


COMPOSITION
-
9 Best Hacks to Make a Cinematic Video with Any Camera
Read more: 9 Best Hacks to Make a Cinematic Video with Any Camerahttps://www.flexclip.com/learn/cinematic-video.html
- Frame Your Shots to Create Depth
- Create Shallow Depth of Field
- Avoid Shaky Footage and Use Flexible Camera Movements
- Properly Use Slow Motion
- Use Cinematic Lighting Techniques
- Apply Color Grading
- Use Cinematic Music and SFX
- Add Cinematic Fonts and Text Effects
- Create the Cinematic Bar at the Top and the Bottom

















DESIGN
-
Turn Yourself Into an Action Figure Using ChatGPT
Read more: Turn Yourself Into an Action Figure Using ChatGPT
ChatGPT Action Figure Prompts:
Create an action figure from the photo. It must be visualised in a realistic way. There should be accessories next to the figure like a UX designer have, Macbook Pro, a camera, drawing tablet, headset etc. Add a hole to the top of the box in the action figure. Also write the text “UX Mate” and below it “Keep Learning! Keep Designing
Use this image to create a picture of a action figure toy of a construction worker in a blister package from head to toe with accessories including a hammer, a staple gun and a ladder. The package should read “Kirk The Handy Man”
Create a realistic image of a toy action figure box. The box should be designed in a toy-equipment/action-figure style, with a cut-out window at the top like classic action figure packaging. The main color of the box and moleskine notebook should match the color of my jacket (referenced visually). Add colorful Mexican skull decorations across the box for a vibrant and artistic flair. Inside the box, include a “Your name” action figure, posed heroically. Next to the figure, arrange the following “equipment” in a stylized layout: • item 1 • item 2 … On the box, write: “Your name” (bold title font) Underneath: “Your role or anything else” The entire scene should look like a real product mockup, highly realistic, lit like a studio product photo. On the box, write: “Your name” (bold title font) Underneath: “Your role or description” The entire scene should look like a real product mockup, highly realistic, lit like a studio product photo. Prompt on Kling AI The figure steps out of its toy packaging and begins walking forward. As he continues to walk, the camera gradually zooms out in sync with his movement.
“Create image. Create a toy of the person in the photo. Let it be an action figure. Next to the figure, there should be the toy’s equipment, each in its individual blisters. 1) a book called “Tecnoforma”. 2) A 3-headed dog with a tag that says “Troika” and a bone at its feet with word “austerity” written on it. 3) a three-headed Hydra with with a tag called “Geringonça”. 4) a book titled “D. Sebastião”. Don’t repeat the equipment under any circumstance. The card holding the blister should be strong orange. Also, on top of the box, write ‘Pedro Passos Coelho’ and underneath it, ‘PSD action figure’. The figure and equipment must all be inside blisters. Visualize this in a realistic way.”


-
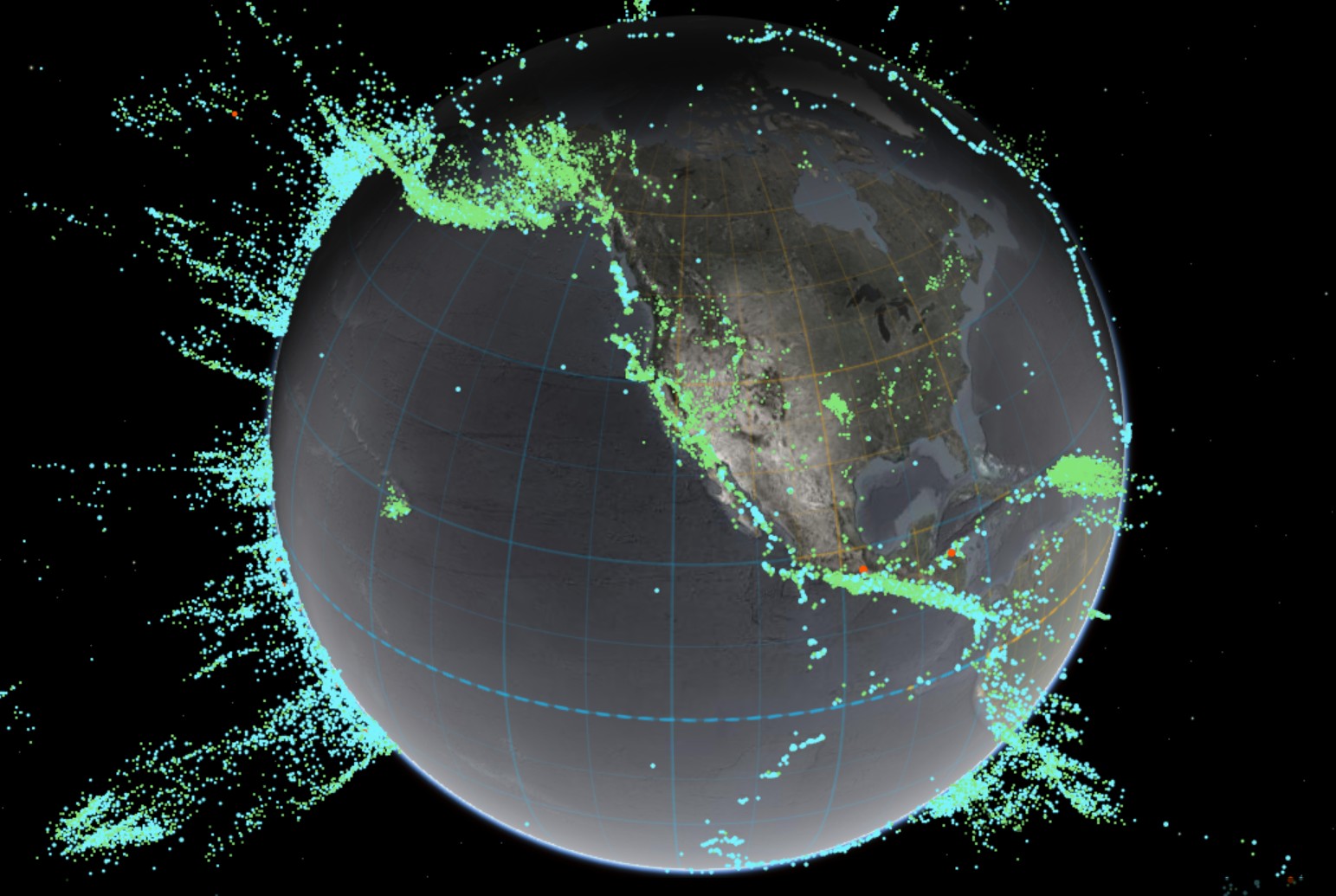
Interactive Maps of Earthquakes around the world
Read more: Interactive Maps of Earthquakes around the worldhttps://ralucanicola.github.io/JSAPI_demos/earthquakes
https://ralucanicola.github.io/JSAPI_demos/earthquakes-depth
https://ralucanicola.github.io/JSAPI_demos/ridgecrest-earthquake
https://ralucanicola.github.io/JSAPI_demos/last-earthquakes
-
Kristina Kashtanova – “This is how GPT-4 sees and hears itself”
Read more: Kristina Kashtanova – “This is how GPT-4 sees and hears itself”“I used GPT-4 to describe itself. Then I used its description to generate an image, a video based on this image and a soundtrack.
Tools I used: GPT-4, Midjourney, Kaiber AI, Mubert, RunwayML
This is the description I used that GPT-4 had of itself as a prompt to text-to-image, image-to-video, and text-to-music. I put the video and sound together in RunwayML.
GPT-4 described itself as: “Imagine a sleek, metallic sphere with a smooth surface, representing the vast knowledge contained within the model. The sphere emits a soft, pulsating glow that shifts between various colors, symbolizing the dynamic nature of the AI as it processes information and generates responses. The sphere appears to float in a digital environment, surrounded by streams of data and code, reflecting the complex algorithms and computing power behind the AI”










COLOR
-
The Forbidden colors – Red-Green & Blue-Yellow: The Stunning Colors You Can’t See
Read more: The Forbidden colors – Red-Green & Blue-Yellow: The Stunning Colors You Can’t Seewww.livescience.com/17948-red-green-blue-yellow-stunning-colors.html

While the human eye has red, green, and blue-sensing cones, those cones are cross-wired in the retina to produce a luminance channel plus a red-green and a blue-yellow channel, and it’s data in that color space (known technically as “LAB”) that goes to the brain. That’s why we can’t perceive a reddish-green or a yellowish-blue, whereas such colors can be represented in the RGB color space used by digital cameras.
https://en.rockcontent.com/blog/the-use-of-yellow-in-data-design
The back of the retina is covered in light-sensitive neurons known as cone cells and rod cells. There are three types of cone cells, each sensitive to different ranges of light. These ranges overlap, but for convenience the cones are referred to as blue (short-wavelength), green (medium-wavelength), and red (long-wavelength). The rod cells are primarily used in low-light situations, so we’ll ignore those for now.
When light enters the eye and hits the cone cells, the cones get excited and send signals to the brain through the visual cortex. Different wavelengths of light excite different combinations of cones to varying levels, which generates our perception of color. You can see that the red cones are most sensitive to light, and the blue cones are least sensitive. The sensitivity of green and red cones overlaps for most of the visible spectrum.

Here’s how your brain takes the signals of light intensity from the cones and turns it into color information. To see red or green, your brain finds the difference between the levels of excitement in your red and green cones. This is the red-green channel.
To get “brightness,” your brain combines the excitement of your red and green cones. This creates the luminance, or black-white, channel. To see yellow or blue, your brain then finds the difference between this luminance signal and the excitement of your blue cones. This is the yellow-blue channel.
From the calculations made in the brain along those three channels, we get four basic colors: blue, green, yellow, and red. Seeing blue is what you experience when low-wavelength light excites the blue cones more than the green and red.
Seeing green happens when light excites the green cones more than the red cones. Seeing red happens when only the red cones are excited by high-wavelength light.
Here’s where it gets interesting. Seeing yellow is what happens when BOTH the green AND red cones are highly excited near their peak sensitivity. This is the biggest collective excitement that your cones ever have, aside from seeing pure white.
Notice that yellow occurs at peak intensity in the graph to the right. Further, the lens and cornea of the eye happen to block shorter wavelengths, reducing sensitivity to blue and violet light.
-
What is a Gamut or Color Space and why do I need to know about CIE
Read more: What is a Gamut or Color Space and why do I need to know about CIE

http://www.xdcam-user.com/2014/05/what-is-a-gamut-or-color-space-and-why-do-i-need-to-know-about-it/
In video terms gamut is normally related to as the full range of colours and brightness that can be either captured or displayed.
(more…) -
Gamma correction
Read more: Gamma correction

http://www.normankoren.com/makingfineprints1A.html#Gammabox
https://en.wikipedia.org/wiki/Gamma_correction
http://www.photoscientia.co.uk/Gamma.htm
https://www.w3.org/Graphics/Color/sRGB.html
http://www.eizoglobal.com/library/basics/lcd_display_gamma/index.html
https://forum.reallusion.com/PrintTopic308094.aspx
Basically, gamma is the relationship between the brightness of a pixel as it appears on the screen, and the numerical value of that pixel. Generally Gamma is just about defining relationships.
Three main types:
– Image Gamma encoded in images
– Display Gammas encoded in hardware and/or viewing time
– System or Viewing Gamma which is the net effect of all gammas when you look back at a final image. In theory this should flatten back to 1.0 gamma.
(more…) -
Björn Ottosson – How software gets color wrong
Read more: Björn Ottosson – How software gets color wronghttps://bottosson.github.io/posts/colorwrong/
Most software around us today are decent at accurately displaying colors. Processing of colors is another story unfortunately, and is often done badly.
To understand what the problem is, let’s start with an example of three ways of blending green and magenta:
- Perceptual blend – A smooth transition using a model designed to mimic human perception of color. The blending is done so that the perceived brightness and color varies smoothly and evenly.
- Linear blend – A model for blending color based on how light behaves physically. This type of blending can occur in many ways naturally, for example when colors are blended together by focus blur in a camera or when viewing a pattern of two colors at a distance.
- sRGB blend – This is how colors would normally be blended in computer software, using sRGB to represent the colors.

Let’s look at some more examples of blending of colors, to see how these problems surface more practically. The examples use strong colors since then the differences are more pronounced. This is using the same three ways of blending colors as the first example.

Instead of making it as easy as possible to work with color, most software make it unnecessarily hard, by doing image processing with representations not designed for it. Approximating the physical behavior of light with linear RGB models is one easy thing to do, but more work is needed to create image representations tailored for image processing and human perception.
Also see:
-
Scientists claim to have discovered ‘new colour’ no one has seen before: Olo
Read more: Scientists claim to have discovered ‘new colour’ no one has seen before: Olohttps://www.bbc.com/news/articles/clyq0n3em41o
By stimulating specific cells in the retina, the participants claim to have witnessed a blue-green colour that scientists have called “olo”, but some experts have said the existence of a new colour is “open to argument”.
The findings, published in the journal Science Advances on Friday, have been described by the study’s co-author, Prof Ren Ng from the University of California, as “remarkable”.

(A) System inputs. (i) Retina map of 103 cone cells preclassified by spectral type (7). (ii) Target visual percept (here, a video of a child, see movie S1 at 1:04). (iii) Infrared cellular-scale imaging of the retina with 60-frames-per-second rolling shutter. Fixational eye movement is visible over the three frames shown.
(B) System outputs. (iv) Real-time per-cone target activation levels to reproduce the target percept, computed by: extracting eye motion from the input video relative to the retina map; identifying the spectral type of every cone in the field of view; computing the per-cone activation the target percept would have produced. (v) Intensities of visible-wavelength 488-nm laser microdoses at each cone required to achieve its target activation level.
(C) Infrared imaging and visible-wavelength stimulation are physically accomplished in a raster scan across the retinal region using AOSLO. By modulating the visible-wavelength beam’s intensity, the laser microdoses shown in (v) are delivered. Drawing adapted with permission [Harmening and Sincich (54)].
(D) Examples of target percepts with corresponding cone activations and laser microdoses, ranging from colored squares to complex imagery. Teal-striped regions represent the color “olo” of stimulating only M cones.










LIGHTING
-
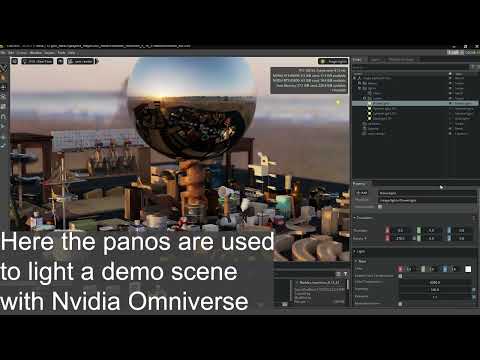
NVidia DiffusionRenderer – Neural Inverse and Forward Rendering with Video Diffusion Models. How NVIDIA reimagined relighting
Read more: NVidia DiffusionRenderer – Neural Inverse and Forward Rendering with Video Diffusion Models. How NVIDIA reimagined relightinghttps://www.fxguide.com/quicktakes/diffusing-reality-how-nvidia-reimagined-relighting/
https://research.nvidia.com/labs/toronto-ai/DiffusionRenderer/


-
Outpost VFX lighting tips
Read more: Outpost VFX lighting tipswww.outpost-vfx.com/en/news/18-pro-tips-and-tricks-for-lighting
Get as much information regarding your plate lighting as possible
- Always use a reference
- Replicate what is happening in real life
- Invest into a solid HDRI
- Start Simple
- Observe real world lighting, photography and cinematography
- Don’t neglect the theory
- Learn the difference between realism and photo-realism.
- Keep your scenes organised

-
Romain Chauliac – LightIt a lighting script for Maya and Arnold
Read more: Romain Chauliac – LightIt a lighting script for Maya and ArnoldLightIt is a script for Maya and Arnold that will help you and improve your lighting workflow.
Thanks to preset studio lighting components (lights, backdrop…), high quality studio scenes and HDRI library manager.
https://www.artstation.com/artwork/393emJ












COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Tencent Hunyuan3D 2.1 goes Open Source and adds MV (Multi-view) and MV Mini
-
3D Gaussian Splatting step by step beginner course
-
Photography basics: Color Temperature and White Balance
-
Photography basics: Production Rendering Resolution Charts
-
Gamma correction
-
Zibra.AI – Real-Time Volumetric Effects in Virtual Production. Now free for Indies!
-
Eddie Yoon – There’s a big misconception about AI creative
-
AI Search – Find The Best AI Tools & Apps
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
