



BREAKING NEWS
LATEST POSTS
-
Starboard Urges Autodesk to Hold CEO Accountable After Probe
https://finance.yahoo.com/news/starboard-urges-autodesk-hold-ceo-154230189.html
Accounting problems at Autodesk first came to light in April, when the company delayed its annual financial disclosures and said it was opening a review of processes related to free cash flow and operating margins. In May, the company announced it was replacing Debbie Clifford as chief financial officer.
Bloomberg reported last week that documents showed the software company ignored internal warnings about the use of a controversial sales strategy that was central to the accounting probe’s findings.

-
David Heinemeier Hansson – Software development estimates have never worked and never will
https://world.hey.com/dhh/software-estimates-have-never-worked-and-never-will-a41a9c71
The fundamental problem is that as soon as a type of software development becomes so routine that it would be possible to estimate, it turns into a product or a service you can just buy rather than build.
-
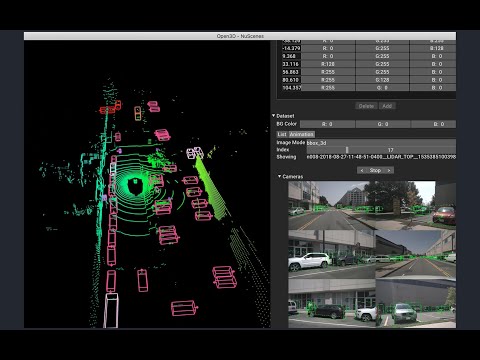
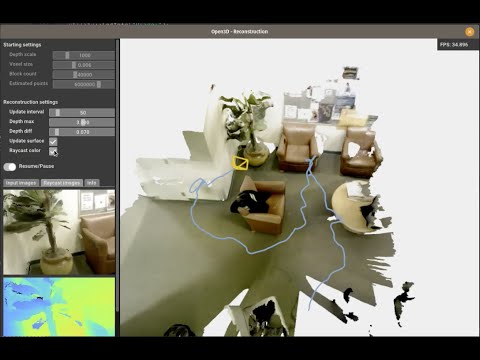
Open3d.org – An open source library that supports rapid development of software that deals with 3D data
Core features
- 3D data structures
- 3D data processing algorithms
- Scene reconstruction
- Surface alignment
- 3D visualization with Physically based rendering (PBR)
- 3D machine learning support with PyTorch and TensorFlow
- GPU acceleration for core 3D operations
- Available in C++ and Python with a 3D viewer app.











FEATURED POSTS




-
sRGB vs REC709 – An introduction and FFmpeg implementations
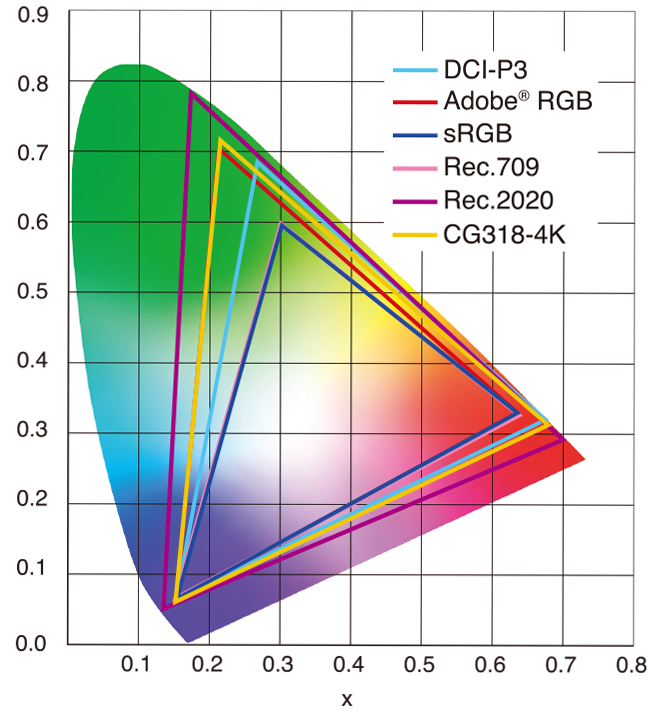
1. Basic Comparison
- What they are
- sRGB: A standard “web”/computer-display RGB color space defined by IEC 61966-2-1. It’s used for most monitors, cameras, printers, and the vast majority of images on the Internet.
- Rec. 709: An HD-video color space defined by ITU-R BT.709. It’s the go-to standard for HDTV broadcasts, Blu-ray discs, and professional video pipelines.
- Why they exist
- sRGB: Ensures consistent colors across different consumer devices (PCs, phones, webcams).
- Rec. 709: Ensures consistent colors across video production and playback chains (cameras → editing → broadcast → TV).
- What you’ll see
- On your desktop or phone, images tagged sRGB will look “right” without extra tweaking.
- On an HDTV or video-editing timeline, footage tagged Rec. 709 will display accurate contrast and hue on broadcast-grade monitors.
2. Digging Deeper
Feature sRGB Rec. 709 White point D65 (6504 K), same for both D65 (6504 K) Primaries (x,y) R: (0.640, 0.330) G: (0.300, 0.600) B: (0.150, 0.060) R: (0.640, 0.330) G: (0.300, 0.600) B: (0.150, 0.060) Gamut size Identical triangle on CIE 1931 chart Identical to sRGB Gamma / transfer Piecewise curve: approximate 2.2 with linear toe Pure power-law γ≈2.4 (often approximated as 2.2 in practice) Matrix coefficients N/A (pure RGB usage) Y = 0.2126 R + 0.7152 G + 0.0722 B (Rec. 709 matrix) Typical bit-depth 8-bit/channel (with 16-bit variants) 8-bit/channel (10-bit for professional video) Usage metadata Tagged as “sRGB” in image files (PNG, JPEG, etc.) Tagged as “bt709” in video containers (MP4, MOV) Color range Full-range RGB (0–255) Studio-range Y′CbCr (Y′ [16–235], Cb/Cr [16–240])
Why the Small Differences Matter
(more…) - What they are

