


COMPOSITION
-
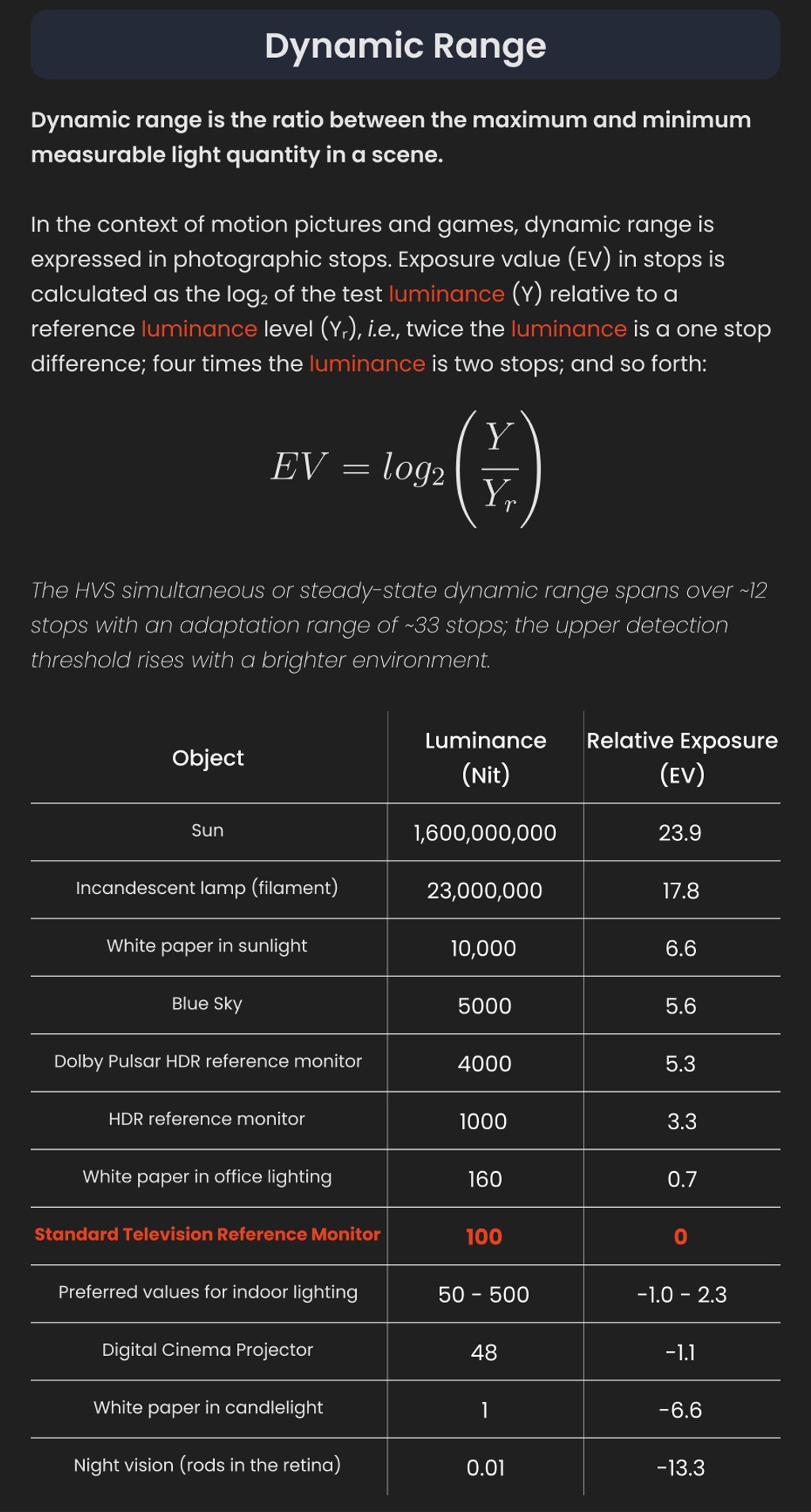
Types of Film Lights and their efficiency – CRI, Color Temperature and Luminous Efficacy
Read more: Types of Film Lights and their efficiency – CRI, Color Temperature and Luminous Efficacynofilmschool.com/types-of-film-lights
“Not every light performs the same way. Lights and lighting are tricky to handle. You have to plan for every circumstance. But the good news is, lighting can be adjusted. Let’s look at different factors that affect lighting in every scene you shoot. “
Use CRI, Luminous Efficacy and color temperature controls to match your needs.
Color Temperature
Color temperature describes the “color” of white light by a light source radiated by a perfect black body at a given temperature measured in degrees Kelvinhttps://www.pixelsham.com/2019/10/18/color-temperature/
CRI
“The Color Rendering Index is a measurement of how faithfully a light source reveals the colors of whatever it illuminates, it describes the ability of a light source to reveal the color of an object, as compared to the color a natural light source would provide. The highest possible CRI is 100. A CRI of 100 generally refers to a perfect black body, like a tungsten light source or the sun. “https://www.studiobinder.com/blog/what-is-color-rendering-index
(more…) -
Composition – cinematography Cheat Sheet
Read more: Composition – cinematography Cheat Sheet
Where is our eye attracted first? Why?
Size. Focus. Lighting. Color.
Size. Mr. White (Harvey Keitel) on the right.
Focus. He’s one of the two objects in focus.
Lighting. Mr. White is large and in focus and Mr. Pink (Steve Buscemi) is highlighted by
a shaft of light.
Color. Both are black and white but the read on Mr. White’s shirt now really stands out.
(more…)
What type of lighting? -
Composition and The Expressive Nature Of Light
Read more: Composition and The Expressive Nature Of Lighthttp://www.huffingtonpost.com/bill-danskin/post_12457_b_10777222.html
George Sand once said “ The artist vocation is to send light into the human heart.”














DESIGN
-
Kristina Kashtanova – “This is how GPT-4 sees and hears itself”
Read more: Kristina Kashtanova – “This is how GPT-4 sees and hears itself”“I used GPT-4 to describe itself. Then I used its description to generate an image, a video based on this image and a soundtrack.
Tools I used: GPT-4, Midjourney, Kaiber AI, Mubert, RunwayML
This is the description I used that GPT-4 had of itself as a prompt to text-to-image, image-to-video, and text-to-music. I put the video and sound together in RunwayML.
GPT-4 described itself as: “Imagine a sleek, metallic sphere with a smooth surface, representing the vast knowledge contained within the model. The sphere emits a soft, pulsating glow that shifts between various colors, symbolizing the dynamic nature of the AI as it processes information and generates responses. The sphere appears to float in a digital environment, surrounded by streams of data and code, reflecting the complex algorithms and computing power behind the AI”













COLOR
-
Photography Basics : Spectral Sensitivity Estimation Without a Camera
Read more: Photography Basics : Spectral Sensitivity Estimation Without a Camerahttps://color-lab-eilat.github.io/Spectral-sensitivity-estimation-web/
A number of problems in computer vision and related fields would be mitigated if camera spectral sensitivities were known. As consumer cameras are not designed for high-precision visual tasks, manufacturers do not disclose spectral sensitivities. Their estimation requires a costly optical setup, which triggered researchers to come up with numerous indirect methods that aim to lower cost and complexity by using color targets. However, the use of color targets gives rise to new complications that make the estimation more difficult, and consequently, there currently exists no simple, low-cost, robust go-to method for spectral sensitivity estimation that non-specialized research labs can adopt. Furthermore, even if not limited by hardware or cost, researchers frequently work with imagery from multiple cameras that they do not have in their possession.
To provide a practical solution to this problem, we propose a framework for spectral sensitivity estimation that not only does not require any hardware (including a color target), but also does not require physical access to the camera itself. Similar to other work, we formulate an optimization problem that minimizes a two-term objective function: a camera-specific term from a system of equations, and a universal term that bounds the solution space.
Different than other work, we utilize publicly available high-quality calibration data to construct both terms. We use the colorimetric mapping matrices provided by the Adobe DNG Converter to formulate the camera-specific system of equations, and constrain the solutions using an autoencoder trained on a database of ground-truth curves. On average, we achieve reconstruction errors as low as those that can arise due to manufacturing imperfections between two copies of the same camera. We provide predicted sensitivities for more than 1,000 cameras that the Adobe DNG Converter currently supports, and discuss which tasks can become trivial when camera responses are available.



-
Anders Langlands – Render Color Spaces
Read more: Anders Langlands – Render Color Spaceshttps://www.colour-science.org/anders-langlands/
This page compares images rendered in Arnold using spectral rendering and different sets of colourspace primaries: Rec.709, Rec.2020, ACES and DCI-P3. The SPD data for the GretagMacbeth Color Checker are the measurements of Noburu Ohta, taken from Mansencal, Mauderer and Parsons (2014) colour-science.org.

-
Pattern generators
Read more: Pattern generatorshttp://qrohlf.com/trianglify-generator/
https://halftonepro.com/app/polygons#
https://mattdesl.svbtle.com/generative-art-with-nodejs-and-canvas
https://www.patterncooler.com/
http://permadi.com/java/spaint/spaint.html
https://dribbble.com/shots/1847313-Kaleidoscope-Generator-PSD
http://eskimoblood.github.io/gerstnerizer/
http://www.stripegenerator.com/
http://btmills.github.io/geopattern/geopattern.html
http://fractalarchitect.net/FA4-Random-Generator.html
https://sciencevsmagic.net/fractal/#0605,0000,3,2,0,1,2
https://sites.google.com/site/mandelbulber/home
-
The Forbidden colors – Red-Green & Blue-Yellow: The Stunning Colors You Can’t See
Read more: The Forbidden colors – Red-Green & Blue-Yellow: The Stunning Colors You Can’t Seewww.livescience.com/17948-red-green-blue-yellow-stunning-colors.html

While the human eye has red, green, and blue-sensing cones, those cones are cross-wired in the retina to produce a luminance channel plus a red-green and a blue-yellow channel, and it’s data in that color space (known technically as “LAB”) that goes to the brain. That’s why we can’t perceive a reddish-green or a yellowish-blue, whereas such colors can be represented in the RGB color space used by digital cameras.
https://en.rockcontent.com/blog/the-use-of-yellow-in-data-design
The back of the retina is covered in light-sensitive neurons known as cone cells and rod cells. There are three types of cone cells, each sensitive to different ranges of light. These ranges overlap, but for convenience the cones are referred to as blue (short-wavelength), green (medium-wavelength), and red (long-wavelength). The rod cells are primarily used in low-light situations, so we’ll ignore those for now.
When light enters the eye and hits the cone cells, the cones get excited and send signals to the brain through the visual cortex. Different wavelengths of light excite different combinations of cones to varying levels, which generates our perception of color. You can see that the red cones are most sensitive to light, and the blue cones are least sensitive. The sensitivity of green and red cones overlaps for most of the visible spectrum.

Here’s how your brain takes the signals of light intensity from the cones and turns it into color information. To see red or green, your brain finds the difference between the levels of excitement in your red and green cones. This is the red-green channel.
To get “brightness,” your brain combines the excitement of your red and green cones. This creates the luminance, or black-white, channel. To see yellow or blue, your brain then finds the difference between this luminance signal and the excitement of your blue cones. This is the yellow-blue channel.
From the calculations made in the brain along those three channels, we get four basic colors: blue, green, yellow, and red. Seeing blue is what you experience when low-wavelength light excites the blue cones more than the green and red.
Seeing green happens when light excites the green cones more than the red cones. Seeing red happens when only the red cones are excited by high-wavelength light.
Here’s where it gets interesting. Seeing yellow is what happens when BOTH the green AND red cones are highly excited near their peak sensitivity. This is the biggest collective excitement that your cones ever have, aside from seeing pure white.
Notice that yellow occurs at peak intensity in the graph to the right. Further, the lens and cornea of the eye happen to block shorter wavelengths, reducing sensitivity to blue and violet light.













LIGHTING
-
Types of Film Lights and their efficiency – CRI, Color Temperature and Luminous Efficacy
Read more: Types of Film Lights and their efficiency – CRI, Color Temperature and Luminous Efficacynofilmschool.com/types-of-film-lights
“Not every light performs the same way. Lights and lighting are tricky to handle. You have to plan for every circumstance. But the good news is, lighting can be adjusted. Let’s look at different factors that affect lighting in every scene you shoot. “
Use CRI, Luminous Efficacy and color temperature controls to match your needs.Color Temperature
Color temperature describes the “color” of white light by a light source radiated by a perfect black body at a given temperature measured in degrees Kelvinhttps://www.pixelsham.com/2019/10/18/color-temperature/
CRI
“The Color Rendering Index is a measurement of how faithfully a light source reveals the colors of whatever it illuminates, it describes the ability of a light source to reveal the color of an object, as compared to the color a natural light source would provide. The highest possible CRI is 100. A CRI of 100 generally refers to a perfect black body, like a tungsten light source or the sun. “https://www.studiobinder.com/blog/what-is-color-rendering-index
(more…) -
Bella – Fast Spectral Rendering
Read more: Bella – Fast Spectral Rendering
Bella works in spectral space, allowing effects such as BSDF wavelength dependency, diffraction, or atmosphere to be modeled far more accurately than in color space.

https://superrendersfarm.com/blog/uncategorized/bella-a-new-spectral-physically-based-renderer/
-
Debayer – A free command line tool to convert camera raw images into scene-linear exr
Read more: Debayer – A free command line tool to convert camera raw images into scene-linear exr
https://github.com/jedypod/debayer
The only required dependency is oiiotool. However other “debayer engines” are also supported.
- OpenImageIO – oiiotool is used for converting debayered tif images to exr.
- Debayer Engines
- RawTherapee – Powerful raw development software used to decode raw images. High quality, good selection of debayer algorithms, and more advanced raw processing like chromatic aberration removal.
- LibRaw – dcraw_emu commandline utility included with LibRaw. Optional alternative for debayer. Simple, fast and effective.
- Darktable – Uses darktable-cli plus an xmp config to process.
- vkdt – uses vkdt-cli to debayer. Pretty experimental still. Uses Vulkan for image processing. Stupidly fast. Pretty limited.
-
9 Best Hacks to Make a Cinematic Video with Any Camera
Read more: 9 Best Hacks to Make a Cinematic Video with Any Camerahttps://www.flexclip.com/learn/cinematic-video.html
- Frame Your Shots to Create Depth
- Create Shallow Depth of Field
- Avoid Shaky Footage and Use Flexible Camera Movements
- Properly Use Slow Motion
- Use Cinematic Lighting Techniques
- Apply Color Grading
- Use Cinematic Music and SFX
- Add Cinematic Fonts and Text Effects
- Create the Cinematic Bar at the Top and the Bottom

-
Cinematographers Blueprint 300dpi poster
Read more: Cinematographers Blueprint 300dpi posterThe 300dpi digital poster is now available to all PixelSham.com subscribers.

If you have already subscribed and wish a copy, please send me a note through the contact page.
-
NVidia DiffusionRenderer – Neural Inverse and Forward Rendering with Video Diffusion Models. How NVIDIA reimagined relighting
Read more: NVidia DiffusionRenderer – Neural Inverse and Forward Rendering with Video Diffusion Models. How NVIDIA reimagined relightinghttps://www.fxguide.com/quicktakes/diffusing-reality-how-nvidia-reimagined-relighting/
https://research.nvidia.com/labs/toronto-ai/DiffusionRenderer/


-
Willem Zwarthoed – Aces gamut in VFX production pdf
Read more: Willem Zwarthoed – Aces gamut in VFX production pdfhttps://www.provideocoalition.com/color-management-part-12-introducing-aces/
Local copy:
https://www.slideshare.net/hpduiker/acescg-a-common-color-encoding-for-visual-effects-applications
-
Open Source Nvidia Omniverse
Read more: Open Source Nvidia Omniverseblogs.nvidia.com/blog/2019/03/18/omniverse-collaboration-platform/

developer.nvidia.com/nvidia-omniverse
An open, Interactive 3D Design Collaboration Platform for Multi-Tool Workflows to simplify studio workflows for real-time graphics.
It supports Pixar’s Universal Scene Description technology for exchanging information about modeling, shading, animation, lighting, visual effects and rendering across multiple applications.
It also supports NVIDIA’s Material Definition Language, which allows artists to exchange information about surface materials across multiple tools.
With Omniverse, artists can see live updates made by other artists working in different applications. They can also see changes reflected in multiple tools at the same time.
For example an artist using Maya with a portal to Omniverse can collaborate with another artist using UE4 and both will see live updates of each others’ changes in their application.








{kind=link}
COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Matt Hallett – WAN 2.1 VACE Total Video Control in ComfyUI
-
AI and the Law – Netflix : Using Generative AI in Content Production
-
N8N.io – From Zero to Your First AI Agent in 25 Minutes
-
Types of AI Explained in a few Minutes – AI Glossary
-
White Balance is Broken!
-
Google – Artificial Intelligence free courses
-
Photography basics: Production Rendering Resolution Charts
-
GretagMacbeth Color Checker Numeric Values and Middle Gray
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
