Size. Mr. White (Harvey Keitel) on the right. Focus. He’s one of the two objects in focus. Lighting. Mr. White is large and in focus and Mr. Pink (Steve Buscemi) is highlighted by a shaft of light. Color. Both are black and white but the read on Mr. White’s shirt now really stands out.
Since spending a lot of time recently with SDXL I’ve since made my way back to SD 1.5
While the models overall have less fidelity. There is just no comparing to the current motion models we have available for animatediff with 1.5 models.
To date this is one of my favorite pieces. Not because I think it’s even the best it can be. But because the workflow adjustments unlocked some very important ideas I can’t wait to try out.
Performance by @silkenkelly and @itxtheballerina on IG
Arminas created this using Juggernaut Xl model and QR Code Monster SDXL ControlNet.
His pipeline: Static Images – Forge UI. Upscaled with Leonardo AI universal upscaler. Animated with Runway ML and Minimax. Video upscale – Topaz Video AI. Composited in Adobe Premiere.
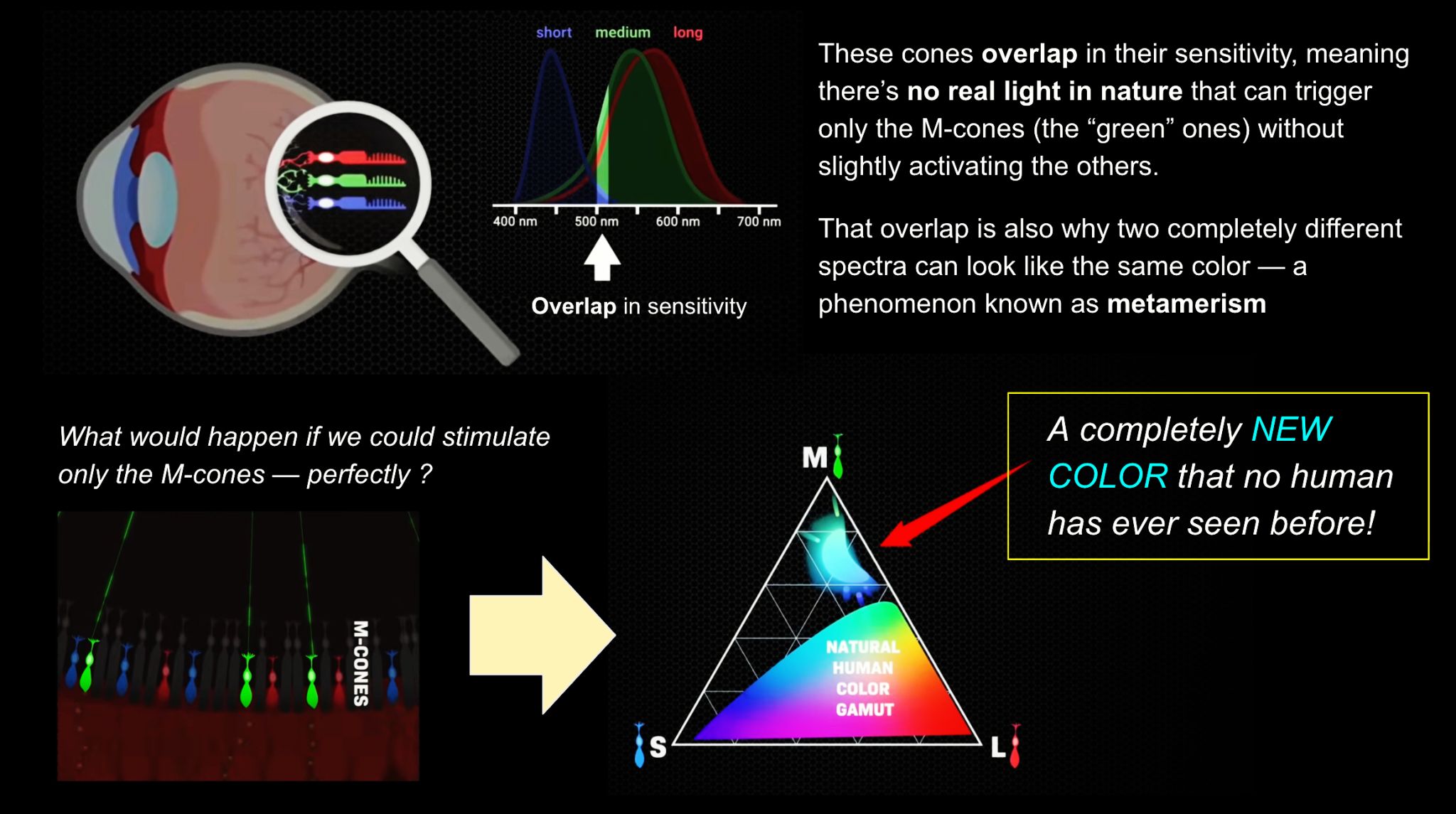
We introduce a principle, Oz, for displaying color imagery: directly controlling the human eye’s photoreceptor activity via cell-by-cell light delivery. Theoretically, novel colors are possible through bypassing the constraints set by the cone spectral sensitivities and activating M cone cells exclusively. In practice, we confirm a partial expansion of colorspace toward that theoretical ideal. Attempting to activate M cones exclusively is shown to elicit a color beyond the natural human gamut, formally measured with color matching by human subjects. They describe the color as blue-green of unprecedented saturation. Further experiments show that subjects perceive Oz colors in image and video form. The prototype targets laser microdoses to thousands of spectrally classified cones under fixational eye motion. These results are proof-of-principle for programmable control over individual photoreceptors at population scale.
Maya blue is a highly unusual pigment because it is a mix of organic indigo and an inorganic clay mineral called palygorskite.
Echoing the color of an azure sky, the indelible pigment was used to accentuate everything from ceramics to human sacrifices in the Late Preclassic period (300 B.C. to A.D. 300).
A team of researchers led by Dean Arnold, an adjunct curator of anthropology at the Field Museum in Chicago, determined that the key to Maya blue was actually a sacred incense called copal. By heating the mixture of indigo, copal and palygorskite over a fire, the Maya produced the unique pigment, he reported at the time.
It lets you load any .cube LUT right in your browser, see the RGB curves, and use a split view on the Granger Test Image to compare the original vs. LUT-applied version in real time — perfect for spotting hue shifts, saturation changes, and contrast tweaks.
A light wave that is vibrating in more than one plane is referred to as unpolarized light. …
Polarized light waves are light waves in which the vibrations occur in a single plane. The process of transforming unpolarized light into polarized light is known as polarization.
The most common use of polarized technology is to reduce lighting complexity on the subject. Details such as glare and hard edges are not removed, but greatly reduced.
Supported by LG, Philips, Panasonic and Sony sell the OLED system TVs. OLED stands for “organic light emitting diode.” It is a fundamentally different technology from LCD, the major type of TV today. OLED is “emissive,” meaning the pixels emit their own light.
Samsung is branding its best TVs with a new acronym: “QLED” QLED (according to Samsung) stands for “quantum dot LED TV.” It is a variation of the common LED LCD, adding a quantum dot film to the LCD “sandwich.” QLED, like LCD, is, in its current form, “transmissive” and relies on an LED backlight.
OLED is the only technology capable of absolute blacks and extremely bright whites on a per-pixel basis. LCD definitely can’t do that, and even the vaunted, beloved, dearly departed plasma couldn’t do absolute blacks.
QLED, as an improvement over OLED, significantly improves the picture quality. QLED can produce an even wider range of colors than OLED, which says something about this new tech. QLED is also known to produce up to 40% higher luminance efficiency than OLED technology. Further, many tests conclude that QLED is far more efficient in terms of power consumption than its predecessor, OLED.
In the retina, photoreceptors, bipolar cells, and horizontal cells work together to process visual information before it reaches the brain. Here’s how each cell type contributes to vision:
A way to approximate complex lighting in ultra realistic renders.
All SH lighting techniques involve replacing parts of standard lighting equations with spherical functions that have been projected into frequency space using the spherical harmonics as a basis.
When collecting hdri make sure the data supports basic metadata, such as:
Iso
Aperture
Exposure time or shutter time
Color temperature
Color space Exposure value (what the sensor receives of the sun intensity in lux)
7+ brackets (with 5 or 6 being the perceived balanced exposure)
In image processing, computer graphics, and photography, high dynamic range imaging (HDRI or just HDR) is a set of techniques that allow a greater dynamic range of luminances (a Photometry measure of the luminous intensity per unit area of light travelling in a given direction. It describes the amount of light that passes through or is emitted from a particular area, and falls within a given solid angle) between the lightest and darkest areas of an image than standard digital imaging techniques or photographic methods. This wider dynamic range allows HDR images to represent more accurately the wide range of intensity levels found in real scenes ranging from direct sunlight to faint starlight and to the deepest shadows.
The two main sources of HDR imagery are computer renderings and merging of multiple photographs, which in turn are known as low dynamic range (LDR) or standard dynamic range (SDR) images. Tone Mapping (Look-up) techniques, which reduce overall contrast to facilitate display of HDR images on devices with lower dynamic range, can be applied to produce images with preserved or exaggerated local contrast for artistic effect. Photography
In photography, dynamic range is measured in Exposure Values (in photography, exposure value denotes all combinations of camera shutter speed and relative aperture that give the same exposure. The concept was developed in Germany in the 1950s) differences or stops, between the brightest and darkest parts of the image that show detail. An increase of one EV or one stop is a doubling of the amount of light.
The human response to brightness is well approximated by a Steven’s power law, which over a reasonable range is close to logarithmic, as described by the Weber�Fechner law, which is one reason that logarithmic measures of light intensity are often used as well.
HDR is short for High Dynamic Range. It’s a term used to describe an image which contains a greater exposure range than the “black” to “white” that 8 or 16-bit integer formats (JPEG, TIFF, PNG) can describe. Whereas these Low Dynamic Range images (LDR) can hold perhaps 8 to 10 f-stops of image information, HDR images can describe beyond 30 stops and stored in 32 bit images.
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.