The intricate relationship between the eyes and the brain, often termed the eye-mind connection, reveals that vision is predominantly a cognitive process. This understanding has profound implications for fields such as design, where capturing and maintaining attention is paramount. This essay delves into the nuances of visual perception, the brain’s role in interpreting visual data, and how this knowledge can be applied to effective design strategies.
This cognitive aspect of vision is evident in phenomena such as optical illusions, where the brain interprets visual information in a way that contradicts physical reality. These illusions underscore that what we “see” is not merely a direct recording of the external world but a constructed experience shaped by cognitive processes.
Understanding the cognitive nature of vision is crucial for effective design. Designers must consider how the brain processes visual information to create compelling and engaging visuals. This involves several key principles:
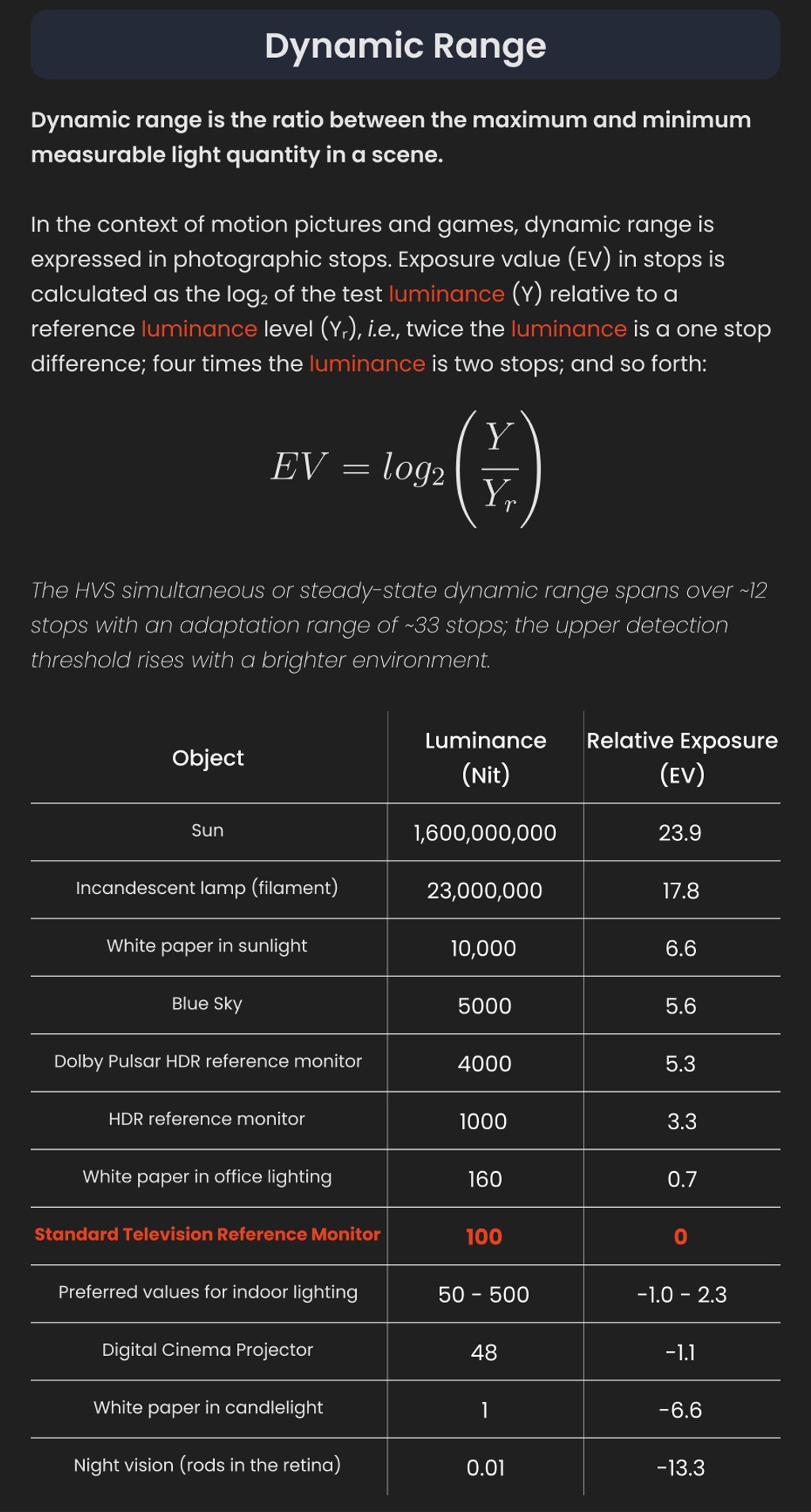
To measure the contrast ratio you will need a light meter. The process starts with you measuring the main source of light, or the key light.
Get a reading from the brightest area on the face of your subject. Then, measure the area lit by the secondary light, or fill light. To make sense of what you have just measured you have to understand that the information you have just gathered is in F-stops, a measure of light. With each additional F-stop, for example going one stop from f/1.4 to f/2.0, you create a doubling of light. The reverse is also true; moving one stop from f/8.0 to f/5.6 results in a halving of the light.
Disco Diffusion (DD) is a Google Colab Notebook which leverages an AI Image generating technique called CLIP-Guided Diffusion to allow you to create compelling and beautiful images from just text inputs. Created by Somnai, augmented by Gandamu, and building on the work of RiversHaveWings, nshepperd, and many others.
The Manuka rendering architecture has been designed in the spirit of the classic reyes rendering architecture. In its core, reyes is based on stochastic rasterisation of micropolygons, facilitating depth of field, motion blur, high geometric complexity,and programmable shading.
This is commonly achieved with Monte Carlo path tracing, using a paradigm often called shade-on-hit, in which the renderer alternates tracing rays with running shaders on the various ray hits. The shaders take the role of generating the inputs of the local material structure which is then used bypath sampling logic to evaluate contributions and to inform what further rays to cast through the scene.
Over the years, however, the expectations have risen substantially when it comes to image quality. Computing pictures which are indistinguishable from real footage requires accurate simulation of light transport, which is most often performed using some variant of Monte Carlo path tracing. Unfortunately this paradigm requires random memory accesses to the whole scene and does not lend itself well to a rasterisation approach at all.
Manuka is both a uni-directional and bidirectional path tracer and encompasses multiple importance sampling (MIS). Interestingly, and importantly for production character skin work, it is the first major production renderer to incorporate spectral MIS in the form of a new ‘Hero Spectral Sampling’ technique, which was recently published at Eurographics Symposium on Rendering 2014.
Manuka propose a shade-before-hit paradigm in-stead and minimise I/O strain (and some memory costs) on the system, leveraging locality of reference by running pattern generation shaders before we execute light transport simulation by path sampling, “compressing” any bvh structure as needed, and as such also limiting duplication of source data.
The difference with reyes is that instead of baking colors into the geometry like in Reyes, manuka bakes surface closures. This means that light transport is still calculated with path tracing, but all texture lookups etc. are done up-front and baked into the geometry.
The main drawback with this method is that geometry has to be tessellated to its highest, stable topology before shading can be evaluated properly. As such, the high cost to first pixel. Even a basic 4 vertices square becomes a much more complex model with this approach.
Manuka use the RenderMan Shading Language (rsl) for programmable shading [Pixar Animation Studios 2015], but we do not invoke rsl shaders when intersecting a ray with a surface (often called shade-on-hit). Instead, we pre-tessellate and pre-shade all the input geometry in the front end of the renderer.
This way, we can efficiently order shading computations to sup-port near-optimal texture locality, vectorisation, and parallelism. This system avoids repeated evaluation of shaders at the same surface point, and presents a minimal amount of memory to be accessed during light transport time. An added benefit is that the acceleration structure for ray tracing (abounding volume hierarchy, bvh) is built once on the final tessellated geometry, which allows us to ray trace more efficiently than multi-level bvhs and avoids costly caching of on-demand tessellated micropolygons and the associated scheduling issues.
For the shading reasons above, in terms of AOVs, the studio approach is to succeed at combining complex shading with ray paths in the render rather than pass a multi-pass render to compositing.
For the Spectral Rendering component. The light transport stage is fully spectral, using a continuously sampled wavelength which is traced with each path and used to apply the spectral camera sensitivity of the sensor. This allows for faithfully support any degree of observer metamerism as the camera footage they are intended to match as well as complex materials which require wavelength dependent phenomena such as diffraction, dispersion, interference, iridescence, or chromatic extinction and Rayleigh scattering in participating media.
As opposed to the original reyes paper, we use bilinear interpolation of these bsdf inputs later when evaluating bsdfs per pathv ertex during light transport4. This improves temporal stability of geometry which moves very slowly with respect to the pixel raster
In terms of the pipeline, everything rendered at Weta was already completely interwoven with their deep data pipeline. Manuka very much was written with deep data in mind. Here, Manuka not so much extends the deep capabilities, rather it fully matches the already extremely complex and powerful setup Weta Digital already enjoy with RenderMan. For example, an ape in a scene can be selected, its ID is available and a NUKE artist can then paint in 3D say a hand and part of the way up the neutral posed ape.
We called our system Manuka, as a respectful nod to reyes: we had heard a story froma former ILM employee about how reyes got its name from how fond the early Pixar people were of their lunches at Point Reyes, and decided to name our system after our surrounding natural environment, too. Manuka is a kind of tea tree very common in New Zealand which has very many very small leaves, in analogy to micropolygons ina tree structure for ray tracing. It also happens to be the case that Weta Digital’s main site is on Manuka Street.
The goals of lighting in 3D computer graphics are more or less the same as those of real world lighting.
Lighting serves a basic function of bringing out, or pushing back the shapes of objects visible from the camera’s view.
It gives a two-dimensional image on the monitor an illusion of the third dimension-depth.
But it does not just stop there. It gives an image its personality, its character. A scene lit in different ways can give a feeling of happiness, of sorrow, of fear etc., and it can do so in dramatic or subtle ways. Along with personality and character, lighting fills a scene with emotion that is directly transmitted to the viewer.
Trying to simulate a real environment in an artificial one can be a daunting task. But even if you make your 3D rendering look absolutely photo-realistic, it doesn’t guarantee that the image carries enough emotion to elicit a “wow” from the people viewing it.
Making 3D renderings photo-realistic can be hard. Putting deep emotions in them can be even harder. However, if you plan out your lighting strategy for the mood and emotion that you want your rendering to express, you make the process easier for yourself.
Each light source can be broken down in to 4 distinct components and analyzed accordingly.
· Intensity
· Direction
· Color
· Size
The overall thrust of this writing is to produce photo-realistic images by applying good lighting techniques.
Björn Ottosson proposed OKlch in 2020 to create a color space that can closely mimic how color is perceived by the human eye, predicting perceived lightness, chroma, and hue.
The OK in OKLCH stands for Optimal Color.
L: Lightness (the perceived brightness of the color)
C: Chroma (the intensity or saturation of the color)
H: Hue (the actual color, such as red, blue, green, etc.)
By stimulating specific cells in the retina, the participants claim to have witnessed a blue-green colour that scientists have called “olo”, but some experts have said the existence of a new colour is “open to argument”.
The findings, published in the journal Science Advances on Friday, have been described by the study’s co-author, Prof Ren Ng from the University of California, as “remarkable”.
(A) System inputs. (i) Retina map of 103 cone cells preclassified by spectral type (7). (ii) Target visual percept (here, a video of a child, see movie S1 at 1:04). (iii) Infrared cellular-scale imaging of the retina with 60-frames-per-second rolling shutter. Fixational eye movement is visible over the three frames shown.
(B) System outputs. (iv) Real-time per-cone target activation levels to reproduce the target percept, computed by: extracting eye motion from the input video relative to the retina map; identifying the spectral type of every cone in the field of view; computing the per-cone activation the target percept would have produced. (v) Intensities of visible-wavelength 488-nm laser microdoses at each cone required to achieve its target activation level.
(C) Infrared imaging and visible-wavelength stimulation are physically accomplished in a raster scan across the retinal region using AOSLO. By modulating the visible-wavelength beam’s intensity, the laser microdoses shown in (v) are delivered. Drawing adapted with permission [Harmening and Sincich (54)].
(D) Examples of target percepts with corresponding cone activations and laser microdoses, ranging from colored squares to complex imagery. Teal-striped regions represent the color “olo” of stimulating only M cones.
Chroma Key Green, the color of green screens is also known as Chroma Green and is valued at approximately 354C in the Pantone color matching system (PMS).
Chroma Green can be broken down in many different ways. Here is green screen green as other values useful for both physical and digital production:
Green Screen as RGB Color Value: 0, 177, 64
Green Screen as CMYK Color Value: 81, 0, 92, 0
Green Screen as Hex Color Value: #00b140
Green Screen as Websafe Color Value: #009933
Chroma Key Green is reasonably close to an 18% gray reflectance.
Illuminate your green screen with an uniform source with less than 2/3 EV variation.
The level of brightness at any given f-stop should be equivalent to a 90% white card under the same lighting.
The power output of a light source is measured using the unit of watts W. This is a direct measure to calculate how much power the light is going to drain from your socket and it is not relatable to the light brightness itself.
The amount of energy emitted from it per second. That energy comes out in a form of photons which we can crudely represent with rays of light coming out of the source. The higher the power the more rays emitted from the source in a unit of time.
Not all energy emitted is visible to the human eye, so we often rely on photometric measurements, which takes in account the sensitivity of human eye to different wavelenghts
A measure of how large the object appears to an observer looking from that point. Thus. A measure for objects in the sky. Useful to retuen the size of the sun and moon… and in perspective, how much of their contribution to lighting. Solid angle can be represented in ‘angular diameter’ as well.
A solid angle is expressed in a dimensionless unit called a steradian (symbol: sr). By default in terms of the total celestial sphere and before atmospheric’s scattering, the Sun and the Moon subtend fractional areas of 0.000546% (Sun) and 0.000531% (Moon).
On earth the sun is likely closer to 0.00011 solid angle after athmospheric scattering. The sun as perceived from earth has a diameter of 0.53 degrees. This is about 0.000064 solid angle.
The mean angular diameter of the full moon is 2q = 0.52° (it varies with time around that average, by about 0.009°). This translates into a solid angle of 0.0000647 sr, which means that the whole night sky covers a solid angle roughly one hundred thousand times greater than the full moon.
The apparent size of an object as seen by an observer; expressed in units of degrees (of arc), arc minutes, or arc seconds. The moon, as viewed from the Earth, has an angular diameter of one-half a degree.
The angle covered by the diameter of the full moon is about 31 arcmin or 1/2°, so astronomers would say the Moon’s angular diameter is 31 arcmin, or the Moon subtends an angle of 31 arcmin.
Basically, gamma is the relationship between the brightness of a pixel as it appears on the screen, and the numerical value of that pixel. Generally Gamma is just about defining relationships.
Three main types: – Image Gamma encoded in images – Display Gammas encoded in hardware and/or viewing time – System or Viewing Gamma which is the net effect of all gammas when you look back at a final image. In theory this should flatten back to 1.0 gamma.
A light wave that is vibrating in more than one plane is referred to as unpolarized light. …
Polarized light waves are light waves in which the vibrations occur in a single plane. The process of transforming unpolarized light into polarized light is known as polarization.
The most common use of polarized technology is to reduce lighting complexity on the subject. Details such as glare and hard edges are not removed, but greatly reduced.
5.10 of this tool includes excellent tools to clean up cr2 and cr3 used on set to support HDRI processing.
Converting raw to AcesCG 32 bit tiffs with metadata.
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.

















































































![[gamma correction test]](http://www.madore.org/~david/misc/color/gammatest.png "sRGB gamma correction test")