The intricate relationship between the eyes and the brain, often termed the eye-mind connection, reveals that vision is predominantly a cognitive process. This understanding has profound implications for fields such as design, where capturing and maintaining attention is paramount. This essay delves into the nuances of visual perception, the brain’s role in interpreting visual data, and how this knowledge can be applied to effective design strategies.
This cognitive aspect of vision is evident in phenomena such as optical illusions, where the brain interprets visual information in a way that contradicts physical reality. These illusions underscore that what we “see” is not merely a direct recording of the external world but a constructed experience shaped by cognitive processes.
Understanding the cognitive nature of vision is crucial for effective design. Designers must consider how the brain processes visual information to create compelling and engaging visuals. This involves several key principles:
“Memory colors are colors that are universally associated with specific objects, elements or scenes in our environment. They are the colors that we expect to see in specific situations: these colors are based on our expectation of how certain objects should look based on our past experiences and memories.
For instance, we associate specific hues, saturation and brightness values with human skintones and a slight variation can significantly affect the way we perceive a scene.
Similarly, we expect blue skies to have a particular hue, green trees to be a specific shade and so on.
Memory colors live inside of our brains and we often impose them onto what we see. By considering them during the grading process, the resulting image will be more visually appealing and won’t distract the viewer from the intended message of the story. Even a slight deviation from memory colors in a movie can create a sense of discordance, ultimately detracting from the viewer’s experience.”
This help’s us understand the composition of components in/on solar system bodies.
Dips in the observed light spectrum, also known as, lines of absorption occur as gasses absorb energy from light at specific points along the light spectrum.
These dips or darkened zones (lines of absorption) leave a finger print which identify elements and compounds.
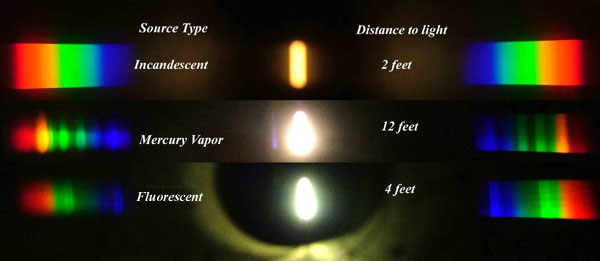
In this image the dark absorption bands appear as lines of emission which occur as the result of emitted not reflected (absorbed) light.
RGBW (RGB + White) LED strip uses a 4-in-1 LED chip made up of red, green, blue, and white.
RGBWW (RGB + White + Warm White) LED strip uses either a 5-in-1 LED chip with red, green, blue, white, and warm white for color mixing. The only difference between RGBW and RGBWW is the intensity of the white color. The term RGBCCT consists of RGB and CCT. CCT (Correlated Color Temperature) means that the color temperature of the led strip light can be adjusted to change between warm white and white. Thus, RGBWW strip light is another name of RGBCCT strip.
RGBCW is the acronym for Red, Green, Blue, Cold, and Warm. These 5-in-1 chips are used in supper bright smart LED lighting products
Supported by LG, Philips, Panasonic and Sony sell the OLED system TVs. OLED stands for “organic light emitting diode.” It is a fundamentally different technology from LCD, the major type of TV today. OLED is “emissive,” meaning the pixels emit their own light.
Samsung is branding its best TVs with a new acronym: “QLED” QLED (according to Samsung) stands for “quantum dot LED TV.” It is a variation of the common LED LCD, adding a quantum dot film to the LCD “sandwich.” QLED, like LCD, is, in its current form, “transmissive” and relies on an LED backlight.
OLED is the only technology capable of absolute blacks and extremely bright whites on a per-pixel basis. LCD definitely can’t do that, and even the vaunted, beloved, dearly departed plasma couldn’t do absolute blacks.
QLED, as an improvement over OLED, significantly improves the picture quality. QLED can produce an even wider range of colors than OLED, which says something about this new tech. QLED is also known to produce up to 40% higher luminance efficiency than OLED technology. Further, many tests conclude that QLED is far more efficient in terms of power consumption than its predecessor, OLED.
Basically, gamma is the relationship between the brightness of a pixel as it appears on the screen, and the numerical value of that pixel. Generally Gamma is just about defining relationships.
Three main types: – Image Gamma encoded in images – Display Gammas encoded in hardware and/or viewing time – System or Viewing Gamma which is the net effect of all gammas when you look back at a final image. In theory this should flatten back to 1.0 gamma.
To measure the contrast ratio you will need a light meter. The process starts with you measuring the main source of light, or the key light.
Get a reading from the brightest area on the face of your subject. Then, measure the area lit by the secondary light, or fill light. To make sense of what you have just measured you have to understand that the information you have just gathered is in F-stops, a measure of light. With each additional F-stop, for example going one stop from f/1.4 to f/2.0, you create a doubling of light. The reverse is also true; moving one stop from f/8.0 to f/5.6 results in a halving of the light.
The power output of a light source is measured using the unit of watts W. This is a direct measure to calculate how much power the light is going to drain from your socket and it is not relatable to the light brightness itself.
The amount of energy emitted from it per second. That energy comes out in a form of photons which we can crudely represent with rays of light coming out of the source. The higher the power the more rays emitted from the source in a unit of time.
Not all energy emitted is visible to the human eye, so we often rely on photometric measurements, which takes in account the sensitivity of human eye to different wavelenghts
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.

























































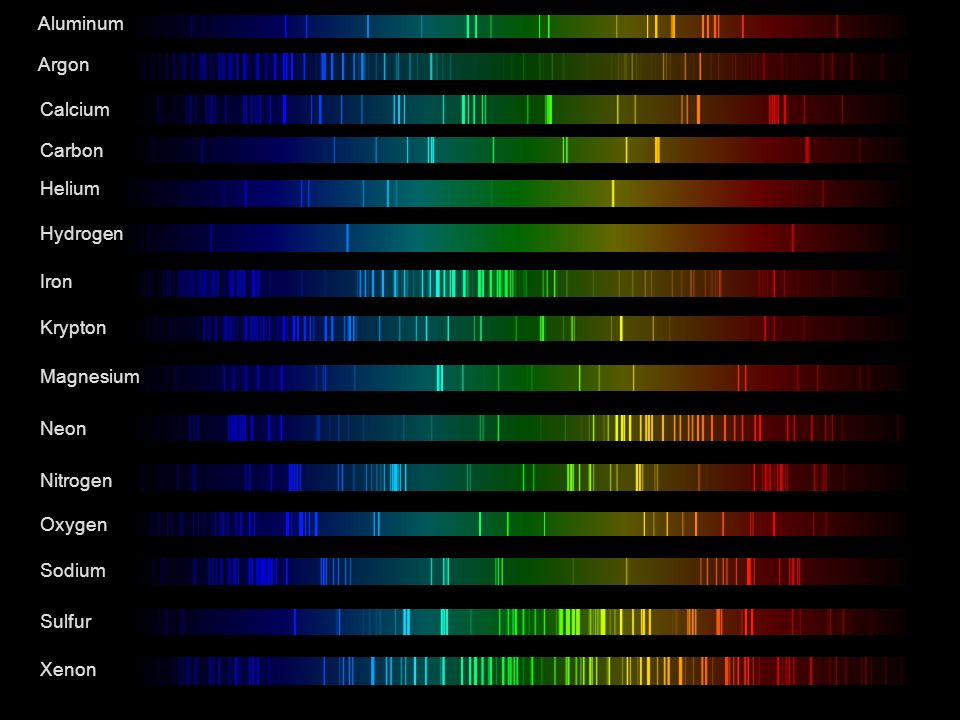 Lines of emission
Lines of emission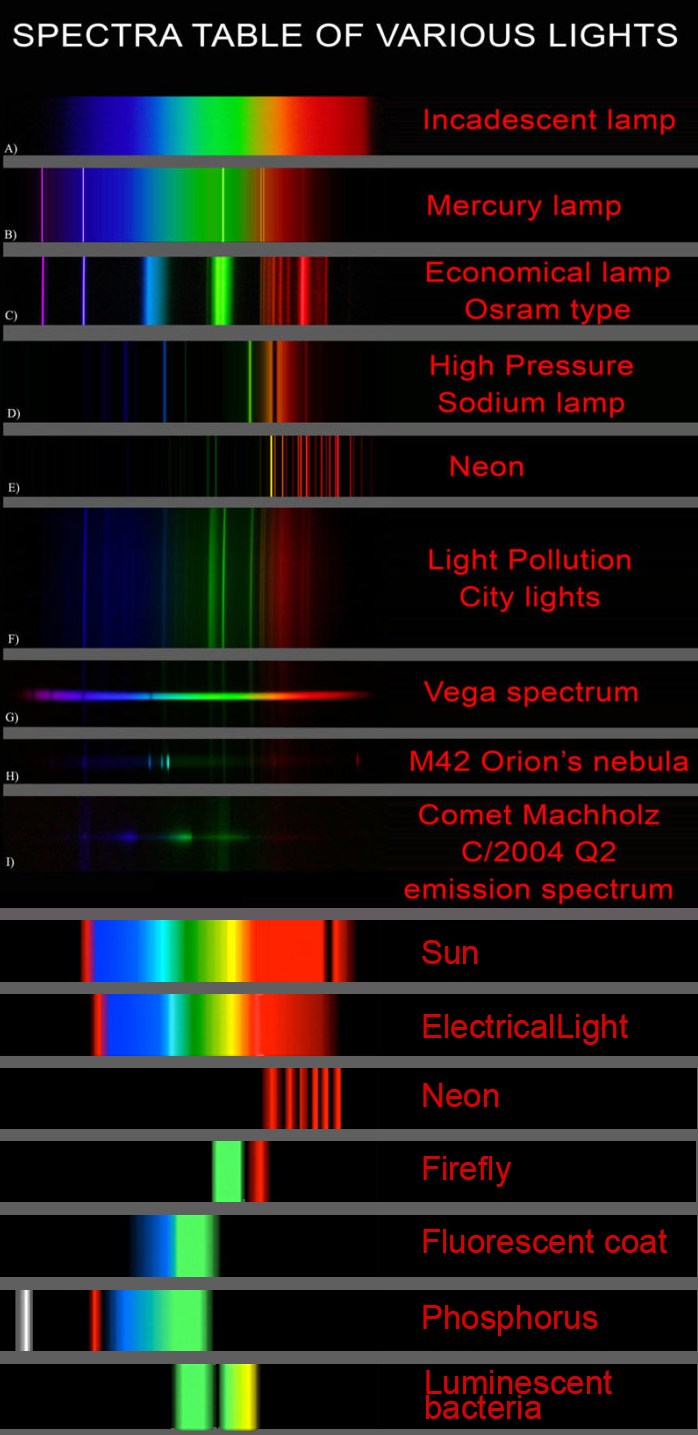















![[gamma correction test]](http://www.madore.org/~david/misc/color/gammatest.png "sRGB gamma correction test")



















