Disco Diffusion (DD) is a Google Colab Notebook which leverages an AI Image generating technique called CLIP-Guided Diffusion to allow you to create compelling and beautiful images from just text inputs. Created by Somnai, augmented by Gandamu, and building on the work of RiversHaveWings, nshepperd, and many others.
Colour is an open-source Python package providing a comprehensive number of algorithms and datasets for colour science. It is freely available under the BSD-3-Clause terms.
In color technology, color depth also known as bit depth, is either the number of bits used to indicate the color of a single pixel, OR the number of bits used for each color component of a single pixel.
When referring to a pixel, the concept can be defined as bits per pixel (bpp).
When referring to a color component, the concept can be defined as bits per component, bits per channel, bits per color (all three abbreviated bpc), and also bits per pixel component, bits per color channel or bits per sample (bps). Modern standards tend to use bits per component, but historical lower-depth systems used bits per pixel more often.
Color depth is only one aspect of color representation, expressing the precision with which the amount of each primary can be expressed; the other aspect is how broad a range of colors can be expressed (the gamut). The definition of both color precision and gamut is accomplished with a color encoding specification which assigns a digital code value to a location in a color space.
Spectralon is a teflon-based pressed powderthat comes closest to being a pure Lambertian diffuse material that reflects 100% of all light. If we take an HDR photograph of the Spectralon alongside the material to be measured, we can derive thediffuse albedo of that material.
The process to capture diffuse reflectance is very similar to the one outlined by Hable.
1. We put a linear polarizing filter in front of the camera lens and a second linear polarizing filterin front of a modeling light or a flash such that the two filters are oriented perpendicular to eachother, i.e. cross polarized.
2. We place Spectralon close to and parallel with the material we are capturing and take brack-eted shots of the setup7. Typically, we’ll take nine photographs, from -4EV to +4EV in 1EVincrements.
3. We convert the bracketed shots to a linear HDR image. We found that many HDR packagesdo not produce an HDR image in which the pixel values are linear. PTGui is an example of apackage which does generate a linear HDR image. At this point, because of the cross polarization,the image is one of surface diffuse response.
4. We open the file in Photoshop and normalize the image by color picking the Spectralon, filling anew layer with that color and setting that layer to “Divide”. This sets the Spectralon to 1 in theimage. All other color values are relative to this so we can consider them as diffuse albedo.
Blind people who regain their sight may find themselves in a world they don’t immediately comprehend. “It would be more like a sighted person trying to rely on tactile information,” Moore says.
Learning to see is a developmental process, just like learning language, Prof Cathleen Moore continues. “As far as vision goes, a three-and-a-half year old child is already a well-calibrated system.”
Most software around us today are decent at accurately displaying colors. Processing of colors is another story unfortunately, and is often done badly.
To understand what the problem is, let’s start with an example of three ways of blending green and magenta:
Perceptual blend – A smooth transition using a model designed to mimic human perception of color. The blending is done so that the perceived brightness and color varies smoothly and evenly.
Linear blend – A model for blending color based on how light behaves physically. This type of blending can occur in many ways naturally, for example when colors are blended together by focus blur in a camera or when viewing a pattern of two colors at a distance.
sRGB blend – This is how colors would normally be blended in computer software, using sRGB to represent the colors.
Let’s look at some more examples of blending of colors, to see how these problems surface more practically. The examples use strong colors since then the differences are more pronounced. This is using the same three ways of blending colors as the first example.
Instead of making it as easy as possible to work with color, most software make it unnecessarily hard, by doing image processing with representations not designed for it. Approximating the physical behavior of light with linear RGB models is one easy thing to do, but more work is needed to create image representations tailored for image processing and human perception.
This help’s us understand the composition of components in/on solar system bodies.
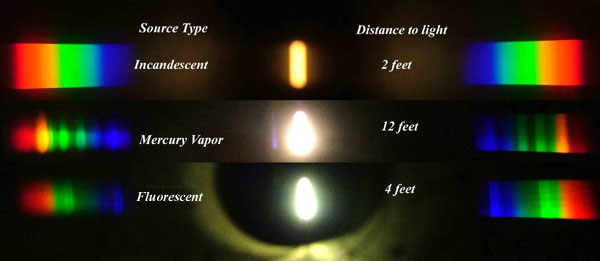
Dips in the observed light spectrum, also known as, lines of absorption occur as gasses absorb energy from light at specific points along the light spectrum.
These dips or darkened zones (lines of absorption) leave a finger print which identify elements and compounds.
In this image the dark absorption bands appear as lines of emission which occur as the result of emitted not reflected (absorbed) light.
The power output of a light source is measured using the unit of watts W. This is a direct measure to calculate how much power the light is going to drain from your socket and it is not relatable to the light brightness itself.
The amount of energy emitted from it per second. That energy comes out in a form of photons which we can crudely represent with rays of light coming out of the source. The higher the power the more rays emitted from the source in a unit of time.
Not all energy emitted is visible to the human eye, so we often rely on photometric measurements, which takes in account the sensitivity of human eye to different wavelenghts
As Einstein showed us, light and matter and just aspects of the same thing. Matter is just frozen light. And light is matter on the move. Albert Einstein’s most famous equation says that energy and matter are two sides of the same coin. How does one become the other?
Relativity requires that the faster an object moves, the more mass it appears to have. This means that somehow part of the energy of the car’s motion appears to transform into mass. Hence the origin of Einstein’s equation. How does that happen? We don’t really know. We only know that it does.
Matter is 99.999999999999 percent empty space. Not only do the atom and solid matter consist mainly of empty space, it is the same in outer space
The quantum theory researchers discovered the answer: Not only do particles consist of energy, but so does the space between. This is the so-called zero-point energy. Therefore it is true: Everything consists of energy.
Energy is the basis of material reality. Every type of particle is conceived of as a quantum vibration in a field: Electrons are vibrations in electron fields, protons vibrate in a proton field, and so on. Everything is energy, and everything is connected to everything else through fields.
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.



































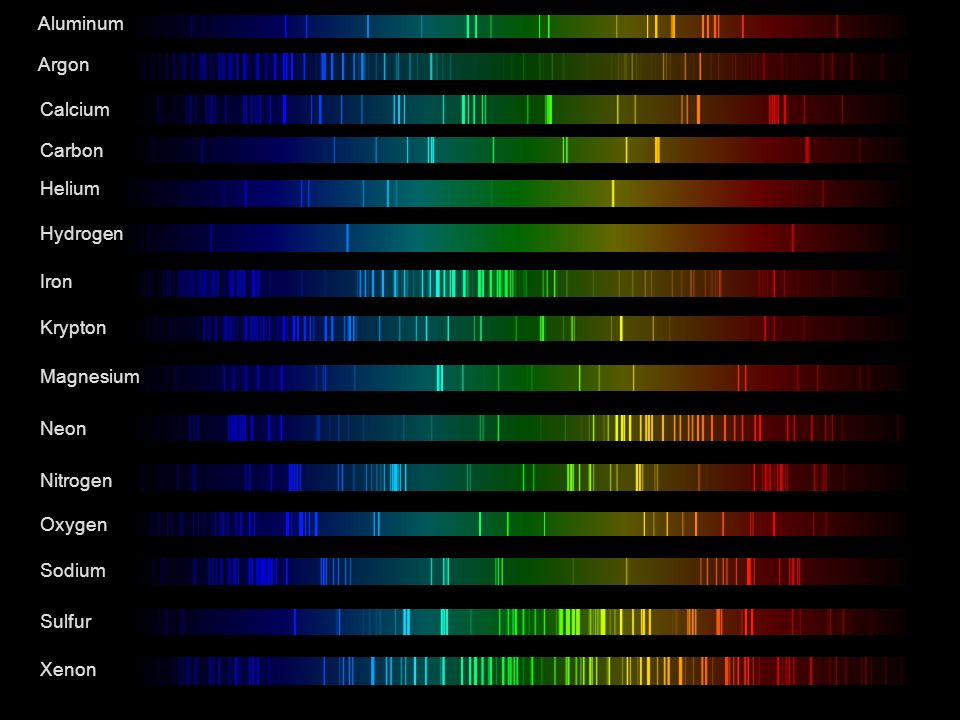 Lines of emission
Lines of emission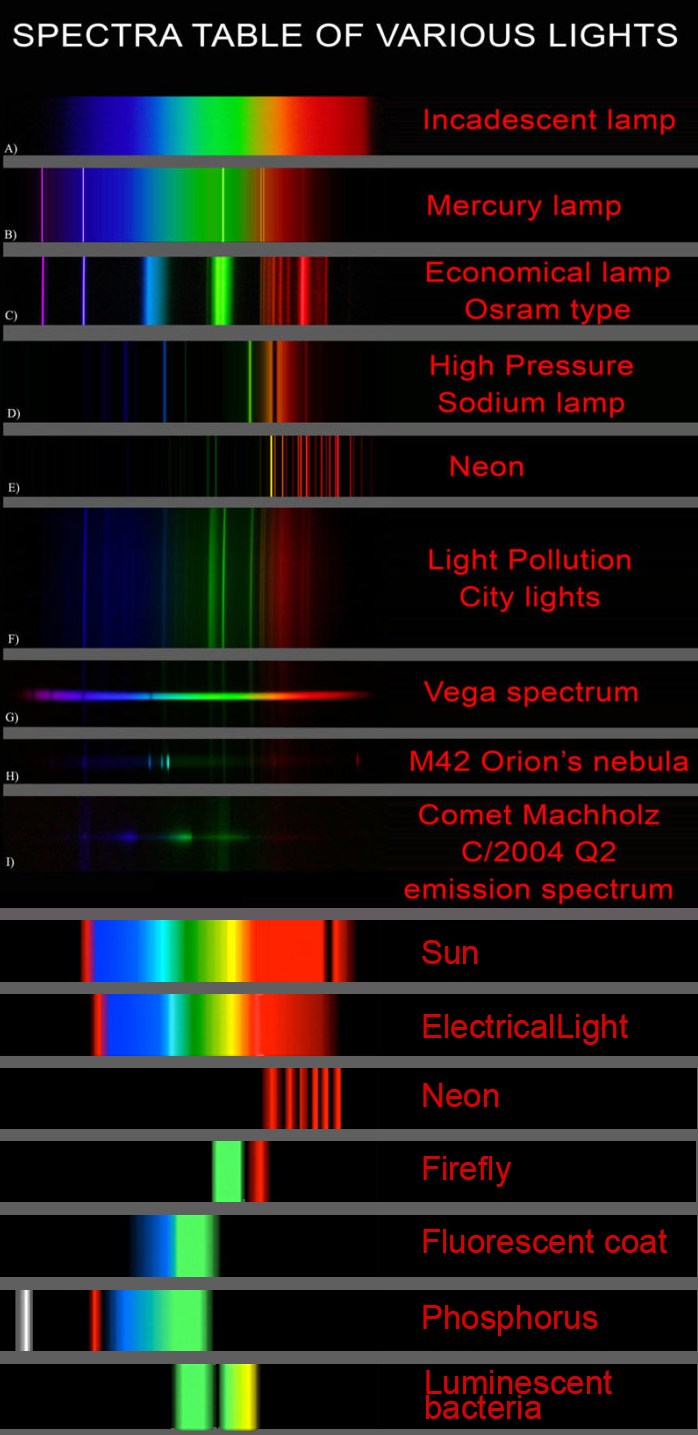







































{kind=link}
