



BREAKING NEWS
LATEST POSTS
-
Flex 1 Alpha – a pre-trained base 8 billion parameter rectified flow transformer
https://huggingface.co/ostris/Flex.1-alpha
Flex.1 started as the FLUX.1-schnell-training-adapter to make training LoRAs on FLUX.1-schnell possible.

-
Generative Detail Enhancement for Physically Based Materials
https://arxiv.org/html/2502.13994v1
https://arxiv.org/pdf/2502.13994
A tool for enhancing the detail of physically based materials using an off-the-shelf diffusion model and inverse rendering.

-
Camera Metadata Toolkit (camdkit) for Virtual Production
https://github.com/SMPTE/ris-osvp-metadata-camdkit
Today
camdkitsupports mapping (or importing, if you will) of metadata from five popular digital cinema cameras into a canonical form; it also supports a mapping of the metadata defined in the F4 protocol used by tracking system components from Mo-Sys.
-
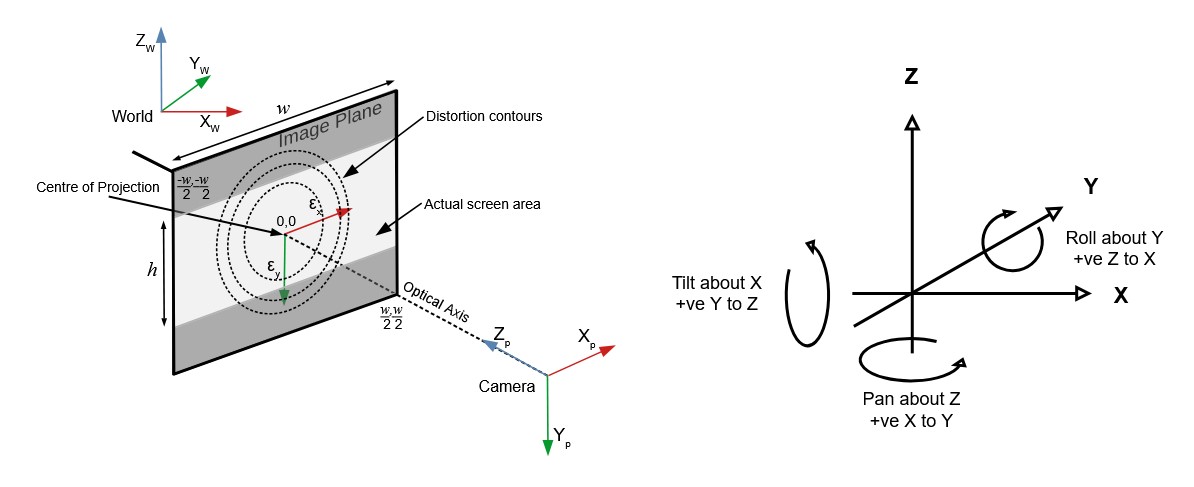
OpenTrackIO – free and open-source protocol designed to improve interoperability in Virtual Production
OpenTrackIO defines the schema of JSON samples that contain a wide range of metadata about the device, its transform(s), associated camera and lens. The full schema is given below and can be downloaded here.
-
Martin Gent – Comparing current video AI models
https://www.linkedin.com/posts/martingent_imagineapp-veo2-kling-activity-7298979787962806272-n0Sn
🔹 𝗩𝗲𝗼 2 – After the legendary prompt adherence of Veo 2 T2V, I have to say I2V is a little disappointing, especially when it comes to camera moves. You often get those Sora-like jump-cuts too which can be annoying.
🔹 𝗞𝗹𝗶𝗻𝗴 1.6 Pro – Still the one to beat for I2V, both for image quality and prompt adherence. It’s also a lot cheaper than Veo 2. Generations can be slow, but are usually worth the wait.
🔹 𝗥𝘂𝗻𝘄𝗮𝘆 Gen 3 – Useful for certain shots, but overdue an update. The worst performer here by some margin. Bring on Gen 4!
🔹 𝗟𝘂𝗺𝗮 Ray 2 – I love the energy and inventiveness Ray 2 brings, but those came with some image quality issues. I want to test more with this model though for sure.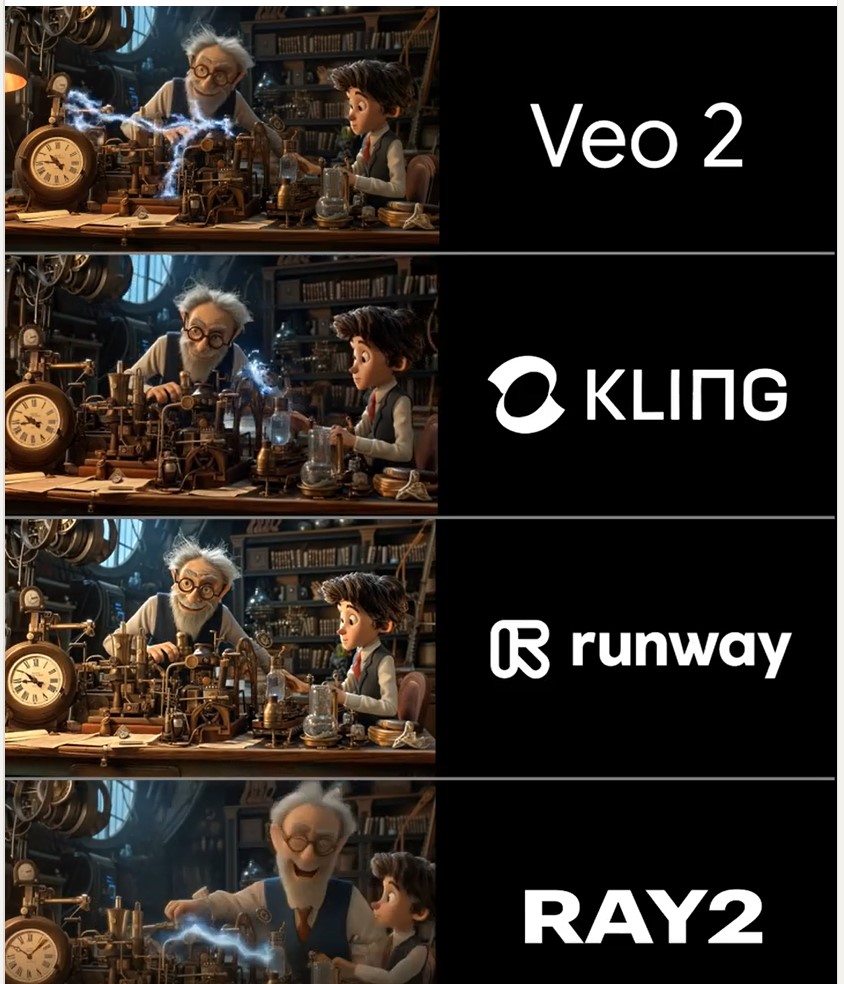
-
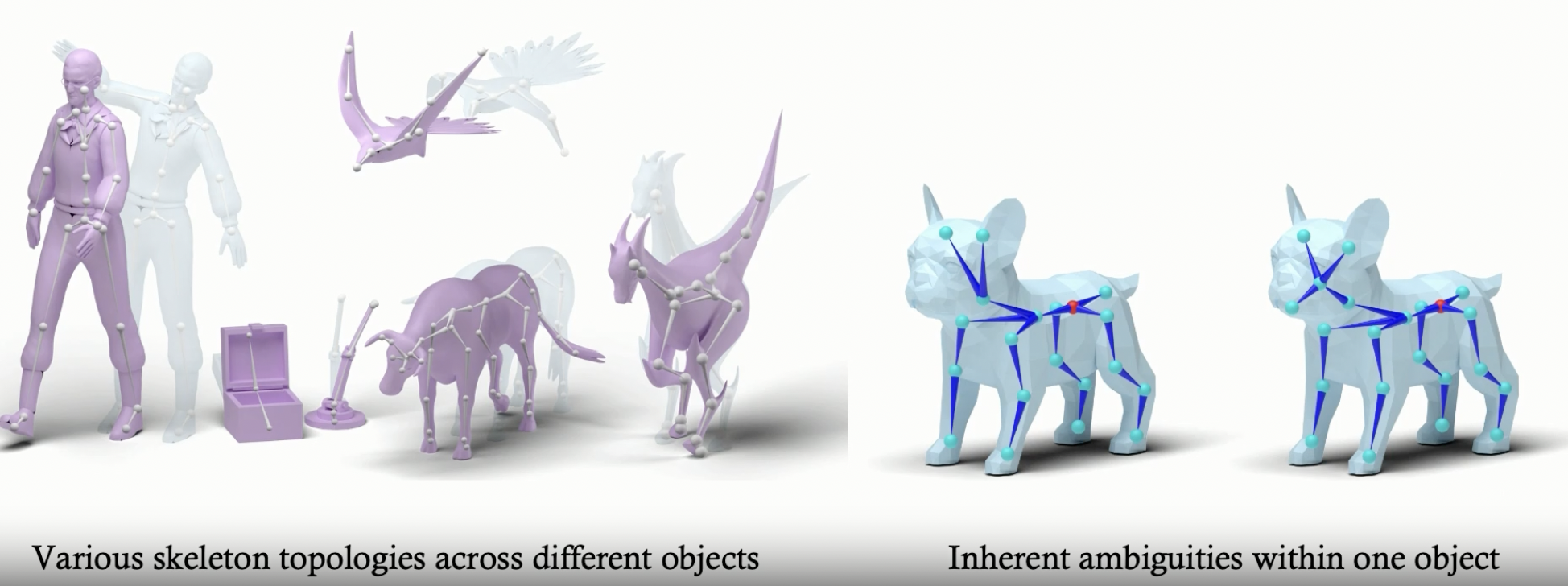
RigAnything – Template-Free Autoregressive Rigging for Diverse 3D Assets
https://www.liuisabella.com/RigAnything
RigAnything was developed through a collaboration between UC San Diego, Adobe Research, and Hillbot Inc. It addresses one of 3D animation’s most persistent challenges: automatic rigging.
- Template-Free Autoregressive Rigging. A transformer-based model that sequentially generates skeletons without predefined templates, enabling automatic rigging across diverse 3D assets through probabilistic joint prediction and skinning weight assignment.
- Support Arbitrary Input Pose. Generates high-quality skeletons for shapes in any pose through online joint pose augmentation during training, eliminating the common rest-pose requirement of existing methods and enabling broader real-world applications.
- Fast Rigging Speed. Achieves 20x faster performance than existing template-based methods, completing rigging in under 2 seconds per shape.
-
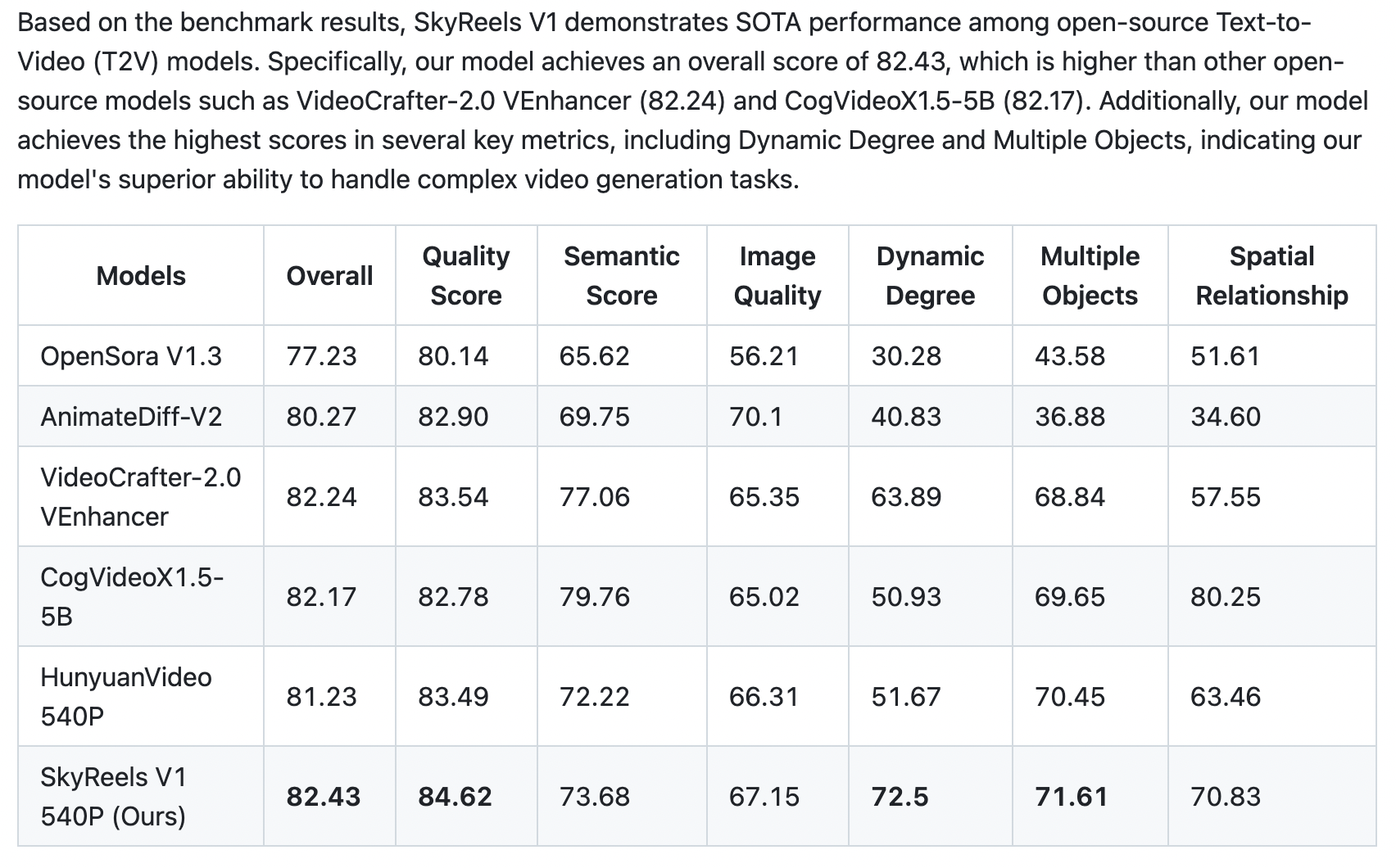
Skywork SkyReels – All-in-one open source AI video creation based on Hynyuan
https://github.com/SkyworkAI/SkyReels-V1
All-in-one AI platform for video creation, including voiceover, lipsync, SFX, and editing. One click turn text to video & image to video. Turns idea into stunning video in minutes. Check Pricing Details. Start For Free. All-In-One Platform.
SkyReels-V1 is purpose-built for AI short video production based on Hynyuan. It achieves cinematic-grade micro-expression performances with 33 nuanced facial expressions and 400+ natural body movements that can be freely combined. The model integrates film-quality lighting aesthetics, generating visually stunning compositions and textures through text-to-video or image-to-video conversion – outperforming all existing open-source models across key metrics.

-
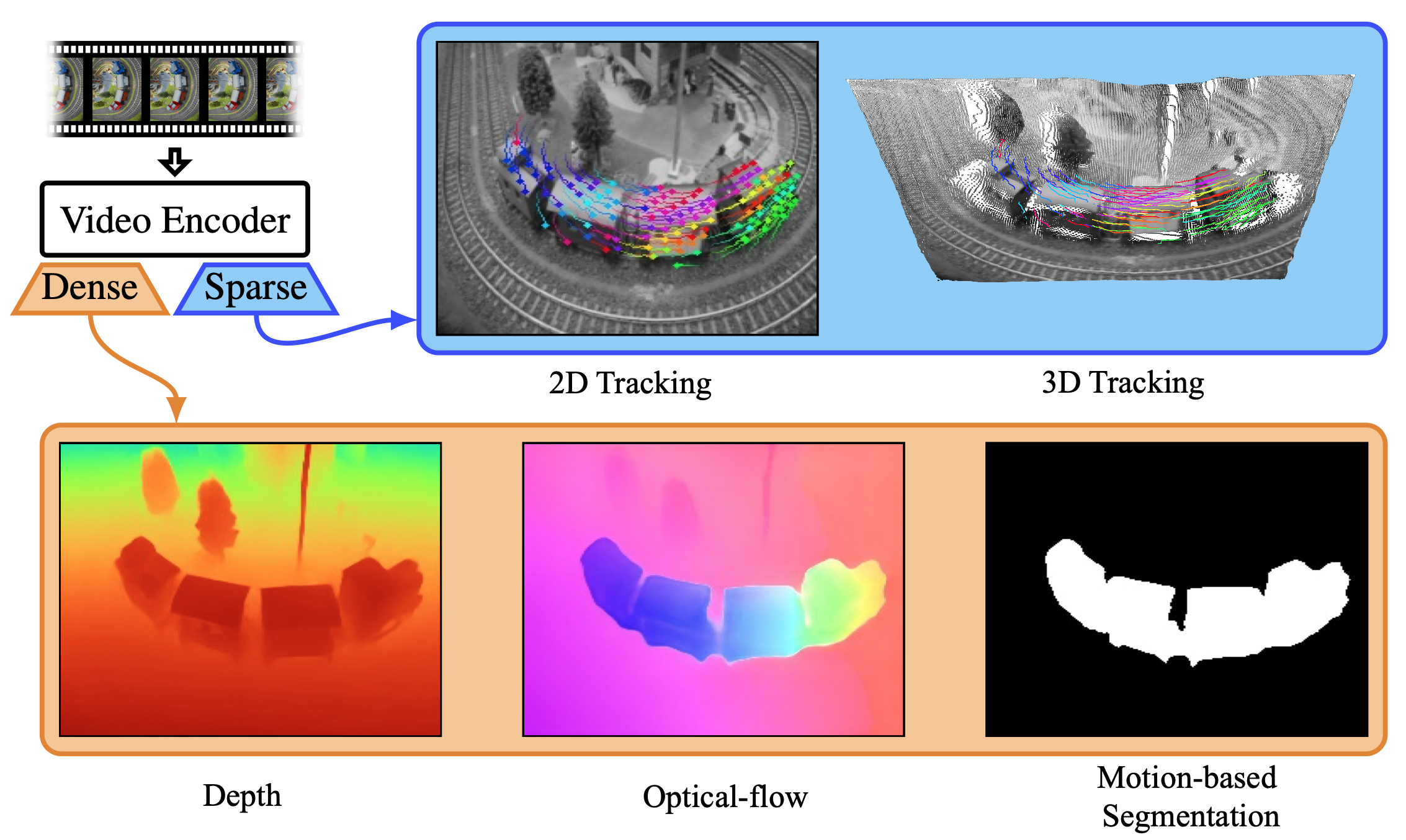
Shanhai based StepFun – Open source Step-Video-T2V
https://huggingface.co/stepfun-ai/stepvideo-t2v
The model generates videos up to 204 frames, using a high-compression Video-VAE (16×16 spatial, 8x temporal). It processes English and Chinese prompts via bilingual text encoders. A 3D full-attention DiT, trained with Flow Matching, denoises latent frames conditioned on text and timesteps. A video-based DPO further reduces artifacts, enhancing realism and smoothness.






FEATURED POSTS




-
HDRI Median Cut plugin
www.hdrlabs.com/picturenaut/plugins.html

Note. The Median Cut algorithm is typically used for color quantization, which involves reducing the number of colors in an image while preserving its visual quality. It doesn’t directly provide a way to identify the brightest areas in an image. However, if you’re interested in identifying the brightest areas, you might want to look into other methods like thresholding, histogram analysis, or edge detection, through openCV for example.
Here is an openCV example:
(more…)


