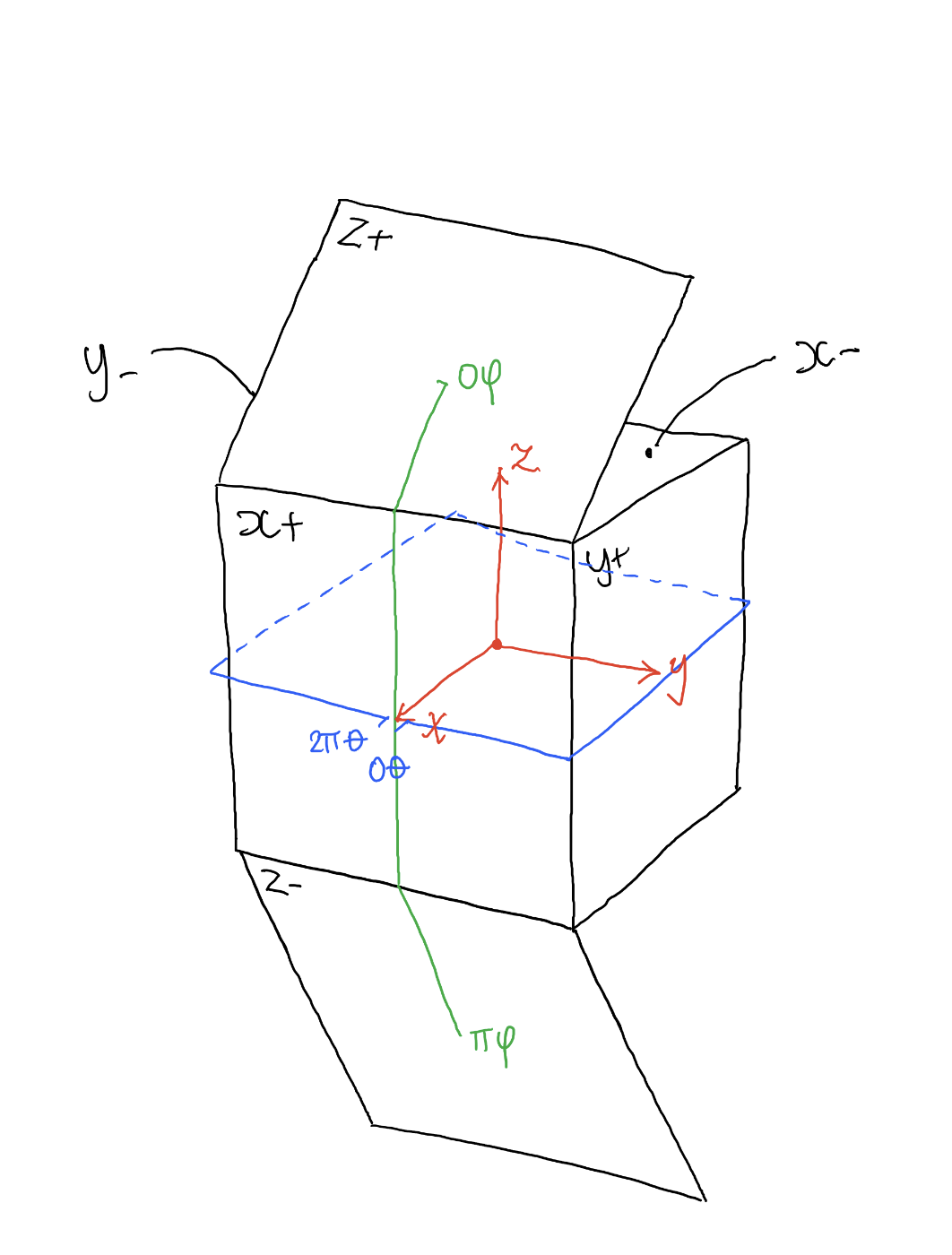
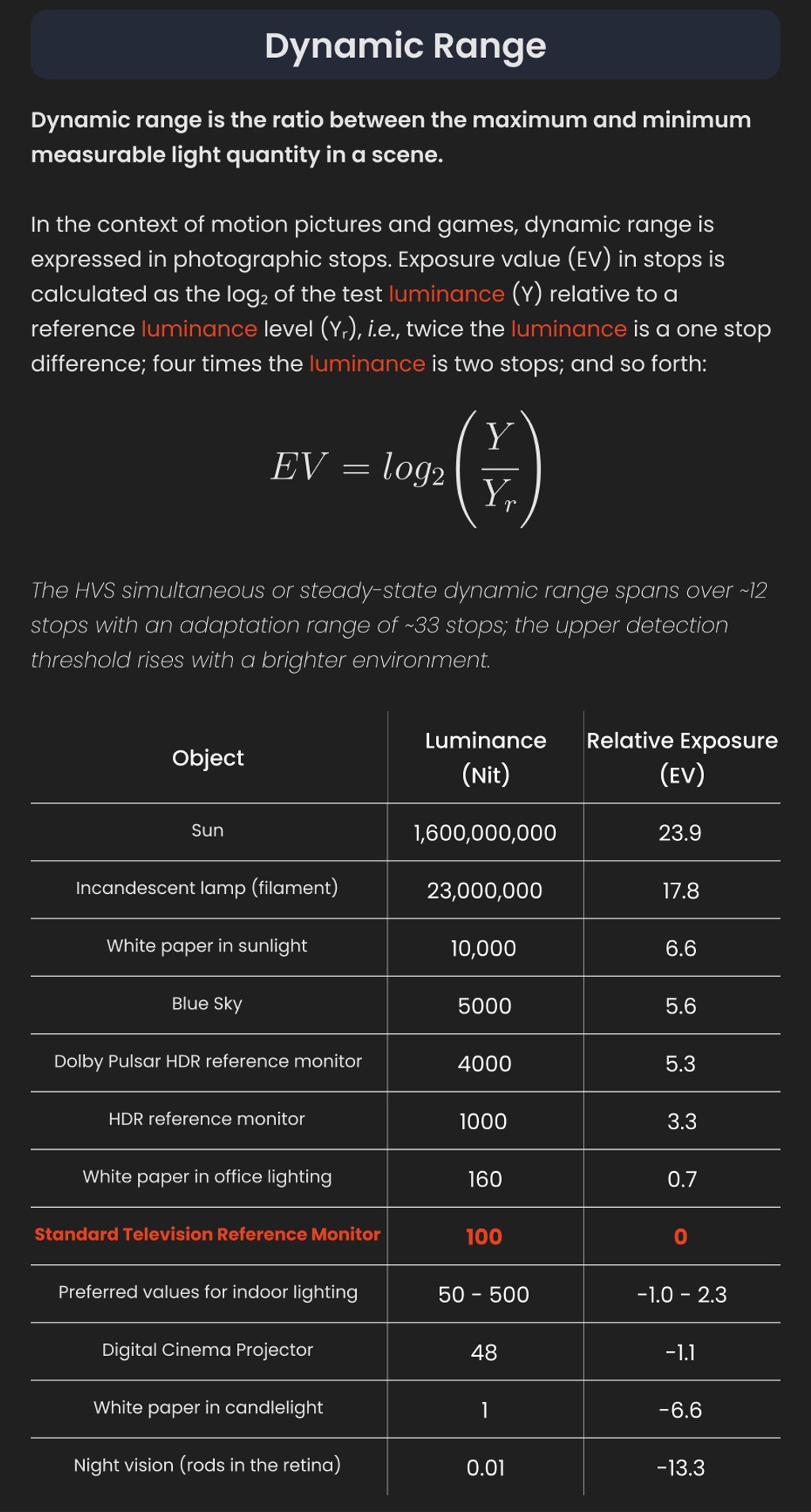
Artificial light sources, not unlike the diverse phases of natural light, vary considerably in their properties. As a result, some lamps render an object’s color better than others do.
The most important criterion for assessing the color-rendering ability of any lamp is its spectral power distribution curve.
Natural daylight varies too much in strength and spectral composition to be taken seriously as a lighting standard for grading and dealing colored stones. For anything to be a standard, it must be constant in its properties, which natural light is not.
For dealers in particular to make the transition from natural light to an artificial light source, that source must offer:
1- A degree of illuminance at least as strong as the common phases of natural daylight.
2- Spectral properties identical or comparable to a phase of natural daylight.
A source combining these two things makes gems appear much the same as when viewed under a given phase of natural light. From the viewpoint of many dealers, this corresponds to a naturalappearance.
The 6000° Kelvin xenon short-arc lamp appears closest to meeting the criteria for a standard light source. Besides the strong illuminance this lamp affords, its spectrum is very similar to CIE standard illuminants of similar color temperature.
“Not every light performs the same way. Lights and lighting are tricky to handle. You have to plan for every circumstance. But the good news is, lighting can be adjusted. Let’s look at different factors that affect lighting in every scene you shoot. “
Use CRI, Luminous Efficacy and color temperature controls to match your needs.
Color Temperature Color temperature describes the “color” of white light by a light source radiated by a perfect black body at a given temperature measured in degrees Kelvin
CRI “The Color Rendering Index is a measurement of how faithfully a light source reveals the colors of whatever it illuminates, it describes the ability of a light source to reveal the color of an object, as compared to the color a natural light source would provide. The highest possible CRI is 100. A CRI of 100 generally refers to a perfect black body, like a tungsten light source or the sun. “
Ethan Roffler I recently had the honor of interviewing this VFX genius and gained great insight into what it takes to work in the entertainment industry. Keep in mind, these questions are coming from an artist’s perspective but can be applied to any creative individual looking for some wisdom from a professional. So grab a drink, sit back, and enjoy this fun and insightful conversation.
Ethan To start, I just wanted to say thank you so much for taking the time for this interview!
Daniele My pleasure. When I started my career I struggled to find help. Even people in the industry at the time were not that helpful. Because of that, I decided very early on that I was going to do exactly the opposite. I spend most of my weekends talking or helping students. ;)
Ethan That’s awesome! I have also come across the same struggle! Just a heads up, this will probably be the most informal interview you’ll ever have haha! Okay, so let’s start with a small introduction!
To measure the contrast ratio you will need a light meter. The process starts with you measuring the main source of light, or the key light.
Get a reading from the brightest area on the face of your subject. Then, measure the area lit by the secondary light, or fill light. To make sense of what you have just measured you have to understand that the information you have just gathered is in F-stops, a measure of light. With each additional F-stop, for example going one stop from f/1.4 to f/2.0, you create a doubling of light. The reverse is also true; moving one stop from f/8.0 to f/5.6 results in a halving of the light.
import math,sys
def Exposure2Intensity(exposure):
exp = float(exposure)
result = math.pow(2,exp)
print(result)
Exposure2Intensity(0)
def Intensity2Exposure(intensity):
inarg = float(intensity)
if inarg == 0:
print("Exposure of zero intensity is undefined.")
return
if inarg < 1e-323:
inarg = max(inarg, 1e-323)
print("Exposure of negative intensities is undefined. Clamping to a very small value instead (1e-323)")
result = math.log(inarg, 2)
print(result)
Intensity2Exposure(0.1)
Why Exposure?
Exposure is a stop value that multiplies the intensity by 2 to the power of the stop. Increasing exposure by 1 results in double the amount of light.
Artists think in “stops.” Doubling or halving brightness is easy math and common in grading and look-dev. Exposure counts doublings in whole stops:
+1 stop = ×2 brightness
−1 stop = ×0.5 brightness
This gives perceptually even controls across both bright and dark values.
Why Intensity?
Intensity is linear. It’s what render engines and compositors expect when:
Summing values
Averaging pixels
Multiplying or filtering pixel data
Use intensity when you need the actual math on pixel/light data.
Formulas (from your Python)
Intensity from exposure: intensity = 2**exposure
Exposure from intensity: exposure = log₂(intensity)
Guardrails:
Intensity must be > 0 to compute exposure.
If intensity = 0 → exposure is undefined.
Clamp tiny values (e.g. 1e−323) before using log₂.
Use Exposure (stops) when…
You want artist-friendly sliders (−5…+5 stops)
Adjusting look-dev or grading in even stops
Matching plates with quick ±1 stop tweaks
Tweening brightness changes smoothly across ranges
Use Intensity (linear) when…
Storing raw pixel/light values
Multiplying textures or lights by a gain
Performing sums, averages, and filters
Feeding values to render engines expecting linear data
Examples
+2 stops → 2**2 = 4.0 (×4)
+1 stop → 2**1 = 2.0 (×2)
0 stop → 2**0 = 1.0 (×1)
−1 stop → 2**(−1) = 0.5 (×0.5)
−2 stops → 2**(−2) = 0.25 (×0.25)
Intensity 0.1 → exposure = log₂(0.1) ≈ −3.32
Rule of thumb
Think in stops (exposure) for controls and matching. Compute in linear (intensity) for rendering and math.
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.