


COMPOSITION
-
Photography basics: Camera Aspect Ratio, Sensor Size and Depth of Field – resolutions
Read more: Photography basics: Camera Aspect Ratio, Sensor Size and Depth of Field – resolutionshttp://www.shutterangle.com/2012/cinematic-look-aspect-ratio-sensor-size-depth-of-field/
http://www.shutterangle.com/2012/film-video-aspect-ratio-artistic-choice/


-
Composition – These are the basic lighting techniques you need to know for photography and film
Read more: Composition – These are the basic lighting techniques you need to know for photography and film
http://www.diyphotography.net/basic-lighting-techniques-need-know-photography-film/
Amongst the basic techniques, there’s…
1- Side lighting – Literally how it sounds, lighting a subject from the side when they’re faced toward you
2- Rembrandt lighting – Here the light is at around 45 degrees over from the front of the subject, raised and pointing down at 45 degrees
3- Back lighting – Again, how it sounds, lighting a subject from behind. This can help to add drama with silouettes
4- Rim lighting – This produces a light glowing outline around your subject
5- Key light – The main light source, and it’s not necessarily always the brightest light source
6- Fill light – This is used to fill in the shadows and provide detail that would otherwise be blackness
7- Cross lighting – Using two lights placed opposite from each other to light two subjects





















DESIGN
















COLOR
-
Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental process
Read more: Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental processhttps://www.chrbutler.com/understanding-the-eye-mind-connection
The intricate relationship between the eyes and the brain, often termed the eye-mind connection, reveals that vision is predominantly a cognitive process. This understanding has profound implications for fields such as design, where capturing and maintaining attention is paramount. This essay delves into the nuances of visual perception, the brain’s role in interpreting visual data, and how this knowledge can be applied to effective design strategies.
This cognitive aspect of vision is evident in phenomena such as optical illusions, where the brain interprets visual information in a way that contradicts physical reality. These illusions underscore that what we “see” is not merely a direct recording of the external world but a constructed experience shaped by cognitive processes.
Understanding the cognitive nature of vision is crucial for effective design. Designers must consider how the brain processes visual information to create compelling and engaging visuals. This involves several key principles:
- Attention and Engagement
- Visual Hierarchy
- Cognitive Load Management
- Context and Meaning














LIGHTING
-
Photography basics: Solid Angle measures
Read more: Photography basics: Solid Angle measureshttp://www.calculator.org/property.aspx?name=solid+angle

A measure of how large the object appears to an observer looking from that point. Thus. A measure for objects in the sky. Useful to retuen the size of the sun and moon… and in perspective, how much of their contribution to lighting. Solid angle can be represented in ‘angular diameter’ as well.
http://en.wikipedia.org/wiki/Solid_angle
http://www.mathsisfun.com/geometry/steradian.html
A solid angle is expressed in a dimensionless unit called a steradian (symbol: sr). By default in terms of the total celestial sphere and before atmospheric’s scattering, the Sun and the Moon subtend fractional areas of 0.000546% (Sun) and 0.000531% (Moon).
http://en.wikipedia.org/wiki/Solid_angle#Sun_and_Moon
On earth the sun is likely closer to 0.00011 solid angle after athmospheric scattering. The sun as perceived from earth has a diameter of 0.53 degrees. This is about 0.000064 solid angle.
http://www.numericana.com/answer/angles.htm
The mean angular diameter of the full moon is 2q = 0.52° (it varies with time around that average, by about 0.009°). This translates into a solid angle of 0.0000647 sr, which means that the whole night sky covers a solid angle roughly one hundred thousand times greater than the full moon.
More info
http://lcogt.net/spacebook/using-angles-describe-positions-and-apparent-sizes-objects
http://amazing-space.stsci.edu/glossary/def.php.s=topic_astronomy
Angular Size
The apparent size of an object as seen by an observer; expressed in units of degrees (of arc), arc minutes, or arc seconds. The moon, as viewed from the Earth, has an angular diameter of one-half a degree.
The angle covered by the diameter of the full moon is about 31 arcmin or 1/2°, so astronomers would say the Moon’s angular diameter is 31 arcmin, or the Moon subtends an angle of 31 arcmin.

-
ICLight – Krea and ComfyUI light editing
Read more: ICLight – Krea and ComfyUI light editing
https://drive.google.com/drive/folders/16Aq1mqZKP-h8vApaN4FX5at3acidqPUv
https://github.com/lllyasviel/IC-Light
https://generativematte.blogspot.com/2025/03/comfyui-ic-light-relighting-exploration.html

Workflow Local copy

-
domeble – Hi-Resolution CGI Backplates and 360° HDRI
Read more: domeble – Hi-Resolution CGI Backplates and 360° HDRIWhen collecting hdri make sure the data supports basic metadata, such as:
- Iso
- Aperture
- Exposure time or shutter time
- Color temperature
- Color space Exposure value (what the sensor receives of the sun intensity in lux)
- 7+ brackets (with 5 or 6 being the perceived balanced exposure)
In image processing, computer graphics, and photography, high dynamic range imaging (HDRI or just HDR) is a set of techniques that allow a greater dynamic range of luminances (a Photometry measure of the luminous intensity per unit area of light travelling in a given direction. It describes the amount of light that passes through or is emitted from a particular area, and falls within a given solid angle) between the lightest and darkest areas of an image than standard digital imaging techniques or photographic methods. This wider dynamic range allows HDR images to represent more accurately the wide range of intensity levels found in real scenes ranging from direct sunlight to faint starlight and to the deepest shadows.
The two main sources of HDR imagery are computer renderings and merging of multiple photographs, which in turn are known as low dynamic range (LDR) or standard dynamic range (SDR) images. Tone Mapping (Look-up) techniques, which reduce overall contrast to facilitate display of HDR images on devices with lower dynamic range, can be applied to produce images with preserved or exaggerated local contrast for artistic effect. Photography
In photography, dynamic range is measured in Exposure Values (in photography, exposure value denotes all combinations of camera shutter speed and relative aperture that give the same exposure. The concept was developed in Germany in the 1950s) differences or stops, between the brightest and darkest parts of the image that show detail. An increase of one EV or one stop is a doubling of the amount of light.
The human response to brightness is well approximated by a Steven’s power law, which over a reasonable range is close to logarithmic, as described by the Weber�Fechner law, which is one reason that logarithmic measures of light intensity are often used as well.
HDR is short for High Dynamic Range. It’s a term used to describe an image which contains a greater exposure range than the “black” to “white” that 8 or 16-bit integer formats (JPEG, TIFF, PNG) can describe. Whereas these Low Dynamic Range images (LDR) can hold perhaps 8 to 10 f-stops of image information, HDR images can describe beyond 30 stops and stored in 32 bit images.













COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
4dv.ai – Remote Interactive 3D Holographic Presentation Technology and System running on the PlayCanvas engine
-
Photography basics: Color Temperature and White Balance
-
Gamma correction
-
Decart AI Mirage – The first ever World Transformation Model – turning any video, game, or camera feed into a new digital world, in real time
-
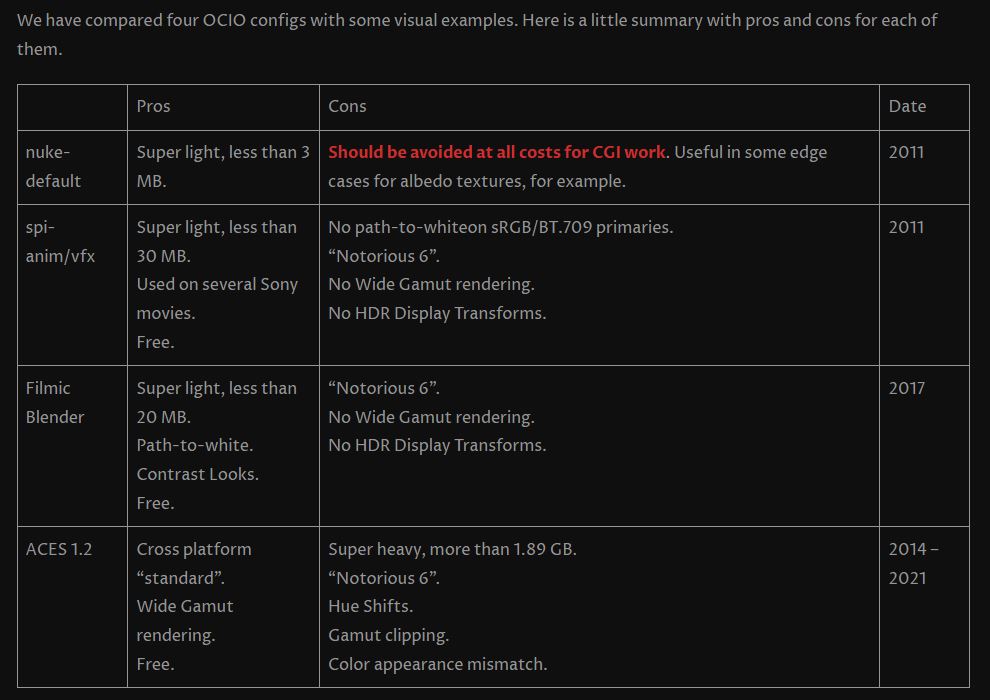
Scene Referred vs Display Referred color workflows
-
Eddie Yoon – There’s a big misconception about AI creative
-
GretagMacbeth Color Checker Numeric Values and Middle Gray
-
Photography basics: Lumens vs Candelas (candle) vs Lux vs FootCandle vs Watts vs Irradiance vs Illuminance
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
