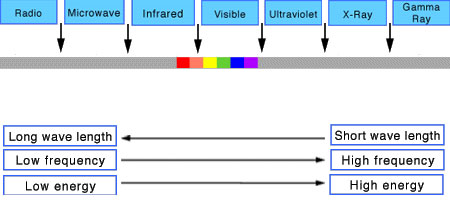
While the human eye has red, green, and blue-sensing cones, those cones are cross-wired in the retina to produce a luminance channel plus a red-green and a blue-yellow channel, and it’s data in that color space (known technically as “LAB”) that goes to the brain. That’s why we can’t perceive a reddish-green or a yellowish-blue, whereas such colors can be represented in the RGB color space used by digital cameras.
The back of the retina is covered in light-sensitive neurons known as cone cells and rod cells. There are three types of cone cells, each sensitive to different ranges of light. These ranges overlap, but for convenience the cones are referred to as blue (short-wavelength), green (medium-wavelength), and red (long-wavelength). The rod cells are primarily used in low-light situations, so we’ll ignore those for now.
When light enters the eye and hits the cone cells, the cones get excited and send signals to the brain through the visual cortex. Different wavelengths of light excite different combinations of cones to varying levels, which generates our perception of color. You can see that the red cones are most sensitive to light, and the blue cones are least sensitive. The sensitivity of green and red cones overlaps for most of the visible spectrum.
Here’s how your brain takes the signals of light intensity from the cones and turns it into color information. To see red or green, your brain finds the difference between the levels of excitement in your red and green cones. This is the red-green channel.
To get “brightness,” your brain combines the excitement of your red and green cones. This creates the luminance, or black-white, channel. To see yellow or blue, your brain then finds the difference between this luminance signal and the excitement of your blue cones. This is the yellow-blue channel.
From the calculations made in the brain along those three channels, we get four basic colors: blue, green, yellow, and red. Seeing blue is what you experience when low-wavelength light excites the blue cones more than the green and red.
Seeing green happens when light excites the green cones more than the red cones. Seeing red happens when only the red cones are excited by high-wavelength light.
Here’s where it gets interesting. Seeing yellow is what happens when BOTH the green AND red cones are highly excited near their peak sensitivity. This is the biggest collective excitement that your cones ever have, aside from seeing pure white.
Notice that yellow occurs at peak intensity in the graph to the right. Further, the lens and cornea of the eye happen to block shorter wavelengths, reducing sensitivity to blue and violet light.
In color technology, color depth also known as bit depth, is either the number of bits used to indicate the color of a single pixel, OR the number of bits used for each color component of a single pixel.
When referring to a pixel, the concept can be defined as bits per pixel (bpp).
When referring to a color component, the concept can be defined as bits per component, bits per channel, bits per color (all three abbreviated bpc), and also bits per pixel component, bits per color channel or bits per sample (bps). Modern standards tend to use bits per component, but historical lower-depth systems used bits per pixel more often.
Color depth is only one aspect of color representation, expressing the precision with which the amount of each primary can be expressed; the other aspect is how broad a range of colors can be expressed (the gamut). The definition of both color precision and gamut is accomplished with a color encoding specification which assigns a digital code value to a location in a color space.
“The Color Rendering Index is a measurement of how faithfully a light source reveals the colors of whatever it illuminates, it describes the ability of a light source to reveal the color of an object, as compared to the color a natural light source would provide. The highest possible CRI is 100. A CRI of 100 generally refers to a perfect black body, like a tungsten light source or the sun. ”
1 to 100% Stepless Dimming, 1500 Lux Brightness at 3.3′
LCD Info Screen. Powered by an L-series battery, D-Tap, or USB-C
Because the light has a variable color range of 3200 to 9500K, when the light is set to 5500K (daylight balanced) both sets of LEDs are on at full, providing the maximum brightness from this fixture when compared to using the light at 3200 or 9500K.
The LCD screen provides information on the fixture’s output as well as the charge state of the battery. The screen also indicates whether the adjustment knob is controlling brightness or color temperature. To switch from brightness to CCT or CCT to brightness, just apply a short press to the adjustment knob.
The included cold shoe ball joint adapter enables mounting the light to your camera’s accessory shoe via the 1/4″-20 threaded hole on the fixture. In addition, the bottom of the cold shoe foot features a 3/8″-16 threaded hole, and includes a 3/8″-16 to 1/4″-20 reducing bushing.
In the retina, photoreceptors, bipolar cells, and horizontal cells work together to process visual information before it reaches the brain. Here’s how each cell type contributes to vision:
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.











































 Local copy:
Local copy: