Depth of field is the range within which focusing is resolved in a photo.
Aperture has a huge affect on to the depth of field.
Changing the f-stops (f/#) of a lens will change aperture and as such the DOF.
f-stops are a just certain number which is telling you the size of the aperture. That’s how f-stop is related to aperture (and DOF).
If you increase f-stops, it will increase DOF, the area in focus (and decrease the aperture). On the other hand, decreasing the f-stop it will decrease DOF (and increase the aperture).
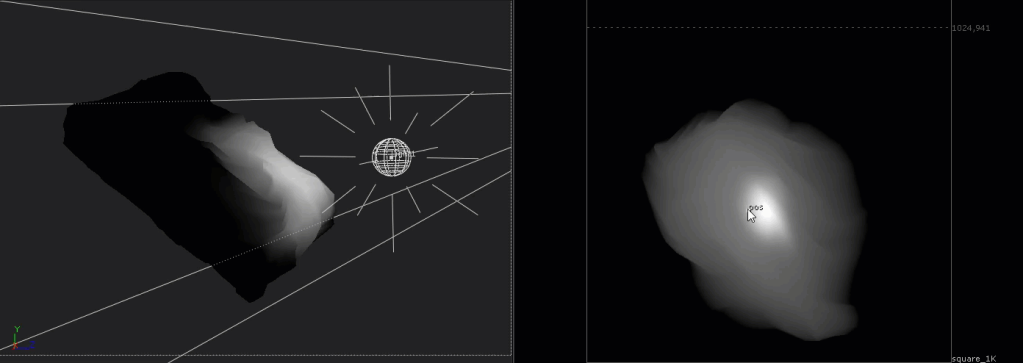
The red cone in the figure is an angular representation of the resolution of the system. Versus the dotted lines, which indicate the aperture coverage. Where the lines of the two cones intersect defines the total range of the depth of field.
This image explains why the longer the depth of field, the greater the range of clarity.
nearly 140 statues at the booth from licenses including DC Comics, Lord of the Rings, Uncharted, The Last of Us, Bloodborne, Demon Souls, God of War, Jurassic Park, Godzilla, Predator, Aliens, Transformers, Berserk, Evangelion, My Hero Academia, Chainsaw Man, Attack on Titan, the DC movie universe, X-Men, Spider-man and much more
The Manuka rendering architecture has been designed in the spirit of the classic reyes rendering architecture. In its core, reyes is based on stochastic rasterisation of micropolygons, facilitating depth of field, motion blur, high geometric complexity,and programmable shading.
This is commonly achieved with Monte Carlo path tracing, using a paradigm often called shade-on-hit, in which the renderer alternates tracing rays with running shaders on the various ray hits. The shaders take the role of generating the inputs of the local material structure which is then used bypath sampling logic to evaluate contributions and to inform what further rays to cast through the scene.
Over the years, however, the expectations have risen substantially when it comes to image quality. Computing pictures which are indistinguishable from real footage requires accurate simulation of light transport, which is most often performed using some variant of Monte Carlo path tracing. Unfortunately this paradigm requires random memory accesses to the whole scene and does not lend itself well to a rasterisation approach at all.
Manuka is both a uni-directional and bidirectional path tracer and encompasses multiple importance sampling (MIS). Interestingly, and importantly for production character skin work, it is the first major production renderer to incorporate spectral MIS in the form of a new ‘Hero Spectral Sampling’ technique, which was recently published at Eurographics Symposium on Rendering 2014.
Manuka propose a shade-before-hit paradigm in-stead and minimise I/O strain (and some memory costs) on the system, leveraging locality of reference by running pattern generation shaders before we execute light transport simulation by path sampling, “compressing” any bvh structure as needed, and as such also limiting duplication of source data.
The difference with reyes is that instead of baking colors into the geometry like in Reyes, manuka bakes surface closures. This means that light transport is still calculated with path tracing, but all texture lookups etc. are done up-front and baked into the geometry.
The main drawback with this method is that geometry has to be tessellated to its highest, stable topology before shading can be evaluated properly. As such, the high cost to first pixel. Even a basic 4 vertices square becomes a much more complex model with this approach.
Manuka use the RenderMan Shading Language (rsl) for programmable shading [Pixar Animation Studios 2015], but we do not invoke rsl shaders when intersecting a ray with a surface (often called shade-on-hit). Instead, we pre-tessellate and pre-shade all the input geometry in the front end of the renderer.
This way, we can efficiently order shading computations to sup-port near-optimal texture locality, vectorisation, and parallelism. This system avoids repeated evaluation of shaders at the same surface point, and presents a minimal amount of memory to be accessed during light transport time. An added benefit is that the acceleration structure for ray tracing (abounding volume hierarchy, bvh) is built once on the final tessellated geometry, which allows us to ray trace more efficiently than multi-level bvhs and avoids costly caching of on-demand tessellated micropolygons and the associated scheduling issues.
For the shading reasons above, in terms of AOVs, the studio approach is to succeed at combining complex shading with ray paths in the render rather than pass a multi-pass render to compositing.
For the Spectral Rendering component. The light transport stage is fully spectral, using a continuously sampled wavelength which is traced with each path and used to apply the spectral camera sensitivity of the sensor. This allows for faithfully support any degree of observer metamerism as the camera footage they are intended to match as well as complex materials which require wavelength dependent phenomena such as diffraction, dispersion, interference, iridescence, or chromatic extinction and Rayleigh scattering in participating media.
As opposed to the original reyes paper, we use bilinear interpolation of these bsdf inputs later when evaluating bsdfs per pathv ertex during light transport4. This improves temporal stability of geometry which moves very slowly with respect to the pixel raster
In terms of the pipeline, everything rendered at Weta was already completely interwoven with their deep data pipeline. Manuka very much was written with deep data in mind. Here, Manuka not so much extends the deep capabilities, rather it fully matches the already extremely complex and powerful setup Weta Digital already enjoy with RenderMan. For example, an ape in a scene can be selected, its ID is available and a NUKE artist can then paint in 3D say a hand and part of the way up the neutral posed ape.
We called our system Manuka, as a respectful nod to reyes: we had heard a story froma former ILM employee about how reyes got its name from how fond the early Pixar people were of their lunches at Point Reyes, and decided to name our system after our surrounding natural environment, too. Manuka is a kind of tea tree very common in New Zealand which has very many very small leaves, in analogy to micropolygons ina tree structure for ray tracing. It also happens to be the case that Weta Digital’s main site is on Manuka Street.
“The Color Rendering Index is a measurement of how faithfully a light source reveals the colors of whatever it illuminates, it describes the ability of a light source to reveal the color of an object, as compared to the color a natural light source would provide. The highest possible CRI is 100. A CRI of 100 generally refers to a perfect black body, like a tungsten light source or the sun. ”
Size. Mr. White (Harvey Keitel) on the right. Focus. He’s one of the two objects in focus. Lighting. Mr. White is large and in focus and Mr. Pink (Steve Buscemi) is highlighted by a shaft of light. Color. Both are black and white but the read on Mr. White’s shirt now really stands out.
In HD we often refer to the range of available colors as a color gamut. Such a color gamut is typically plotted on a two-dimensional diagram, called a CIE chart, as shown in at the top of this blog. Each color is characterized by its x/y coordinates.
Good enough for government work, perhaps. But for HDR, with its higher luminance levels and wider color, the gamut becomes three-dimensional.
For HDR the color gamut therefore becomes a characteristic we now call the color volume. It isn’t easy to show color volume on a two-dimensional medium like the printed page or a computer screen, but one method is shown below. As the luminance becomes higher, the picture eventually turns to white. As it becomes darker, it fades to black. The traditional color gamut shown on the CIE chart is simply a slice through this color volume at a selected luminance level, such as 50%.
Three different color volumes—we still refer to them as color gamuts though their third dimension is important—are currently the most significant. The first is BT.709 (sometimes referred to as Rec.709), the color gamut used for pre-UHD/HDR formats, including standard HD.
The largest is known as BT.2020; it encompasses (roughly) the range of colors visible to the human eye (though ET might find it insufficient!).
Between these two is the color gamut used in digital cinema, known as DCI-P3.
One problem with sRGB is that in a gradient between blue and white, it becomes a bit purple in the middle of the transition. That’s because sRGB really isn’t created to mimic how the eye sees colors; rather, it is based on how CRT monitors work. That means it works with certain frequencies of red, green, and blue, and also the non-linear coding called gamma. It’s a miracle it works as well as it does, but it’s not connected to color perception. When using those tools, you sometimes get surprising results, like purple in the gradient.
There were also attempts to create simple models matching human perception based on XYZ, but as it turned out, it’s not possible to model all color vision that way. Perception of color is incredibly complex and depends, among other things, on whether it is dark or light in the room and the background color it is against. When you look at a photograph, it also depends on what you think the color of the light source is. The dress is a typical example of color vision being very context-dependent. It is almost impossible to model this perfectly.
I based Oklab on two other color spaces, CIECAM16 and IPT. I used the lightness and saturation prediction from CIECAM16, which is a color appearance model, as a target. I actually wanted to use the datasets used to create CIECAM16, but I couldn’t find them.
IPT was designed to have better hue uniformity. In experiments, they asked people to match light and dark colors, saturated and unsaturated colors, which resulted in a dataset for which colors, subjectively, have the same hue. IPT has a few other issues but is the basis for hue in Oklab.
In the Munsell color system, colors are described with three parameters, designed to match the perceived appearance of colors: Hue, Chroma and Value. The parameters are designed to be independent and each have a uniform scale. This results in a color solid with an irregular shape. The parameters are designed to be independent and each have a uniform scale. This results in a color solid with an irregular shape. Modern color spaces and models, such as CIELAB, Cam16 and Björn Ottosson own Oklab, are very similar in their construction.
By far the most used color spaces today for color picking are HSL and HSV, two representations introduced in the classic 1978 paper “Color Spaces for Computer Graphics”. HSL and HSV designed to roughly correlate with perceptual color properties while being very simple and cheap to compute.
Today HSL and HSV are most commonly used together with the sRGB color space.
One of the main advantages of HSL and HSV over the different Lab color spaces is that they map the sRGB gamut to a cylinder. This makes them easy to use since all parameters can be changed independently, without the risk of creating colors outside of the target gamut.
The main drawback on the other hand is that their properties don’t match human perception particularly well.
Reconciling these conflicting goals perfectly isn’t possible, but given that HSV and HSL don’t use anything derived from experiments relating to human perception, creating something that makes a better tradeoff does not seem unreasonable.
With this new lightness estimate, we are ready to look into the construction of Okhsv and Okhsl.
Ethan Roffler I recently had the honor of interviewing this VFX genius and gained great insight into what it takes to work in the entertainment industry. Keep in mind, these questions are coming from an artist’s perspective but can be applied to any creative individual looking for some wisdom from a professional. So grab a drink, sit back, and enjoy this fun and insightful conversation.
Ethan To start, I just wanted to say thank you so much for taking the time for this interview!
Daniele My pleasure. When I started my career I struggled to find help. Even people in the industry at the time were not that helpful. Because of that, I decided very early on that I was going to do exactly the opposite. I spend most of my weekends talking or helping students. ;)
Ethan That’s awesome! I have also come across the same struggle! Just a heads up, this will probably be the most informal interview you’ll ever have haha! Okay, so let’s start with a small introduction!
A measure of how large the object appears to an observer looking from that point. Thus. A measure for objects in the sky. Useful to retuen the size of the sun and moon… and in perspective, how much of their contribution to lighting. Solid angle can be represented in ‘angular diameter’ as well.
A solid angle is expressed in a dimensionless unit called a steradian (symbol: sr). By default in terms of the total celestial sphere and before atmospheric’s scattering, the Sun and the Moon subtend fractional areas of 0.000546% (Sun) and 0.000531% (Moon).
On earth the sun is likely closer to 0.00011 solid angle after athmospheric scattering. The sun as perceived from earth has a diameter of 0.53 degrees. This is about 0.000064 solid angle.
The mean angular diameter of the full moon is 2q = 0.52° (it varies with time around that average, by about 0.009°). This translates into a solid angle of 0.0000647 sr, which means that the whole night sky covers a solid angle roughly one hundred thousand times greater than the full moon.
The apparent size of an object as seen by an observer; expressed in units of degrees (of arc), arc minutes, or arc seconds. The moon, as viewed from the Earth, has an angular diameter of one-half a degree.
The angle covered by the diameter of the full moon is about 31 arcmin or 1/2°, so astronomers would say the Moon’s angular diameter is 31 arcmin, or the Moon subtends an angle of 31 arcmin.
In the retina, photoreceptors, bipolar cells, and horizontal cells work together to process visual information before it reaches the brain. Here’s how each cell type contributes to vision:
The power output of a light source is measured using the unit of watts W. This is a direct measure to calculate how much power the light is going to drain from your socket and it is not relatable to the light brightness itself.
The amount of energy emitted from it per second. That energy comes out in a form of photons which we can crudely represent with rays of light coming out of the source. The higher the power the more rays emitted from the source in a unit of time.
Not all energy emitted is visible to the human eye, so we often rely on photometric measurements, which takes in account the sensitivity of human eye to different wavelenghts
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.