


COMPOSITION
-
Types of Film Lights and their efficiency – CRI, Color Temperature and Luminous Efficacy
Read more: Types of Film Lights and their efficiency – CRI, Color Temperature and Luminous Efficacynofilmschool.com/types-of-film-lights
“Not every light performs the same way. Lights and lighting are tricky to handle. You have to plan for every circumstance. But the good news is, lighting can be adjusted. Let’s look at different factors that affect lighting in every scene you shoot. “
Use CRI, Luminous Efficacy and color temperature controls to match your needs.
Color Temperature
Color temperature describes the “color” of white light by a light source radiated by a perfect black body at a given temperature measured in degrees Kelvinhttps://www.pixelsham.com/2019/10/18/color-temperature/
CRI
“The Color Rendering Index is a measurement of how faithfully a light source reveals the colors of whatever it illuminates, it describes the ability of a light source to reveal the color of an object, as compared to the color a natural light source would provide. The highest possible CRI is 100. A CRI of 100 generally refers to a perfect black body, like a tungsten light source or the sun. “https://www.studiobinder.com/blog/what-is-color-rendering-index
(more…)


















DESIGN









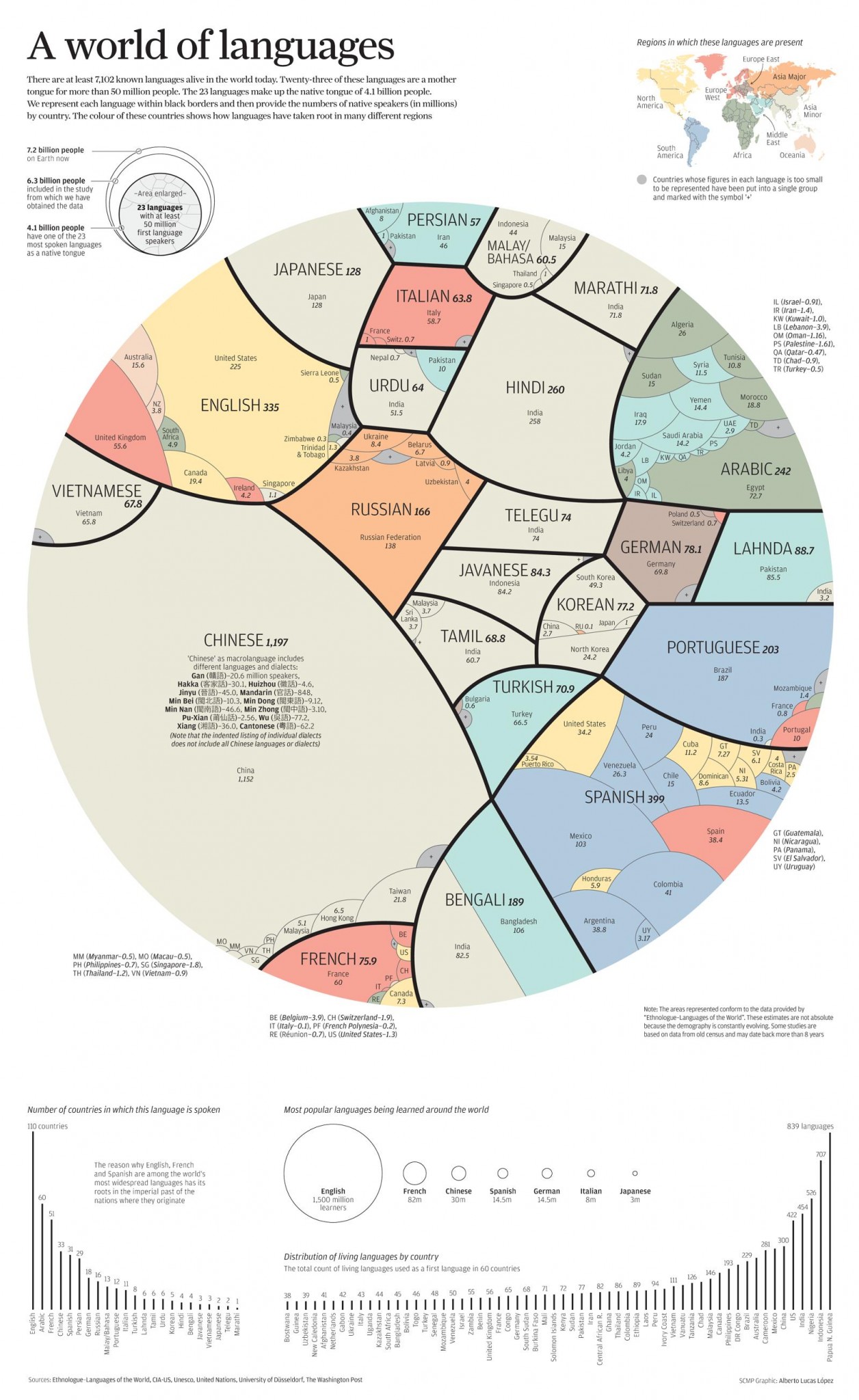



COLOR
-
Scene Referred vs Display Referred color workflows
Read more: Scene Referred vs Display Referred color workflowsDisplay Referred it is tied to the target hardware, as such it bakes color requirements into every type of media output request.
Scene Referred uses a common unified wide gamut and targeting audience through CDL and DI libraries instead.
So that color information stays untouched and only “transformed” as/when needed.



Sources:
– Victor Perez – Color Management Fundamentals & ACES Workflows in Nuke
– https://z-fx.nl/ColorspACES.pdf
– Wicus
-
OLED vs QLED – What TV is better?
Read more: OLED vs QLED – What TV is better?
Supported by LG, Philips, Panasonic and Sony sell the OLED system TVs.
OLED stands for “organic light emitting diode.”
It is a fundamentally different technology from LCD, the major type of TV today.
OLED is “emissive,” meaning the pixels emit their own light.Samsung is branding its best TVs with a new acronym: “QLED”
QLED (according to Samsung) stands for “quantum dot LED TV.”
It is a variation of the common LED LCD, adding a quantum dot film to the LCD “sandwich.”
QLED, like LCD, is, in its current form, “transmissive” and relies on an LED backlight.OLED is the only technology capable of absolute blacks and extremely bright whites on a per-pixel basis. LCD definitely can’t do that, and even the vaunted, beloved, dearly departed plasma couldn’t do absolute blacks.
QLED, as an improvement over OLED, significantly improves the picture quality. QLED can produce an even wider range of colors than OLED, which says something about this new tech. QLED is also known to produce up to 40% higher luminance efficiency than OLED technology. Further, many tests conclude that QLED is far more efficient in terms of power consumption than its predecessor, OLED.
(more…) -
A Brief History of Color in Art
Read more: A Brief History of Color in Artwww.artsy.net/article/the-art-genome-project-a-brief-history-of-color-in-art
Of all the pigments that have been banned over the centuries, the color most missed by painters is likely Lead White.
This hue could capture and reflect a gleam of light like no other, though its production was anything but glamorous. The 17th-century Dutch method for manufacturing the pigment involved layering cow and horse manure over lead and vinegar. After three months in a sealed room, these materials would combine to create flakes of pure white. While scientists in the late 19th century identified lead as poisonous, it wasn’t until 1978 that the United States banned the production of lead white paint.
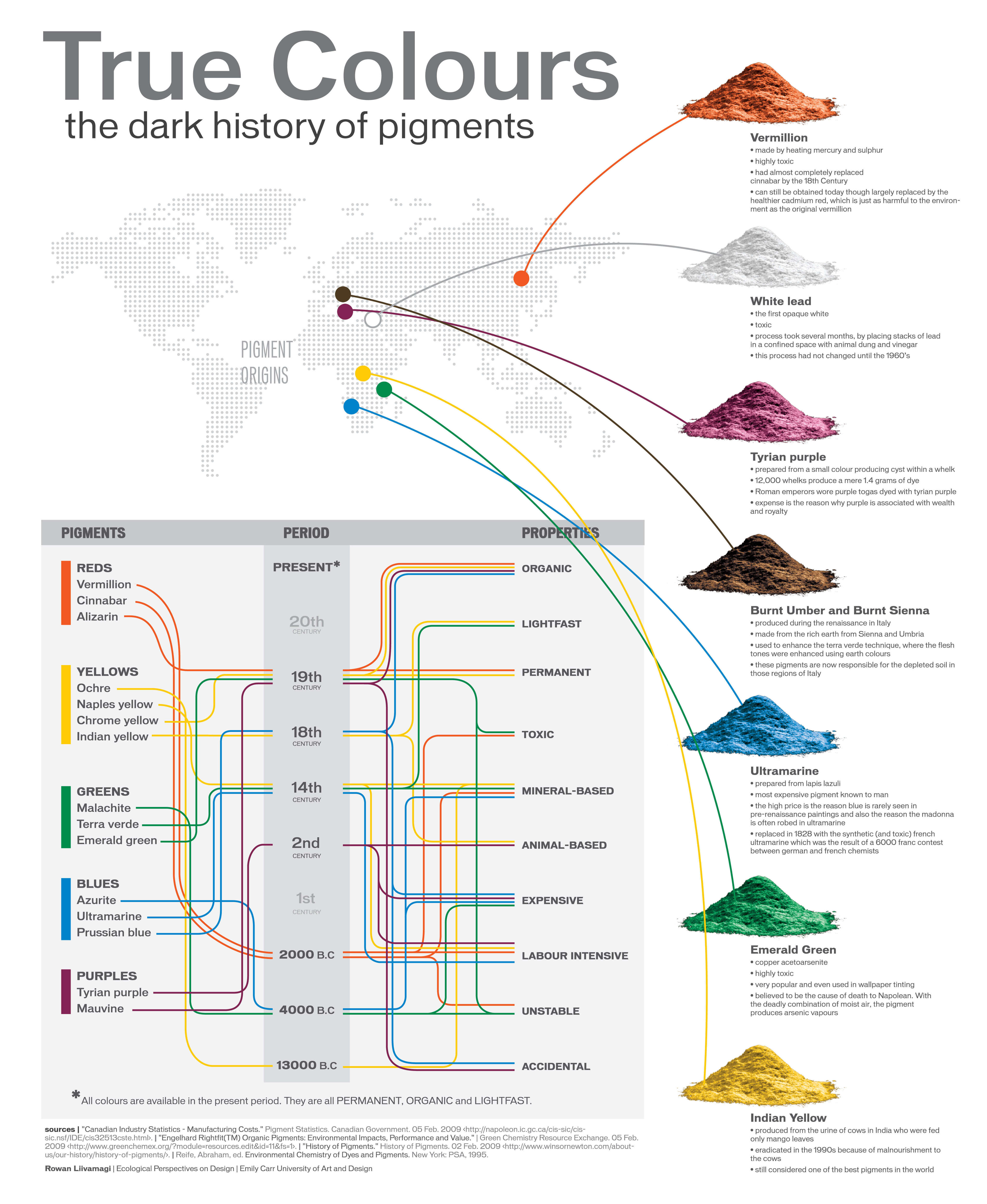
More reading:
www.canva.com/learn/color-meanings/https://www.infogrades.com/history-events-infographics/bizarre-history-of-colors/

-
Victor Perez – The Color Management Handbook for Visual Effects Artists
Read more: Victor Perez – The Color Management Handbook for Visual Effects ArtistsDigital Color Principles, Color Management Fundamentals & ACES Workflows

-
If a blind person gained sight, could they recognize objects previously touched?
Read more: If a blind person gained sight, could they recognize objects previously touched?Blind people who regain their sight may find themselves in a world they don’t immediately comprehend. “It would be more like a sighted person trying to rely on tactile information,” Moore says.
Learning to see is a developmental process, just like learning language, Prof Cathleen Moore continues. “As far as vision goes, a three-and-a-half year old child is already a well-calibrated system.”
-
Anders Langlands – Render Color Spaces
Read more: Anders Langlands – Render Color Spaceshttps://www.colour-science.org/anders-langlands/
This page compares images rendered in Arnold using spectral rendering and different sets of colourspace primaries: Rec.709, Rec.2020, ACES and DCI-P3. The SPD data for the GretagMacbeth Color Checker are the measurements of Noburu Ohta, taken from Mansencal, Mauderer and Parsons (2014) colour-science.org.

-
“Reality” is constructed by your brain. Here’s what that means, and why it matters.
Read more: “Reality” is constructed by your brain. Here’s what that means, and why it matters.“Fix your gaze on the black dot on the left side of this image. But wait! Finish reading this paragraph first. As you gaze at the left dot, try to answer this question: In what direction is the object on the right moving? Is it drifting diagonally, or is it moving up and down?”

What color are these strawberries?

Are A and B the same gray?










LIGHTING
-
domeble – Hi-Resolution CGI Backplates and 360° HDRI
Read more: domeble – Hi-Resolution CGI Backplates and 360° HDRIWhen collecting hdri make sure the data supports basic metadata, such as:
- Iso
- Aperture
- Exposure time or shutter time
- Color temperature
- Color space Exposure value (what the sensor receives of the sun intensity in lux)
- 7+ brackets (with 5 or 6 being the perceived balanced exposure)
In image processing, computer graphics, and photography, high dynamic range imaging (HDRI or just HDR) is a set of techniques that allow a greater dynamic range of luminances (a Photometry measure of the luminous intensity per unit area of light travelling in a given direction. It describes the amount of light that passes through or is emitted from a particular area, and falls within a given solid angle) between the lightest and darkest areas of an image than standard digital imaging techniques or photographic methods. This wider dynamic range allows HDR images to represent more accurately the wide range of intensity levels found in real scenes ranging from direct sunlight to faint starlight and to the deepest shadows.
The two main sources of HDR imagery are computer renderings and merging of multiple photographs, which in turn are known as low dynamic range (LDR) or standard dynamic range (SDR) images. Tone Mapping (Look-up) techniques, which reduce overall contrast to facilitate display of HDR images on devices with lower dynamic range, can be applied to produce images with preserved or exaggerated local contrast for artistic effect. Photography
In photography, dynamic range is measured in Exposure Values (in photography, exposure value denotes all combinations of camera shutter speed and relative aperture that give the same exposure. The concept was developed in Germany in the 1950s) differences or stops, between the brightest and darkest parts of the image that show detail. An increase of one EV or one stop is a doubling of the amount of light.
The human response to brightness is well approximated by a Steven’s power law, which over a reasonable range is close to logarithmic, as described by the Weber�Fechner law, which is one reason that logarithmic measures of light intensity are often used as well.
HDR is short for High Dynamic Range. It’s a term used to describe an image which contains a greater exposure range than the “black” to “white” that 8 or 16-bit integer formats (JPEG, TIFF, PNG) can describe. Whereas these Low Dynamic Range images (LDR) can hold perhaps 8 to 10 f-stops of image information, HDR images can describe beyond 30 stops and stored in 32 bit images.

-
Photography basics: Solid Angle measures
Read more: Photography basics: Solid Angle measureshttp://www.calculator.org/property.aspx?name=solid+angle

A measure of how large the object appears to an observer looking from that point. Thus. A measure for objects in the sky. Useful to retuen the size of the sun and moon… and in perspective, how much of their contribution to lighting. Solid angle can be represented in ‘angular diameter’ as well.
http://en.wikipedia.org/wiki/Solid_angle
http://www.mathsisfun.com/geometry/steradian.html
A solid angle is expressed in a dimensionless unit called a steradian (symbol: sr). By default in terms of the total celestial sphere and before atmospheric’s scattering, the Sun and the Moon subtend fractional areas of 0.000546% (Sun) and 0.000531% (Moon).
http://en.wikipedia.org/wiki/Solid_angle#Sun_and_Moon
On earth the sun is likely closer to 0.00011 solid angle after athmospheric scattering. The sun as perceived from earth has a diameter of 0.53 degrees. This is about 0.000064 solid angle.
http://www.numericana.com/answer/angles.htm
The mean angular diameter of the full moon is 2q = 0.52° (it varies with time around that average, by about 0.009°). This translates into a solid angle of 0.0000647 sr, which means that the whole night sky covers a solid angle roughly one hundred thousand times greater than the full moon.
More info
http://lcogt.net/spacebook/using-angles-describe-positions-and-apparent-sizes-objects
http://amazing-space.stsci.edu/glossary/def.php.s=topic_astronomy
Angular Size
The apparent size of an object as seen by an observer; expressed in units of degrees (of arc), arc minutes, or arc seconds. The moon, as viewed from the Earth, has an angular diameter of one-half a degree.
The angle covered by the diameter of the full moon is about 31 arcmin or 1/2°, so astronomers would say the Moon’s angular diameter is 31 arcmin, or the Moon subtends an angle of 31 arcmin.

-
Vahan Sosoyan MakeHDR – an OpenFX open source plug-in for merging multiple LDR images into a single HDRI
Read more: Vahan Sosoyan MakeHDR – an OpenFX open source plug-in for merging multiple LDR images into a single HDRIhttps://github.com/Sosoyan/make-hdr
Feature notes
- Merge up to 16 inputs with 8, 10 or 12 bit depth processing
- User friendly logarithmic Tone Mapping controls within the tool
- Advanced controls such as Sampling rate and Smoothness
Available at cross platform on Linux, MacOS and Windows Works consistent in compositing applications like Nuke, Fusion, Natron.
NOTE: The goal is to clean the initial individual brackets before or at merging time as much as possible.
This means:- keeping original shooting metadata
- de-fringing
- removing aberration (through camera lens data or automatically)
- at 32 bit
- in ACEScg (or ACES) wherever possible

-
Fast, optimized ‘for’ pixel loops with OpenCV and Python to create tone mapped HDR images
Read more: Fast, optimized ‘for’ pixel loops with OpenCV and Python to create tone mapped HDR imageshttps://pyimagesearch.com/2017/08/28/fast-optimized-for-pixel-loops-with-opencv-and-python/
https://learnopencv.com/exposure-fusion-using-opencv-cpp-python/
Exposure Fusion is a method for combining images taken with different exposure settings into one image that looks like a tone mapped High Dynamic Range (HDR) image.

-
Debayer – A free command line tool to convert camera raw images into scene-linear exr
Read more: Debayer – A free command line tool to convert camera raw images into scene-linear exr
https://github.com/jedypod/debayer
The only required dependency is oiiotool. However other “debayer engines” are also supported.
- OpenImageIO – oiiotool is used for converting debayered tif images to exr.
- Debayer Engines
- RawTherapee – Powerful raw development software used to decode raw images. High quality, good selection of debayer algorithms, and more advanced raw processing like chromatic aberration removal.
- LibRaw – dcraw_emu commandline utility included with LibRaw. Optional alternative for debayer. Simple, fast and effective.
- Darktable – Uses darktable-cli plus an xmp config to process.
- vkdt – uses vkdt-cli to debayer. Pretty experimental still. Uses Vulkan for image processing. Stupidly fast. Pretty limited.









COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Eyeline Labs VChain – Chain-of-Visual-Thought for Reasoning in Video Generation for better AI physics
-
Want to build a start up company that lasts? Think three-layer cake
-
UV maps
-
AnimationXpress.com interviews Daniele Tosti for TheCgCareer.com channel
-
RawTherapee – a free, open source, cross-platform raw image and HDRi processing program
-
Daniele Tosti Interview for the magazine InCG, Taiwan, Issue 28, 201609
-
Embedding frame ranges into Quicktime movies with FFmpeg
-
Convert 2D Images or Text to 3D Models
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
