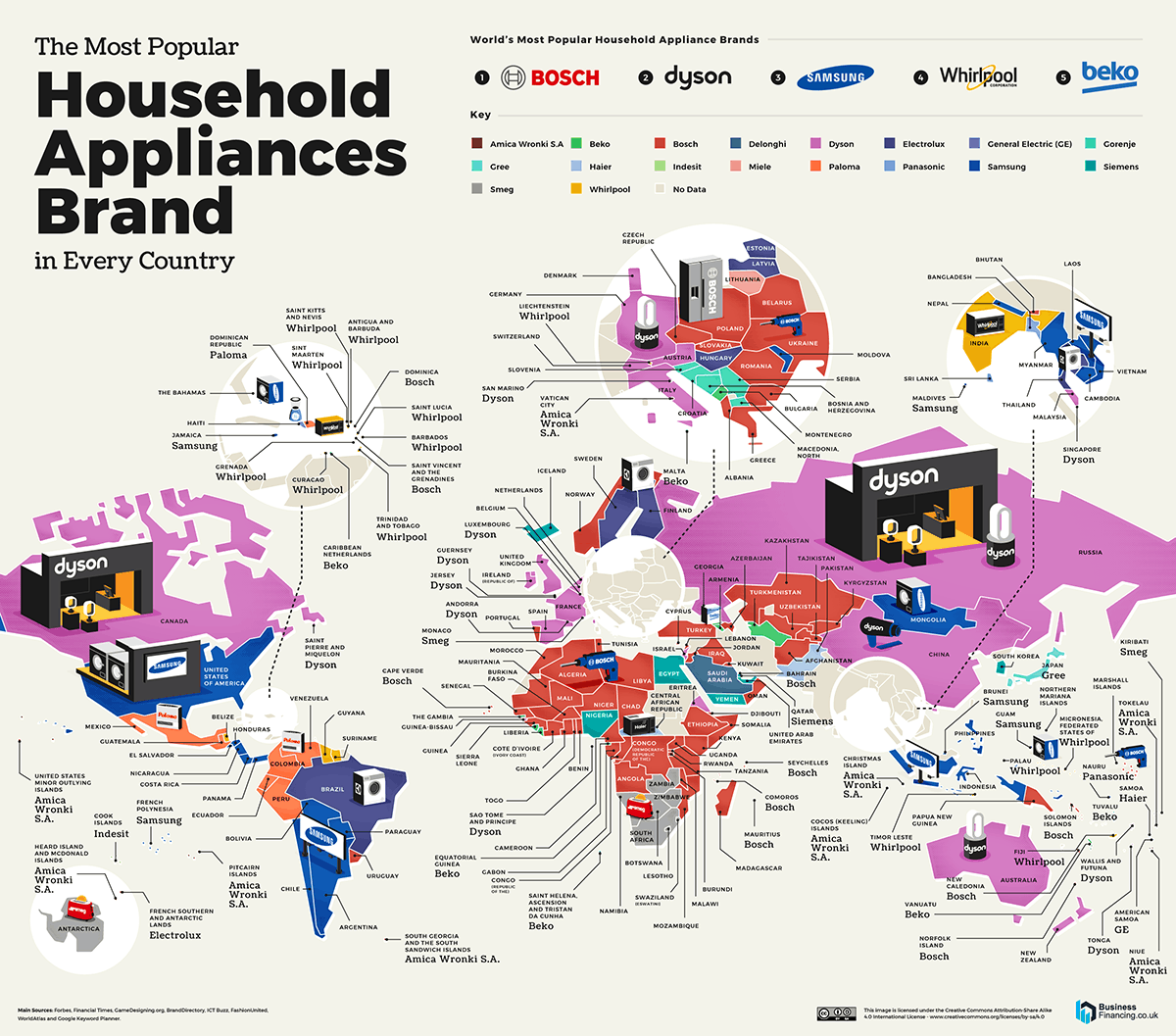
Since spending a lot of time recently with SDXL I’ve since made my way back to SD 1.5
While the models overall have less fidelity. There is just no comparing to the current motion models we have available for animatediff with 1.5 models.
To date this is one of my favorite pieces. Not because I think it’s even the best it can be. But because the workflow adjustments unlocked some very important ideas I can’t wait to try out.
Performance by @silkenkelly and @itxtheballerina on IG
Arminas created this using Juggernaut Xl model and QR Code Monster SDXL ControlNet.
His pipeline: Static Images – Forge UI. Upscaled with Leonardo AI universal upscaler. Animated with Runway ML and Minimax. Video upscale – Topaz Video AI. Composited in Adobe Premiere.
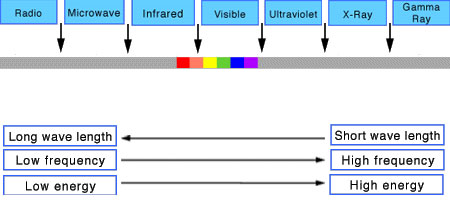
In color technology, color depth also known as bit depth, is either the number of bits used to indicate the color of a single pixel, OR the number of bits used for each color component of a single pixel.
When referring to a pixel, the concept can be defined as bits per pixel (bpp).
When referring to a color component, the concept can be defined as bits per component, bits per channel, bits per color (all three abbreviated bpc), and also bits per pixel component, bits per color channel or bits per sample (bps). Modern standards tend to use bits per component, but historical lower-depth systems used bits per pixel more often.
Color depth is only one aspect of color representation, expressing the precision with which the amount of each primary can be expressed; the other aspect is how broad a range of colors can be expressed (the gamut). The definition of both color precision and gamut is accomplished with a color encoding specification which assigns a digital code value to a location in a color space.
Black-body radiation is the type of electromagnetic radiation within or surrounding a body in thermodynamic equilibrium with its environment, or emitted by a black body (an opaque and non-reflective body) held at constant, uniform temperature. The radiation has a specific spectrum and intensity that depends only on the temperature of the body.
A black-body at room temperature appears black, as most of the energy it radiates is infra-red and cannot be perceived by the human eye. At higher temperatures, black bodies glow with increasing intensity and colors that range from dull red to blindingly brilliant blue-white as the temperature increases.
Size. Mr. White (Harvey Keitel) on the right. Focus. He’s one of the two objects in focus. Lighting. Mr. White is large and in focus and Mr. Pink (Steve Buscemi) is highlighted by a shaft of light. Color. Both are black and white but the read on Mr. White’s shirt now really stands out.
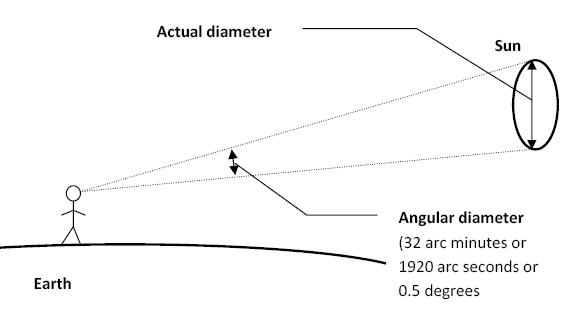
The cone angle of the sun refers to the angular diameter of the sun as observed from Earth, which is related to the apparent size of the sun in the sky.
The angular diameter of the sun, or the cone angle of the sunlight as perceived from Earth, is approximately 0.53 degrees on average. This value can vary slightly due to the elliptical nature of Earth’s orbit around the sun, but it generally stays within a narrow range.
Here’s a more precise breakdown:
Average Angular Diameter: About 0.53 degrees (31 arcminutes)
Minimum Angular Diameter: Approximately 0.52 degrees (when Earth is at aphelion, the farthest point from the sun)
Maximum Angular Diameter: Approximately 0.54 degrees (when Earth is at perihelion, the closest point to the sun)
This angular diameter remains relatively constant throughout the day because the sun’s distance from Earth does not change significantly over a single day.
To summarize, the cone angle of the sun’s light, or its angular diameter, is typically around 0.53 degrees, regardless of the time of day.
In general, when light interacts with matter, a complicated light-matter dynamic occurs. This interaction depends on the physical characteristics of the light as well as the physical composition and characteristics of the matter.
That is, some of the incident light is reflected, some of the light is transmitted, and another portion of the light is absorbed by the medium itself.
A BRDF describes how much light is reflected when light makes contact with a certain material. Similarly, a BTDF (Bi-directional Transmission Distribution Function) describes how much light is transmitted when light makes contact with a certain material
It is difficult to establish exactly how far one should go in elaborating the surface model. A truly complete representation of the reflective behavior of a surface might take into account such phenomena as polarization, scattering, fluorescence, and phosphorescence, all of which might vary with position on the surface. Therefore, the variables in this complete function would be:
incoming and outgoing angle incoming and outgoing wavelength incoming and outgoing polarization (both linear and circular) incoming and outgoing position (which might differ due to subsurface scattering) time delay between the incoming and outgoing light ray
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.