


COMPOSITION
-
9 Best Hacks to Make a Cinematic Video with Any Camera
Read more: 9 Best Hacks to Make a Cinematic Video with Any Camerahttps://www.flexclip.com/learn/cinematic-video.html
- Frame Your Shots to Create Depth
- Create Shallow Depth of Field
- Avoid Shaky Footage and Use Flexible Camera Movements
- Properly Use Slow Motion
- Use Cinematic Lighting Techniques
- Apply Color Grading
- Use Cinematic Music and SFX
- Add Cinematic Fonts and Text Effects
- Create the Cinematic Bar at the Top and the Bottom

-
SlowMoVideo – How to make a slow motion shot with the open source program
Read more: SlowMoVideo – How to make a slow motion shot with the open source programhttp://slowmovideo.granjow.net/
slowmoVideo is an OpenSource program that creates slow-motion videos from your footage.
Slow motion cinematography is the result of playing back frames for a longer duration than they were exposed. For example, if you expose 240 frames of film in one second, then play them back at 24 fps, the resulting movie is 10 times longer (slower) than the original filmed event….
Film cameras are relatively simple mechanical devices that allow you to crank up the speed to whatever rate the shutter and pull-down mechanism allow. Some film cameras can operate at 2,500 fps or higher (although film shot in these cameras often needs some readjustment in postproduction). Video, on the other hand, is always captured, recorded, and played back at a fixed rate, with a current limit around 60fps. This makes extreme slow motion effects harder to achieve (and less elegant) on video, because slowing down the video results in each frame held still on the screen for a long time, whereas with high-frame-rate film there are plenty of frames to fill the longer durations of time. On video, the slow motion effect is more like a slide show than smooth, continuous motion.
One obvious solution is to shoot film at high speed, then transfer it to video (a case where film still has a clear advantage, sorry George). Another possibility is to cross dissolve or blur from one frame to the next. This adds a smooth transition from one still frame to the next. The blur reduces the sharpness of the image, and compared to slowing down images shot at a high frame rate, this is somewhat of a cheat. However, there isn’t much you can do about it until video can be recorded at much higher rates. Of course, many film cameras can’t shoot at high frame rates either, so the whole super-slow-motion endeavor is somewhat specialized no matter what medium you are using. (There are some high speed digital cameras available now that allow you to capture lots of digital frames directly to your computer, so technology is starting to catch up with film. However, this feature isn’t going to appear in consumer camcorders any time soon.)





















DESIGN
-
IM3 Stained glass
Read more: IM3 Stained glass
http://imgur.com/a/GXUun#hO6wzrs
Some people are asking how… here is a brief explanation on how I did it with photos….
(more…) -
The 7 key elements of brand identity design + 10 corporate identity examples
Read more: The 7 key elements of brand identity design + 10 corporate identity exampleswww.lucidpress.com/blog/the-7-key-elements-of-brand-identity-design
1. Clear brand purpose and positioning
2. Thorough market research
3. Likable brand personality
4. Memorable logo
5. Attractive color palette
6. Professional typography
7. On-brand supporting graphics

-













COLOR
-
Paul Debevec, Chloe LeGendre, Lukas Lepicovsky – Jointly Optimizing Color Rendition and In-Camera Backgrounds in an RGB Virtual Production Stage
Read more: Paul Debevec, Chloe LeGendre, Lukas Lepicovsky – Jointly Optimizing Color Rendition and In-Camera Backgrounds in an RGB Virtual Production Stagehttps://arxiv.org/pdf/2205.12403.pdf
RGB LEDs vs RGBWP (RGB + lime + phospor converted amber) LEDs
Local copy:
-
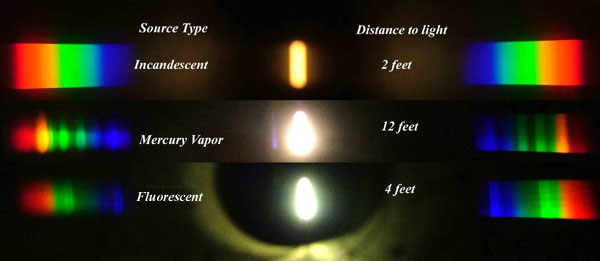
Is a MacBeth Colour Rendition Chart the Safest Way to Calibrate a Camera?
Read more: Is a MacBeth Colour Rendition Chart the Safest Way to Calibrate a Camera?www.colour-science.org/posts/the-colorchecker-considered-mostly-harmless/
“Unless you have all the relevant spectral measurements, a colour rendition chart should not be used to perform colour-correction of camera imagery but only for white balancing and relative exposure adjustments.”
“Using a colour rendition chart for colour-correction might dramatically increase error if the scene light source spectrum is different from the illuminant used to compute the colour rendition chart’s reference values.”
“other factors make using a colour rendition chart unsuitable for camera calibration:
– Uncontrolled geometry of the colour rendition chart with the incident illumination and the camera.
– Unknown sample reflectances and ageing as the colour of the samples vary with time.
– Low samples count.
– Camera noise and flare.
– Etc…“Those issues are well understood in the VFX industry, and when receiving plates, we almost exclusively use colour rendition charts to white balance and perform relative exposure adjustments, i.e. plate neutralisation.”
-
Space bodies’ components and light spectroscopy
Read more: Space bodies’ components and light spectroscopywww.plutorules.com/page-111-space-rocks.html
This help’s us understand the composition of components in/on solar system bodies.
Dips in the observed light spectrum, also known as, lines of absorption occur as gasses absorb energy from light at specific points along the light spectrum.
These dips or darkened zones (lines of absorption) leave a finger print which identify elements and compounds.
In this image the dark absorption bands appear as lines of emission which occur as the result of emitted not reflected (absorbed) light.
Lines of absorption
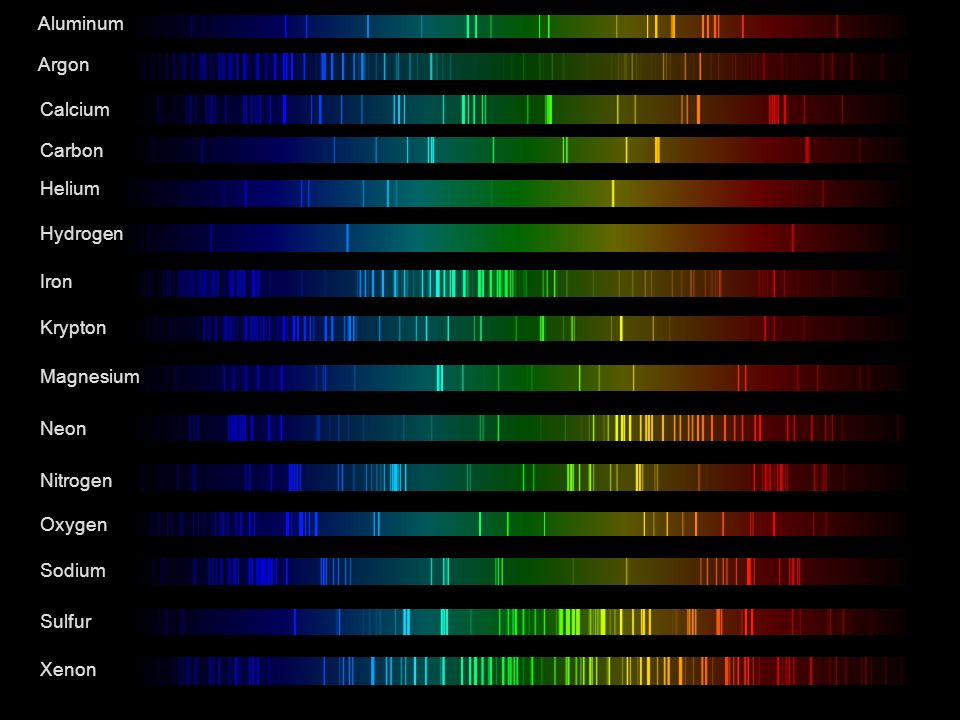 Lines of emission
Lines of emission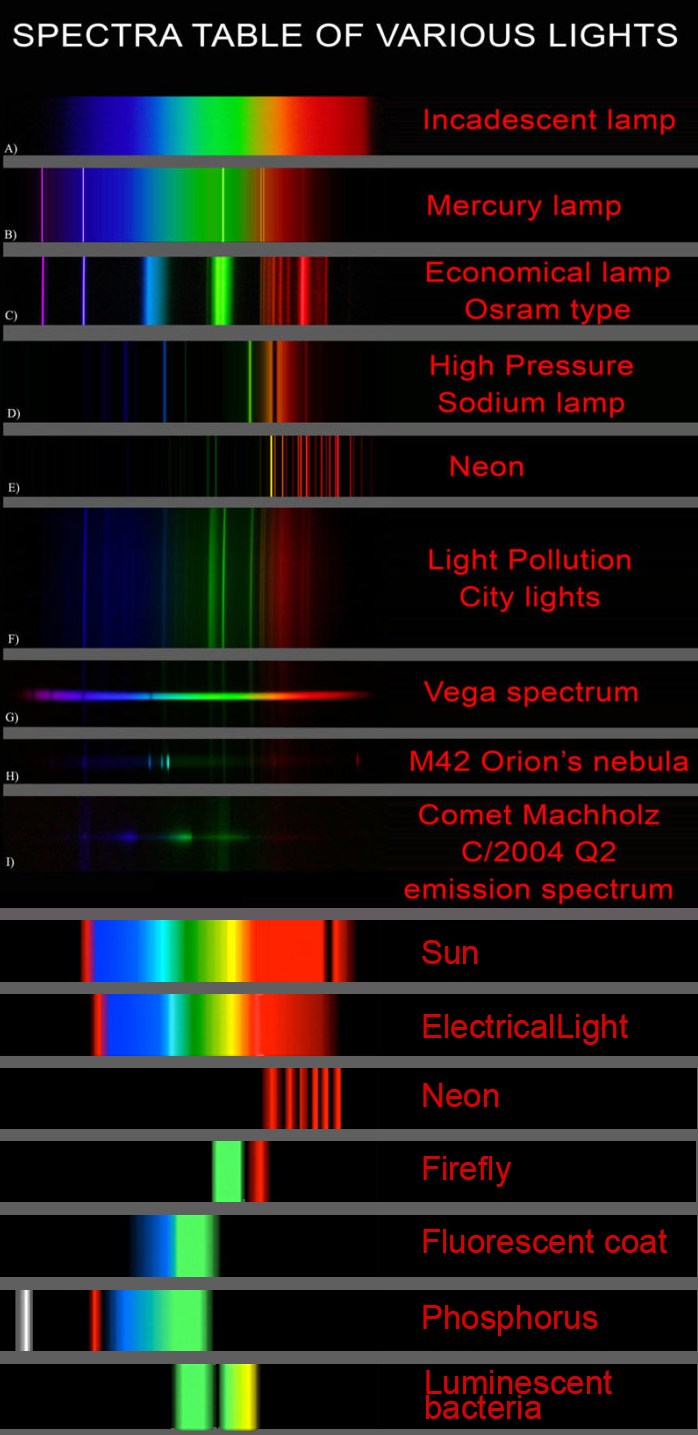


-
Types of Film Lights and their efficiency – CRI, Color Temperature and Luminous Efficacy
Read more: Types of Film Lights and their efficiency – CRI, Color Temperature and Luminous Efficacynofilmschool.com/types-of-film-lights
“Not every light performs the same way. Lights and lighting are tricky to handle. You have to plan for every circumstance. But the good news is, lighting can be adjusted. Let’s look at different factors that affect lighting in every scene you shoot. “
Use CRI, Luminous Efficacy and color temperature controls to match your needs.
Color Temperature
Color temperature describes the “color” of white light by a light source radiated by a perfect black body at a given temperature measured in degrees Kelvinhttps://www.pixelsham.com/2019/10/18/color-temperature/
CRI
“The Color Rendering Index is a measurement of how faithfully a light source reveals the colors of whatever it illuminates, it describes the ability of a light source to reveal the color of an object, as compared to the color a natural light source would provide. The highest possible CRI is 100. A CRI of 100 generally refers to a perfect black body, like a tungsten light source or the sun. “https://www.studiobinder.com/blog/what-is-color-rendering-index
(more…) -
The 7 key elements of brand identity design + 10 corporate identity examples
Read more: The 7 key elements of brand identity design + 10 corporate identity exampleswww.lucidpress.com/blog/the-7-key-elements-of-brand-identity-design
1. Clear brand purpose and positioning
2. Thorough market research
3. Likable brand personality
4. Memorable logo
5. Attractive color palette
6. Professional typography
7. On-brand supporting graphics
-
Scene Referred vs Display Referred color workflows
Read more: Scene Referred vs Display Referred color workflowsDisplay Referred it is tied to the target hardware, as such it bakes color requirements into every type of media output request.
Scene Referred uses a common unified wide gamut and targeting audience through CDL and DI libraries instead.
So that color information stays untouched and only “transformed” as/when needed.



Sources:
– Victor Perez – Color Management Fundamentals & ACES Workflows in Nuke
– https://z-fx.nl/ColorspACES.pdf
– Wicus




![[gamma correction test]](http://www.madore.org/~david/misc/color/gammatest.png "sRGB gamma correction test")









LIGHTING
-
Composition and The Expressive Nature Of Light
Read more: Composition and The Expressive Nature Of Lighthttp://www.huffingtonpost.com/bill-danskin/post_12457_b_10777222.html
George Sand once said “ The artist vocation is to send light into the human heart.”

-
Outpost VFX lighting tips
Read more: Outpost VFX lighting tipswww.outpost-vfx.com/en/news/18-pro-tips-and-tricks-for-lighting
Get as much information regarding your plate lighting as possible
- Always use a reference
- Replicate what is happening in real life
- Invest into a solid HDRI
- Start Simple
- Observe real world lighting, photography and cinematography
- Don’t neglect the theory
- Learn the difference between realism and photo-realism.
- Keep your scenes organised

-
Lighting Every Darkness with 3DGS: Fast Training and Real-Time Rendering and Denoising for HDR View Synthesis
Read more: Lighting Every Darkness with 3DGS: Fast Training and Real-Time Rendering and Denoising for HDR View Synthesishttps://srameo.github.io/projects/le3d/
LE3D is a method for real-time HDR view synthesis from RAW images. It is particularly effective for nighttime scenes.
https://github.com/Srameo/LE3D
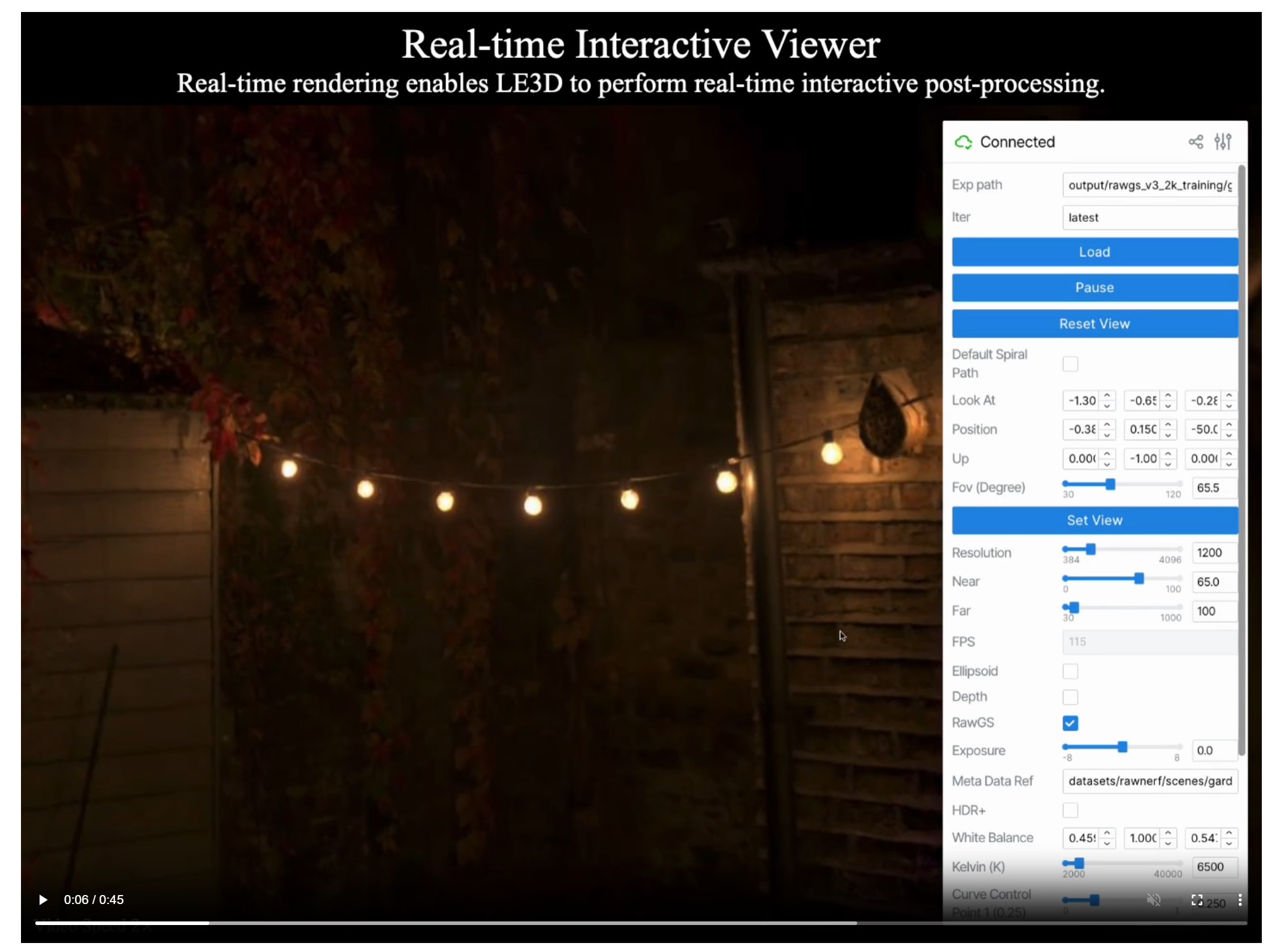

-
HDRI Resources
Read more: HDRI ResourcesText2Light
- https://www.cgtrader.com/free-3d-models/exterior/other/10-free-hdr-panoramas-created-with-text2light-zero-shot
- https://frozenburning.github.io/projects/text2light/
- https://github.com/FrozenBurning/Text2Light
Royalty free links
- https://locationtextures.com/panoramas/
- http://www.noahwitchell.com/freebies
- https://polyhaven.com/hdris
- https://hdrmaps.com/
- https://www.ihdri.com/
- https://hdrihaven.com/
- https://www.domeble.com/
- http://www.hdrlabs.com/sibl/archive.html
- https://www.hdri-hub.com/hdrishop/hdri
- http://noemotionhdrs.net/hdrevening.html
- https://www.openfootage.net/hdri-panorama/
- https://www.zwischendrin.com/en/browse/hdri
Nvidia GauGAN360





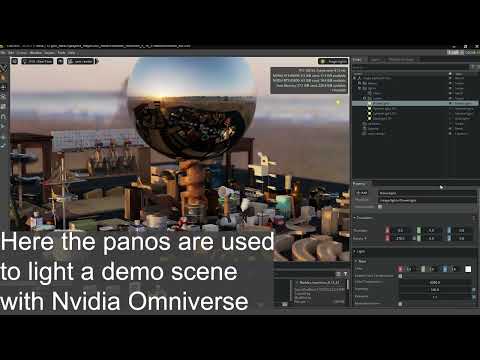













COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Matt Hallett – WAN 2.1 VACE Total Video Control in ComfyUI
-
Decart AI Mirage – The first ever World Transformation Model – turning any video, game, or camera feed into a new digital world, in real time
-
Black Forest Labs released FLUX.1 Kontext
-
Matt Gray – How to generate a profitable business
-
MiniTunes V1 – Free MP3 library app
-
sRGB vs REC709 – An introduction and FFmpeg implementations
-
Scene Referred vs Display Referred color workflows
-
STOP FCC – SAVE THE FREE NET
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
