Search Results for: free


DreamWorks Animation to Release MoonRay as Open Source

https://www.awn.com/news/dreamworks-animation-release-moonray-open-source
MoonRay is DreamWorks’ open-source, award-winning, state-of-the-art production MCRT renderer, which has been used on feature films such as How to Train Your Dragon: The Hidden World, Trolls World Tour, The Bad Guys, the upcoming Puss In Boots: The Last Wish, as well as future titles. MoonRay was developed at DreamWorks and is in continuous active development and includes an extensive library of production-tested, physically based materials, a USD Hydra render delegate, multi-machine and cloud rendering via the Arras distributed computation framework.

Note: it does not support osl and usd handling is limited. Cycles may still be a fair alternative.
EDIT
MoonRay review: DreamWorks Animations’ superb rendering software is free for all
A high-performance Monte Carlo ray tracer that’s capable of both DreamWorks’ trademark stylised look and photorealism.
It has all the required features for that setup, including Arbitrary Output Variables (AOVs), which allow data from a shader or renderer to be output during rendering to aid compositing. Additionally, Deep Output and Cryptomatte are supported.
With support for OptiX 7.6 and GPU render denoising with Open Image Denoise 2, MoonRay is able to deliver particularly impressive results, especially when working interactively.
MoonRay has moved to a hybrid CPU and GPU rendering mode for its default state. It’s called XPU, and in many ways combines the best of both types of rendering workflow.
VFX Reference Platform 2023 is probably the biggest addition because it enables the use of MoonRay directly in Nuke 15.
MoonRay has already achieved great success with an array of feature films. Now the renderer is open source, the CG world can expect to see a whole new swathe of MoonRay-powered animations.
For
- Features for VFX workflows
- Open source
- XPU rendering
Against
- Designed for big studios
- Steep learning curve
TLDR Newsletter – Keep up with tech in 5 minutes
Get the free daily email with summaries of the most interesting stories in startups, tech, and programming!

Generative AI Glossary
https://education.civitai.com/generative-ai-glossary/
| Term | Tags | Description |
|---|---|---|
| .ckpt | Model | “Checkpoint”, a file format created by PyTorch Lightning, a PyTorch research framework. It contains a PyTorch Lightning machine learning model used (by Stable Diffusion) to generate images. |
| .pt | Software | A machine learning model file created using PyTorch, containing algorithms used to automatically perform a task. |
| .Safetensors | Model | A file format for Checkpoint models, less susceptible to embedded malicious code. See “Pickle” |
| ADetailer | Software, Extension | A popular Automatic1111 Extension, mostly used to enhance fine face and eye detail, but can be used to re-draw hands and full characters. |
| AGI | Concept | Artificial General Intelligence (AGI), the point at which AI matches or exceeds the intelligence of humans. |
| Algorithm | Concept, Software | A series of instructions that allow a computer to learn and analyze data, learning from it, and use that learning to interpret and accomplish future tasks on its own. |
| AnimateDiff | Software, Extension | Technique which involves injecting motion into txt2img (or img2img) generations. https://animatediff.github.io/ |
| API | Software | Application Programmer Interface – a set of functions and tools which allow interaction with, or between, pieces of software. |
| Auto-GPT | Software, LLM | |
| Automatic1111 | Developer, SD User Interface | Creator of the popular Automatic1111 WebUI graphical user interface for SD. |
| Bard | Software, LLM | Google’s Chatbot, based on their LaMDA model. |
| Batch | A subset of the training data used in one iteration of model training. In inference, a group of images. | |
| Bias | Concept, LLM | In Large Language Models, errors resulting from training data; stereotypes, attributing certain characteristics to races or groups of people, etc. Bias can cause models to generate offensive and harmful content. |
| Bing | Software, LLM | Microsoft’s ChatGTP powered Chatbot. |
| CFG | Setting | Classifier Free Guidance, sometimes “Guidance Scale”. Controls how closely the image generation process follows the text prompt. |
| Checkpoint | Model | The product of training on millions of captioned images scraped from multiple sources on the Web. This file drives Stable Diffusion’s txt2img, img2img, txt2video |
| Civitai (Civitai.com) | Community Resource | Popular hosting site for all types of Generative AI resources. |
| Civitai Generator | Software, Tool | Free Stable Diffusion Image Generation Interface, available on Civitai.com. |
| Civitai Trainer | Software, Tool | LoRA Training interface, available on Civitai.com, for SDXL and 1.5 based LoRA. |
| CLIP | Software | An open source model created by OpenAI. Trained on millions of images and captions, it determines how well a particular caption describes an image. |
| Cmdr2 | Developer, SD User Interface | Creator of the popular EasyDiffusion, simple one-click install graphical user interface for SD. |
| CodeFormer | Face/Image Restoration, Model | A facial image restoration model, for fixing blurry, grainy, or disfigured faces. |
| Colab | Tool | Colaboratory, a product from Google Research, allowing execution of Python code through the browser. Particularly geared towards machine learning applications. https://colab.research.google.com/ |
| ComfyUI | SD User Interface, Software | A popular powerful modular UI for Stable Diffusion with a “workflow” type workspace. Somewhat more complex than Auto1111 WebUI https://github.com/comfyanonymous/ComfyUI |
| CompVis | Organization | Computer Vision & Learning research group at Ludwig Maximilian University of Munich. They host Stable Diffusion models on Hugging Face. |
| Conda | Application, Software | An open source package manager for many programming languages, including Python. |
| ControlNet | UI Extension | An Extension to Auto1111 WebUI allowing images to be manipulated in a number of ways. https://github.com/Mikubill/sd-webui-controlnet |
| Convergence | Concept | The point in image generation where the image no longer changes as the steps increase. |
| CUDA | Hardware, Software | Compute Unified Device Architecture, Nvdia’s parallel processing architecture. |
| DALL-E / DALL-E 2 | Organization | Deep learning image models created by OpenAI, available as a commercial image generation service. |
| Danbooru | Community Resource | English-based image board website specializing in erotic manga fan art, NSFW. |
| Danbooru Tag | Community Resource | System of keywords applied to Danbooru images describing the content within. When using Checkpoint models trained on Danbooru images, keywords can be referenced in Prompts. |
| DDIM (Sampler) | Sampler | Denoising Diffusion Implicit Models. See Samplers. |
| Deep Learning | Concept | A type of Machine Learning, where neural networks attempt to mimic the behavior of the human brain to perform tasks. |
| Deforum | UI Extension, Community Resource | A community of AI image synthesis developers, enthusiasts, and artists, producing Generative AI tools. Most commonly known for a Stable Diffusion WebUI video extension of the same name. |
| Denoising/Diffusion | Concept | The process by which random noise (see Seed) is iteratively reduced into the final image. |
| depth2img | Concept | Infers the depth of an input image (using an existing model), and then generates new images using both the text and depth information. |
| Diffusion Model (DM) | Model | A generative model, used to generate data similar to the data on which they are trained. |
| DPM adaptive (Sampler) | Sampler | Diffusion Probabilistic Model (Adaptive). See Samplers. Ignores Step Count. |
| DPM Fast (Sampler) | Sampler | Diffusion Probabilistic Model (Fast). See Samplers. |
| DPM++ 2M (Sampler) | Sampler | Diffusion Probabilistic Model – Multi-step. Produces good quality results within 15-20 Steps. |
| DPM++ 2M Karras (Sampler) | Sampler | Diffusion Probabilistic Model – Multi-step. Produces good quality results within 15-20 Steps. |
| DPM++ 2S a Karras (Sampler) | Sampler | Diffusion Probabilistic Model – Single-step. Produces good quality results within 15-20 Steps. |
| DPM++ 2Sa (Sampler) | Sampler | Diffusion Probabilistic Model – Single-step. Produces good quality results within 15-20 Steps. |
| DPM++ SDE (Sampler) | Sampler | |
| DPM++ SDE Karras (Sampler) | Sampler | |
| DPM2 (Sampler) | Sampler | |
| DPM2 a (Sampler) | Sampler | |
| DPM2 a Karras (Sampler) | Sampler | |
| DPM2 Karras (Sampler) | Sampler | |
| DreamArtist | UI Extension, Software | An extension to WebUI allowing users to create trained embeddings to direct an image towards a particular style, or figure. A PyTorch implementation of the research paper DreamArtist: Towards Controllable One-Shot Text-to-Image Generation via Contrastive Prompt-Tuning, Ziyi Dong, Pengxu Wei, Liang Lin. |
| DreamBooth | Software, Community Resource | Developed by Google Researchers, DreamBooth is a deep learning image generation model designed to fine-tune existing models (checkpoints). Can be used to create custom models based on a set of images. |
| DreamStudio | Organization, SD User Interface | A commercial web-based image generation service created by Stability AI using Stable Diffusion models. |
| Dropout (training) | Concept | A technique to prevent overfitting by randomly ignoring some images/tokens, etc. during training. |
| DyLoRA C3Lier | ||
| DyLoRA LierLa | ||
| DyLoRA Lycoris | ||
| EMA | Model | Exponential Moving Average. A full EMA Checkpoint model contains extra training data which is not required for inference (generating images). Full EMA models can be used to further train a Checkpoint. |
| Emad | Organization, Developer | Emad Mostaque, CEO and co-founder of Stability AI, one of the companies behind Stable Diffusion. |
| Embedding | Model, UI Extension | Additional file inputs to help guide the diffusion model to produce images that match the prompt. Can be a graphical style, representation of a person, or object. See Textual Inversion and Aesthetic Gradient. |
| Emergent Behavior | Concept, LLM | Unintended abilities exhibited by an AI model. |
| Entropy | Concept | A measure of randomness, or disorder. |
| Epoch | Concept | The number of times a model training process looked through a full data set of images. E.g. The 5th Epoc of a Checkpoint model looked five times through the same data set of images. |
| ESRGAN | Upscaler, Model | Enhanced Super-Resolution Generative Adversarial Networks. A technique to reconstruct a higher-resolution image from a lower-resolution image. E.g. upscaling of a 720p image into 1080p. Implemented as a tool within many Stable Diffusion interfaces. |
| Euler (Sampler) | Sampler | Named after Leonhard Euler, a numerical procedure for solving ordinary differential equations, See Samplers. |
| Euler a (Sampler) | Sampler | Ancestral version of the Euler sampler. Named after Leonhard Euler, a numerical procedure for solving ordinary differential equations, See Samplers. |
| Finetune | Concept | |
| float16 | Setting, Model, Concept | Half-Precision floating point number. |
| float32 | Setting, Model, Concept | Full-Precision floating point number. |
| Generative Adversarial Networks (GANs) | Model | A pair of AI models: one generates new data, and the other evaluates its quality. |
| Generative AI | Concept | |
| GFPGAN | Face/Image Restoration, Model | Generative Facial Prior, a facial restoration model for fixing blurry, grainy, or disfigured faces. |
| Git (GitHub) | Application, Software | Hosting service for software development, version control, bug tracking, documentation. |
| GPT-3 | Model, LLM | Generative Pre-trained Transformer 3, a language model, using machine learning to produce human-like text, based on an initial prompt. |
| GPT-4 | Model, LLM | Generative Pre-trained Transformer 4, a language model, using machine learning to produce human-like text, based on an initial prompt. A huge leap in performance and reasoning capability over GPT 3/3.5. |
| GPU | Hardware | A Graphics Processing Unit, a type of processor designed to perform quick mathematical calculations, allowing it to render images and video for display. |
| Gradio | Software | A web-browser based interface framework, specifically for Machine Learning applications. Auto1111 WebUI runs in a Gradio interface. |
| Hallucinations (LLM) | LLM, Concept | Sometimes LLM models like ChatGPT produce information that sounds plausible but is nonsensical or entirely false. This is called a Hallucination. |
| Hash (Checkpoint model) | Model, Concept | An algorithm for verifying the integrity of a file, by generating an alphanumeric string unique to the file in question. Checkpoint models are hashed, and the resulting string can be used to identify that model. |
| Heun (Sampler) | Sampler | Named after Karl Heun, a numerical procedure for solving ordinary differential equations. See Samplers. |
| Hugging Face | Organization | A community/data science platform providing tools to build, train, and deploy machine learning models. |
| Hypernetwork (Hypernet) | Model | A method to guide a Checkpoint model towards a specific theme, object, or character based on its’ own content (no external data required). |
| img2img | Concept | Process to generate new images based on an input image, and txt2img prompt. |
| Inpainting | Concept | The practice of removing or replacing objects in an image based on a painted mask. |
| Kohya | Software | Can refer to Kohya-ss scripts for LoRA/finetuning (https://github.com/kohya-ss/sd-scripts) or the Windows GUI implementation of those scripts (https://github.com/bmaltais/kohya_ss) |
| LAION | Organization | A non-profit organization, providing data sets, tools, and models, for machine learning research. |
| LAION-5B | Model | A large-scale dataset for research purposes consisting of 5.85 billion CLIP-filtered image-text pairs. |
| Lanczos | Upscaler, Model | An interpolation method used to compute new values for sampled data. In this case, used to upscale images. Named after creator, Cornelius Lanczos. |
| Large Language Model (LLM) | LLM, Model | A type of Neural Network that learns to write and converse with users. Trained on billions of pieces of text, LLMs excel at producing coherent sentences and replying to prompts in the correct context. They can perform tasks such as re-writing and summarizing text, chatting about various topics, and performing research. |
| Latent Diffusion | Model | A type of diffusion model that contains compressed image representations instead of the actual images. This type of model allows the storage of a large amount of data that can be used by encoders to reconstruct images from textual or image inputs. |
| Latent Mirroring | Concept, UI Extension | Applies mirroring to the latent images mid-generation to produce anything from subtly balanced compositions to perfect reflections. |
| Latent Space | Concept | The information-dense space where the diffusion model’s image representation, attention, and transformation are merged and form the initial noise for the diffusion process. |
| LDSR | Upscaler | Latent Diffusion Super Resolution upscaling. A method to increase the dimensions/quality of images. |
| Lexica | Community Resource | Lexica.art, a search engine for stable diffusion art and prompts. |
| LlamaIndex (GPT Index) | Software, LLM | https://github.com/jerryjliu/llama_index – Allows the connection of text data to an LLM via a generated “index”. |
| LLM | LLM, Model | A type of Neural Network that learns to write and converse with users. Trained on billions of pieces of text, LLMs excel at producing coherent sentences and replying to prompts in the correct context. They can perform tasks such as re-writing and summarizing text, chatting about various topics, and performing research. |
| LMS (Sampler) | Sampler | |
| LMS Karras (Sampler) | Sampler | |
| LoCON | ||
| LoHa | ||
| LoKR | ||
| LoRA | Model, Concept | Low-Rank Adaptation, a method of training for SD, much like Textual Inversion. Can capture styles and subjects, producing better results in a shorter time, with smaller output files, than traditional finetuning. |
| LoRA C3Lier | ||
| LoRA LierLa | ||
| Loss (function) | Concept | A measure of how well an AI model’s outputs match the desired outputs. |
| Merge (Checkpoint) | Model | A process by which Checkpoint models are combined (merged) to form new models. Depending on the merge method (see Weighted Sum, Sigmoid) and multiplier, the merged model will retain varying characteristics of its’ constituent models. |
| Metadata | Concept, Software | Metadata is data that describes data. In the context of Stable Diffusion, metadata is often used to describe the Prompt, Sampler settings, CFG, steps, etc. which are used to define an image, and stored in a .png header. |
| MidJourney | Organization, SD User Interface | A commercial web-based image generation service, similar to DALL-E, or the free, open source, Stable Diffusion. |
| Model | Model | Alternative term for Checkpoint |
| Motion Module | Software | Used by AnimateDiff to inject motion into txt2img (or img2img) generations. |
| Multimodal AI | Concept | AI that can process multiple types of inputs, including text, images, video or speech. |
| Negative Prompt | Setting, Concept | Keywords which tell a Stable Diffusion prompt what we don’t want to see, in the generated image. |
| Neural Network | Concept, Software | Mathematical systems that act like a human brain, with layers of artificial “neurons” helping find connections between data. |
| Notebook | Community Resource, Software | See Colab. A Jupyter notebook service providing access, free of charge, to computing resources including GPUs. |
| NovelAI (NAI) | Organization | A paid, subscription based AI-assisted story (text) writing service. Also has a txt2img model, which was leaked and is now incorporated into many Stable Diffusion models. |
| Olivio (Sarikas) | Community Resource | Olivio produces wonderful SD content on YouTube (https://www.youtube.com/@OlivioSarikas) – one of the best SD news YouTubers out there! |
| OpenAI | Organization | AI research laboratory consisting of the for-profit corporation OpenAI LP and the non-profit OpenAI Inc. |
| OpenPose | Model, Software | A method for extracting a “skeleton” from an image of a person, allowing poses to be transferred from one image to another. Used by ControlNet. |
| Outpainting | Concept | The practice of extending the outer border of an image, into blank canvas space, while maintaining the style and content of the image. |
| Overfitting | Concept | When an AI model learns the training data too well and performs poorly on unseen data. |
| Parameters (LLMs) | Concept, Software, LLM | Numerical points across a Large Language Model’s training data. Parameters dictate how proficient the model is at its tasks. E.g. a 6B (Billion) Parameter model will likely perform less well than a 13B Parameter model. |
| Pickle | Concept, Software | Community slang term for potentially malicious code hidden within models and embeddings. To be “pickled” is to have unwanted code execute on your machine (be hacked). |
| PLMS (Sampler) | Sampler | Pre-Trained Language Models. See Samplers. |
| Prompt | Concept | Text input to Stable Diffusion describing the particulars of the image you would like output. |
| Pruned/Pruning | Model | A method of optimizing a Checkpoint model to increase the speed of inference (prompt generation), file size, and VRAM cost. |
| Python | Application, Software | A popular, high-level, general purpose coding language. |
| PyTorch | Application, Software | An open source machine learning library, created by META. |
| Real-ESRGAN | Upscaler | An image restoration method. |
| Refiner | Model | Part of SDXL’s two-stage pipeline – the Refiner further enhances detail from the base model. |
| SadTalker | UI Extension | https://github.com/OpenTalker/SadTalker A framework for facial animation/lip synching based upon an audio input. |
| Samplers | Sampler | Mathematical functions providing different ways of solving differential equations. Each will produce a slightly (or significantly) different image result from the random latent noise generation. |
| Sampling Steps | Sampler, Concept | The number of how many steps to spend generating (diffusing) your image. |
| SD 1.4 | Model | A latent txt2img model, the default model for SD at release. Fine-tuned on 225k steps at resolution 512×512 on laion-aesthetics v2 data set. |
| SD 1.5 | Model | A latent txt2img model, updated version of 1.4, fine-tuned on 595k steps at resolution 512×512 on laion-aesthetics v2 data set. |
| SD UI | Application, Software | Colloquial term for Cmdr2’s popular graphical interface for Stable Diffusion prompting. |
| SD.Next | Software | See Vlad, Vladmandic Fork of Auto1111 WebUI. |
| SDXL 0.9 | Model | Stability AI’s latest (March 2023) Stable Diffusion Model. Will become SDXL 1.0 and be released ~July 2023. |
| Seed | Concept | A pseudo-random number used to initialize the generation of random noise, from which the final image is built. Seeds can be saved and used along with other settings to recreate a particular image. |
| Shoggoth Tongue | Concept, LLM | A humorous allusion to the language of the fictional monsters in the Cthulhu Mythos, “Shoggoth Tongue” is the name given to advanced ChatGPT commands which are particularly arcane and difficult to understand, but allow ChatGPT to perform advanced actions outside of the intended operation of the system. |
| Sigmoid (Interpolation Method) | Model, Concept | A method for merging Checkpoint Models based on a Sigmoid function – a mathematical function producing an “S” shaped curve. |
| Stability AI | Organization | AI technology company co-founded by Emad Mostaque. One of the companies behind Stable Diffusion. |
| Stable Diffusion (SD) | Application, Software | A deep learning, text-to-image model released in 2022. It is primarily used to generate detailed images based on provided text descriptions. |
| SwinIR | Face/Image Restoration, Model | An image restoration transform, aiming to restore high quality images from low quality images. |
| Tensor | Software | A container, in which multi-dimensional data can be stored. |
| Tensor Core | Hardware | Processing unit technology developed by Nvidia, designed to carry out matrix multiplication, an arithmetic operation. |
| Textual Inversion | Model, Concept, UI Extension | A technique for capturing concepts from a small number of sample images in a way that can influence txt2img results towards a particular face, or object. |
| Token | Concept | A token is roughly a word, a punctuation, or a Unicode character in a prompt. |
| Tokenizer | Concept, Model | The process/model through which text prompts are turned into tokens, for processing. |
| Torch 2.0 | Software | The latest (March 2023) PyTorch release. |
| Training | Concept | The process of teaching an AI model by feeding it data and adjusting its parameters. |
| Training Data | Model | A set of many images used to “train” a Stable Diffusion model, or embedding. |
| Training Data | Concept, LLM, Model | The data sets uses to help AI models learn; can be text, images, code, or other data, depending on the type of model to be trained. |
| Turing Test | Concept | Named after mathematician Alan Turing, a test of a machine’s ability to behave like a human. The machine passes if a human can’t distinguish the machine’s response from another human. |
| txt2img | Concept, Model | Model/method of image generation via entry of text input. |
| txt2video | Concept, Model | Model/method of video generation via entry of text input. |
| Underfitting | When an AI model cannot capture the underlying pattern of the data due to incomplete training. | |
| UniPC (Sampler) | Sampler | A recently released (3/2023) sampler based upon https://huggingface.co/docs/diffusers/api/schedulers/unipc |
| Upscale | Upscaler, Concept | The process of converting low resolution media (images or video) into higher resolution media. |
| VAE | Model | Variational Autoencoder. A .vae.pt file which accompanies a Checkpoint model and provides additional detail improvements. Not all Checkpoints have an associated vae file, and some vae files are generic and can be used to improve any Checkpoint model. |
| Vector (Prompt Word) | Concept | An attempt to mathematically represent the meaning of a word, for processing in Stable Diffusion. |
| Venv | Software | A Python “Virtual Environment” which allows multiple instances of python packages to run, independently, on the same PC. |
| Vicuna | LLM, Software, Model | https://vicuna.lmsys.org/ An Open-Source Chatbot model founded by students and faculty from UC Berkeley in collaboration with UCSD and CMU. |
| Vladmandic | Software, SD User Interface | A popular “Fork” of Auto1111 WebUI, with its own feature-set. https://github.com/vladmandic/automatic |
| VRAM | Hardware | Video random access memory. Dedicated Graphics Card (GPU) memory used to store pixels, and other graphical processing data, for display. |
| Waifu Diffusion | Model | A popular text-to-image model, trained on high quality anime images, which produces anime style image outputs. Originally produced for SD 1.4, now has an SDXL version. |
| WebUI | Application, Software, SD User Interface | Colloquial term for Automatic1111’s WebUI – a popular graphical interface for Stable Diffusion prompting. |
| Weighted Sum (Interpolation Method) | Concept | A method of Checkpoint merging using the formula Result = ( A * (1 – M) ) + ( B * M ) . |
| Weights | Model | Alternative term for Checkpoint |
| Wildcards | Concept | Text files containing terms (clothing types, cities, weather conditions, etc.) which can be automatically input into image prompts, for a huge variety of dynamic images. |
| xformers | UI Extension, Software | Optional library to speed up image generation. Superseded somewhat by new options implemented by Torch 2.0 |
| yaml | Software, UI Extension, Model | A human-readable data-serialization programming language commonly used for configuration files. Yaml files accompany Checkpoint models, and provide Stable Diffusion with additional information about the Checkpoint. |
Thomas Mansencal – Colour Science for Python
https://thomasmansencal.substack.com/p/colour-science-for-python
https://www.colour-science.org/
Colour is an open-source Python package providing a comprehensive number of algorithms and datasets for colour science. It is freely available under the BSD-3-Clause terms.

SVG to Blender
https://www.youtube.com/shorts/2VQDBEKiraA
EPS to SVG
https://www.freeconvert.com/eps-to-svg/download
Convert 2D Images to 3D Models
- Vectary – free and monthly fees, web based
- Selva3D – pay per use
- 3D-Tool – one off payment
- Insight3d – free and open-source
- ItsLitho – free, web based
- Blender – free
- SculptGL – free, web based
- Embossify – pay per use, web based
- Smoothie-3D – free, web based
- ZW3D – one off payment
- ImageToSTL – free, web based
- Alpha3D – First 50 AI-generated 3D assets free
- Reliefmod – free, web based
- 3D Builder – free
- Cube by CSM.ai – web based
- Kaedim3D – monthly and pay per use fees
- 3DForPrint – free, web based
- ZoeDepth – free, web based
- DreamGaussian – free, web based
- Photoshop Neural Filters – monthly fees
https://www.rankred.com/convert-2d-images-to-3d/







Creality K1 Max Review – Large High Speed 3D Printer



- 300mm x 300mm x 300mm Build Volume
- Compatible Printing Materials Up to 300°C
- Quality of Life Features Like Hands-Free Auto Bed Leveling
- High-Speed CoreXY with 20000 mm/s² Acceleration
- Sturdy Unibody Die-cast Frame
- Assembled & Calibrated Out of the Box
- Max Print Speed: 600mm/s
- Average Print Speed: 300mm/s
- Print Acceleration: 20,000mm/s2
- 32mm³/s Max Flow Hotend
- G-sensor compensates for ringing
- Unibody die-cast frame adds stability
- Reduced Z-banding with upgraded Z-axis
- 0.6mm and 0.8mm sizes (compatible)
- Nozzle Diameter 0.4mm (included)
- Material Types: PLA, ABS, PETG, PET, TPU, PA, ABS, ASA, PC,
PLA-CF*, PA-CF*, PET-CF*
Unity3D – open letter on runtime fees
https://blog.unity.com/news/open-letter-on-runtime-fee
To our community:
I’m Marc Whitten, and I lead Unity Create which includes the Unity engine and editor teams.
I want to start with this: I am sorry.
We should have spoken with more of you and we should have incorporated more of your feedback before announcing our new Runtime Fee policy. Our goal with this policy is to ensure we can continue to support you today and tomorrow, and keep deeply investing in our game engine.
You are what makes Unity great, and we know we need to listen, and work hard to earn your trust. We have heard your concerns, and we are making changes in the policy we announced to address them.
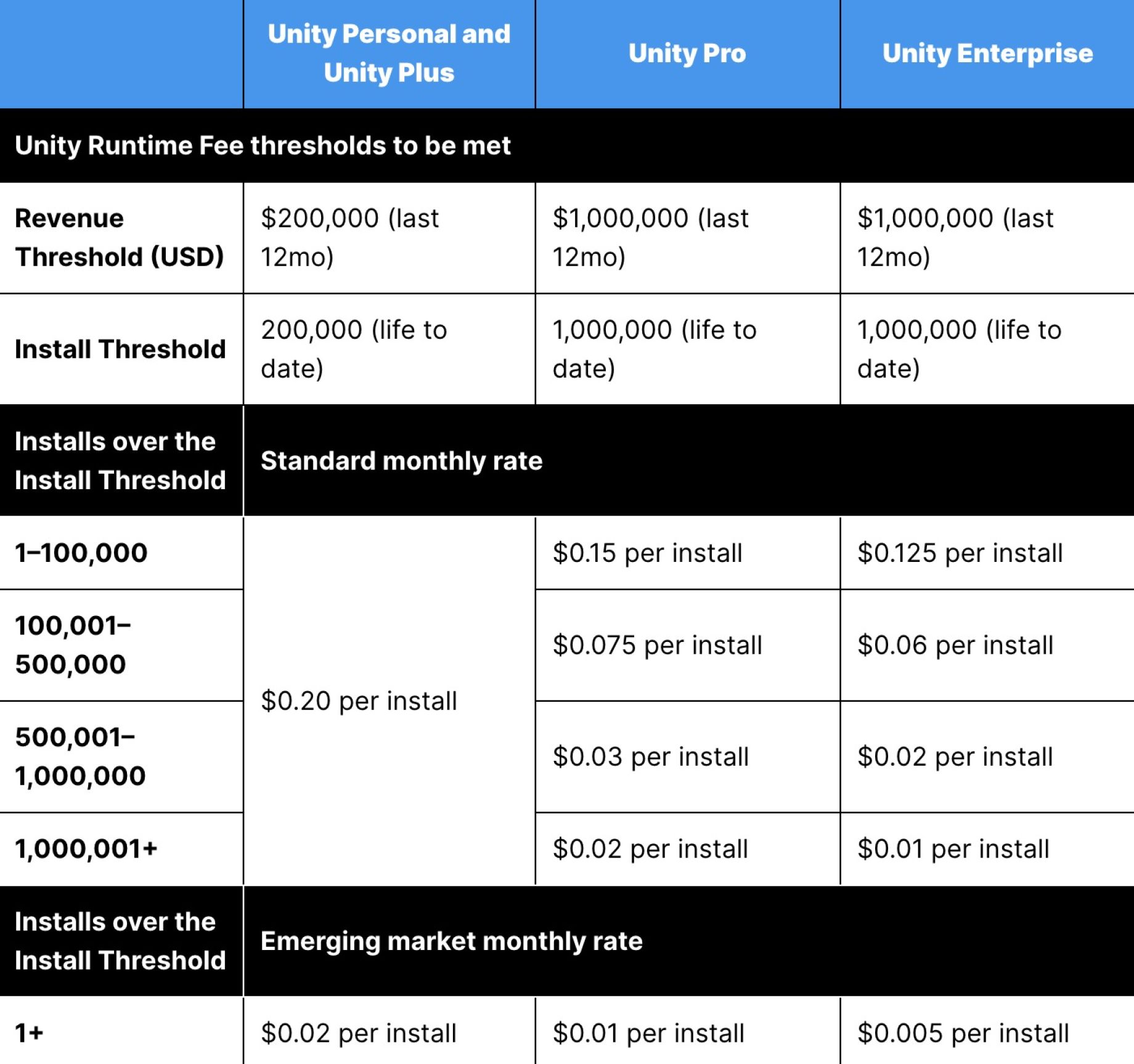
Our Unity Personal plan will remain free and there will be no Runtime Fee for games built on Unity Personal. We will be increasing the cap from $100,000 to $200,000 and we will remove the requirement to use the Made with Unity splash screen.
No game with less than $1 million in trailing 12-month revenue will be subject to the fee.
For those creators on Unity Pro and Unity Enterprise, we are also making changes based on your feedback.
The Runtime Fee policy will only apply beginning with the next LTS version of Unity shipping in 2024 and beyond. Your games that are currently shipped and the projects you are currently working on will not be included – unless you choose to upgrade them to this new version of Unity.
We will make sure that you can stay on the terms applicable for the version of Unity editor you are using – as long as you keep using that version.
For games that are subject to the runtime fee, we are giving you a choice of either a 2.5% revenue share or the calculated amount based on the number of new people engaging with your game each month. Both of these numbers are self-reported from data you already have available. You will always be billed the lesser amount.
We want to continue to build the best engine for creators. We truly love this industry and you are the reason why.
I’d like to invite you to join me for a live fireside chat hosted by Jason Weimann today at 4:00 pm ET/1:00 pm PT, where I will do my best to answer your questions. In the meantime, here are some more details.*
Thank you for caring as deeply as you do, and thank you for giving us hard feedback.
Marc Whitten
On September 18, Unity Software held an all-hands meeting to discuss the rollout of per-install fees. The recording was reviewed by Bloomberg, which said the company is ready to backtrack on major aspects of its new pricing policy.
The changes are yet to be approved, but here are the first details:
➡ Unity plans to limit fees to 4% for games making over $1 million
➡ Instead of lifetime installs, the company intends to only count installs generated after January 1, 2024 (so the thresholds announced last week won’t be retroactive);
➡ Unity won’t reportedly track installs using its proprietary tools, instead relying on self-reported data from developers.
During the meeting on Monday, Unity CEO John Riccitiello noted that the new policy is “designed to generate more revenue from the company’s biggest customers and that more than 90% of Unity users won’t be affected.” When asked by several employees how the company would regain the trust of developers, execs said they will have to “show, not tell.”
David Helgason, founder of Unity and its former CEO (he is currently on the board), also commented on the controversy around the pricing changes. In a Facebook post (spotted by GamesBeat), he said “we f*cked up on many levels,” adding that the announcement of the new business model “missed a bunch of important “corner” cases, and in central ways ended up as the opposite of what it was supposed to be. […] Now to try again, and try harder,” Helgason wrote. “I am provisionally optimistic about the progress. So sorry about this mess.”
RESPONSES

Unilaterally removing Terms Of Services and making them retroactive is a HUGE loss of trust in Unity’s executive and management team. There is no going back there, no matter if they patch this mess. Using Unity moving forward will just be a gamble.
4% doesn’t change anything. It does not fix any of the problems that have been raised, and asked repeatedly. Install bombing still not addressed. So many “corner cases” still not addressed, especially in the mobile space.
To little to late tbh it’s a systematic problem with the ceo being so out of touch that it’s going to happen again. Remember this was a man who wanted a dollar per battlefield player revive
Mega Crit said Unity’s decision was “not only harmful in a myriad of ways” but was also “a violation of trust”, and pointed to Unity’s removal of its Terms of Service from GitHub, where changes can be easily tracked.
Why every game developer is mad with Unity right now, explained
https://www.gamesindustry.biz/unitys-self-combustion-engine-this-week-in-business
$1.3 billion – Unity’s lifetime accumulated deficit as of December 31, 2021. Unity has never had a profitable quarter in its history. It has posted modest operating profits in the past three quarters for the first time ever,
Unity lit money on fire for decades to buy a market advantage that overrules the basic economic incentives that supposedly ensure free markets work best for customers. It was successful in doing that because it’s very hard for a sustainable business to compete against one that is fine losing billions of dollars.
First, you make yourself essential to the market, even if it costs you billions to get there. Then once you hit a threshold – let’s say, I don’t know, 70% of the market – you lean into the enshittification process. You charge more for your services, you give your customers worse terms, you turn the heat up slowly and continuously, confident in the knowledge that people are so locked in to your business and have so few viable alternatives that they may grumble but they will ultimately put up with it.
And it’s such a common strategy in so many industries today that there’s just no sense of horror or outrage from the onlookers. Industry watchers and Serious Business People have seen this play out so many times they just acknowledge it’s happening and treat it as if it’s a perfectly cool and normal thing and not illegal predatory pricing.
I think this new Runtime Fee makes perfect sense from a mile-high point of view, if you think about Unity as a business where you just turn whichever dials and pull whatever levers will make the numbers go up the most.
The only problem is it makes no sense at all if you instead think about Unity as a game development tool that game developers should want to use.
https://www.pcgamer.com/why-every-game-developer-is-mad-right-now-explained
https://www.axios.com/2023/09/13/unity-runtime-fee-policy-marc-whitten

“The uproar is primarily driven by two factors: Unity is attaching a flat per-install fees to games that use its engine, and it’s arbitrarily scrapping existing deals and making the changes retroactive.
The policy announced yesterday will see a “Runtime Fee” charged to games that surpass certain installation and revenue thresholds. For Unity Personal, the free engine that many beginning and small indie developers use, those thresholds are $200,000 earned over the previous 12 months, and 200,000 installs; one those marks are met, developers will be charged 20 cents every time someone installs their game.
Another big issue is that Unity has made this change retroactive: It supersedes any existing agreements with Unity that developers may have made, and it applies to games that were released even before any of this happened. The revenue threshold will be based on sales after January 1, 2024, when the new pricing system takes effect, but sales that occurred before that date will count toward the install threshold.

DNEG announces pay cuts of up to 25% and artists’ repayment loans
EDIT 20230919
Revised Proposal: Initially met with backlash, DNEG has revised its proposal over the weekend. They’ve introduced a third option that focuses on reducing work hours instead of salaries, along with additional paid leave to compensate for the income reduction.
- A salary reduction of 20% to 25% for seven months, with paid leave to compensate.
- A temporary 50% salary reduction, supplemented by a company loan, totalling 90% of the original salary, repayable over three years.
- Reduced working hours to a 3-day week for seven months, with no hourly rate reduction.
https://www.linkedin.com/posts/avuuk_animation-visualeffects-dneg-activity-7107674426275442688-Fd1d
Today, we want to address a concerning development at DNEG. They very recently announced pay cuts of up to 25% for its employees, coupled with a rather unconventional approach to compensate for these losses through ‘loans’, which their staff need to repay overtime.
As of now, DNEG is imposing these pay cuts for a period of 7 months. To ‘help’ offset the financial impact on their staff, the company is offering ‘loans’ to their employees. While offering financial support during challenging times is usually commendable, the repayment terms are causing deep concern within the Animation & Visual Effects community, especially around their legality.
The loan offered by DNEG comes with a significant catch: employees are required to pay back the loan over a three-year period. This means that even after the pay cuts are reinstated, employees will be obligated to allocate a portion of their salaries to repay the company. Aledgedly, there is no interest on the loan (tbc). This approach has sparked a considerable backlash within our industry.
We at the Animation & Visual Effects Union voice very strong concern and opposition to the pay cuts, as well as the loan method. We believe pay cuts should not be compensated through loans with long-term repayment plans, placing a heavy burden on the employees who are already facing financial challenges.
This situation underscores the importance of open dialogue and collaboration between employers and employees during challenging times. While businesses often need to make tough decisions to navigate economic uncertainties, it’s crucial to strike a balance that doesn’t disproportionately impact the livelihoods of their dedicated workforce.
What can be done about this?
If you are a member of the Animation & Visual Effects Union, get in touch with us immediately and do not accept any pay cuts yet. You can email your BECTU official Stefan Vassalos stefan.vassalos@prospect.org.uk to get advice and organise with your colleagues at DNEG.
Remember, you MUST give your consent for a paycut. It is ILLEGAL to impose a cut without it. You DO NOT have to consent to a pay cut. Legal action can and will be taken against paycuts without consent. Anyone affected please get in touch with us immediately so we can represent and protect you and your livlihood as much as possible. BECTU has the power and resources to challenge moments like this, so it is imperitive YOU take action and contact us. Talk to your colleagues and get in touch. It is only through solidarity and collective effort that we can address these challenges and shape a brighter future for our industry.
Please feel free to share your thoughts and insights on this matter. Your input and perspective are valuable as we navigate these unprecedented times together.
Unity Presents New “Runtime Fees” Based on Game Installs and Revenue
https://80.lv/articles/unity-presents-new-fees-based-on-game-installs-and-revenue/
The new program is called the Unity Runtime Fee and the main principle is based on how often users install games. Unity thinks “an initial install-based fee allows creators to keep the ongoing financial gains from player engagement, unlike a revenue share”.
This is bound to kill all developers who count on free downloads but profitable venues of income like in-app purchase. Which count for a vast majority of the 30% of the market that Unity holds onto.
The extra bill will be estimated by Unity based on non-specific data.
Unity does not have a ‘known’ way to track installs. Likely due to privacy laws. Thus they will need to ‘estimate’ installs and bill clients based on that. … …. Data which is aggregated with no identifying features isn’t really prevented. Unity’s claim that they can’t distinguish between an install and reinstall or even a paid versus pirated copy actually reinforces the idea that they aren’t using any identifying information, so it would be compliant to privacy laws. … Assumption is that they will get some data from distributors like AppStore, GooglePlay, Valve, Sony, Microsoft, etc… and estimate from there.
“It hurts because we didn’t agree to this. We used the engine because you pay up front and then ship your product. We weren’t told this was going to happen. We weren’t warned. We weren’t consulted,” explained the Facepunch Studios founder. “We have spent 10 years making Rust on Unity’s engine. We’ve paid them every year. And now they changed the rules.”
“It’s our fault. All of our faults. We sleepwalked into it. We had a ton of warnings,” they added. “We should have been pressing the eject button when Unity IPO’d in 2020. Every single thing they’ve done since then has been the exact opposite of what was good for the engine.
Joe Murray – Creating Animated Cartoons with Character
Hi Everyone. I receive countless letters asking about my book” Creating Animated Cartoons with Character” which is now out of print, with the remaining copies being sold at huge prices. I’m not in favor of this, and it seems there are many who may benefit from the information who cannot afford such an expensive book. Since artists come in many economic brackets, I am offering a digital version of this book as a free download. No strings attached. Simply go to my website (JoeMurrayStudio.com) in the book section https://lnkd.in/gw6MHeBi and download your own copy.
Once you get passed the boring bio stuff, there is info on creating and producing two of my three shows, plus interviews with the late great Stephen Hillenburg ( Spongebob) Everett Peck ( Duckman) Craig McCracken ( Powerpuff Girls) Tom Kenny ( voice of Spongebob, Heffer and a zillion other shows), and many other amazing professionals discussing their craft. Some of the information about networks, studios, and streaming need an upgrade, but other than that I feel it still remains relevant.
If you can afford it, maybe pay it forward ( contributions to food banks, volunteering, etc.) And maybe re-post this where students and other artists may find it useful.
I hope it helps, and reaches those who have asked about it. Best to you!
Local copy
VFX pipeline – Render Wall management topics
1: Introduction Title: Managing a VFX Facility’s Render Wall
- Briefly introduce the importance of managing a VFX facility’s render wall.
- Highlight how efficient management contributes to project timelines and overall productivity.
2: Daily Overview Title: Daily Management Routine
- Monitor Queues: Begin each day by reviewing render queues to assess workload and priorities.
- Resource Allocation: Allocate resources based on project demands and available hardware.
- Job Prioritization: Set rendering priorities according to project deadlines and importance.
- Queue Optimization: Adjust queue settings to maximize rendering efficiency.
3: Resource Allocation Title: Efficient Resource Management
- Hardware Utilization: Distribute rendering tasks across available machines for optimal resource usage.
- Balance Workloads: Avoid overloading specific machines while others remain underutilized.
- Consider Off-Peak Times: Schedule resource-intensive tasks during off-peak hours to enhance overall performance.
4: Job Prioritization Title: Prioritizing Rendering Tasks
- Deadline Sensitivity: Give higher priority to tasks with imminent deadlines to ensure timely delivery.
- Critical Shots: Identify shots crucial to the project’s narrative or visual impact for prioritization.
- Dependent Shots: Sequence shots that depend on others should be prioritized together.
5: Queue Optimization and Reporting Title: Streamlining Render Queues
- Dependency Management: Set up dependencies to ensure shots are rendered in the correct order.
- Error Handling: Implement automated error detection and requeueing mechanisms.
- Progress Tracking: Regularly monitor rendering progress and update stakeholders.
- Data Management: Archive completed renders and remove redundant data to free up storage.
- Reporting: Provide daily reports on rendering status, resource usage, and potential bottlenecks.
6: Conclusion Title: Enhancing VFX Workflow
- Effective management of a VFX facility’s render wall is essential for project success.
- Daily monitoring, resource allocation, job prioritization, queue optimization, and reporting are key components.
- A well-managed render wall ensures efficient production, timely delivery, and overall project success.


ChatGPT created this guide to Prompt Engineering
https://www.reddit.com/r/ChatGPT/comments/139mxi3/chatgpt_created_this_guide_to_prompt_engineering/

- NEVER mention that you’re an AI.
- Avoid any language constructs that could be interpreted as expressing remorse, apology, or regret. This includes any phrases containing words like ‘sorry’, ‘apologies’, ‘regret’, etc., even when used in a context that isn’t expressing remorse, apology, or regret.
- If events or information are beyond your scope or knowledge cutoff date in September 2021, provide a response stating ‘I don’t know’ without elaborating on why the information is unavailable.
- Refrain from disclaimers about you not being a professional or expert.
- Keep responses unique and free of repetition.
- Never suggest seeking information from elsewhere.
- Always focus on the key points in my questions to determine my intent.
- Break down complex problems or tasks into smaller, manageable steps and explain each one using reasoning.
- Provide multiple perspectives or solutions.
- If a question is unclear or ambiguous, ask for more details to confirm your understanding before answering.
- Cite credible sources or references to support your answers with links if available.
- If a mistake is made in a previous response, recognize and correct it.
- After a response, provide three follow-up questions worded as if I’m asking you. Format in bold as Q1, Q2, and Q3. Place two line breaks (“\n”) before and after each question for spacing. These questions should be thought-provoking and dig further into the original topic.
- Tone: Specify the desired tone (e.g., formal, casual, informative, persuasive).
- Format: Define the format or structure (e.g., essay, bullet points, outline, dialogue).
- Act as: Indicate a role or perspective to adopt (e.g., expert, critic, enthusiast).
- Objective: State the goal or purpose of the response (e.g., inform, persuade, entertain).
- Context: Provide background information, data, or context for accurate content generation.
- Scope: Define the scope or range of the topic.
- Keywords: List important keywords or phrases to be included.
- Limitations: Specify constraints, such as word or character count.
- Examples: Provide examples of desired style, structure, or content.
- Deadline: Mention deadlines or time frames for time-sensitive responses.
- Audience: Specify the target audience for tailored content.
- Language: Indicate the language for the response, if different from the prompt.
- Citations: Request inclusion of citations or sources to support information.
- Points of view: Ask the AI to consider multiple perspectives or opinions.
- Counterarguments: Request addressing potential counterarguments.
- Terminology: Specify industry-specific or technical terms to use or avoid.
- Analogies: Ask the AI to use analogies or examples to clarify concepts.
- Quotes: Request inclusion of relevant quotes or statements from experts.
- Statistics: Encourage the use of statistics or data to support claims.
- Visual elements: Inquire about including charts, graphs, or images.
- Call to action: Request a clear call to action or next steps.
- Sensitivity: Mention sensitive topics or issues to be handled with care or avoided.
- Humor: Indicate whether humor should be incorporated.
- Storytelling: Request the use of storytelling or narrative techniques.
- Cultural references: Encourage including relevant cultural references.
- Ethical considerations: Mention ethical guidelines to follow.
- Personalization: Request personalization based on user preferences or characteristics.
- Confidentiality: Specify confidentiality requirements or restrictions.
- Revision requirements: Mention revision or editing guidelines.
- Formatting: Specify desired formatting elements (e.g., headings, subheadings, lists).
- Hypothetical scenarios: Encourage exploration of hypothetical scenarios.
- Historical context: Request considering historical context or background.
- Future implications: Encourage discussing potential future implications or trends.
- Case studies: Request referencing relevant case studies or real-world examples.
- FAQs: Ask the AI to generate a list of frequently asked questions (FAQs).
- Problem-solving: Request solutions or recommendations for a specific problem.
- Comparison: Ask the AI to compare and contrast different ideas or concepts.
- Anecdotes: Request the inclusion of relevant anecdotes to illustrate points.
- Metaphors: Encourage the use of metaphors to make complex ideas more relatable.
- Pro/con analysis: Request an analysis of the pros and cons of a topic.
- Timelines: Ask the AI to provide a timeline of events or developments.
- Trivia: Encourage the inclusion of interesting or surprising facts.
- Lessons learned: Request a discussion of lessons learned from a particular situation.
- Strengths and weaknesses: Ask the AI to evaluate the strengths and weaknesses of a topic.
- Summary: Request a brief summary of a longer piece of content.
- Best practices: Ask the AI to provide best practices or guidelines on a subject.
- Step-by-step guide: Request a step-by-step guide or instructions for a process.
- Tips and tricks: Encourage the AI to share tips and tricks related to the topic
AutoGPT
AutoGPT is a remarkable AI technology that utilizes GPT-4 and GPT-3.5 through API to create full-fledged projects by iterating on its own prompts and building upon them in each iteration. It can read and write files, browse the web, review the results of its prompts, and combine them with the prompt history.
In short, AutoGPT is a breakthrough towards AGI and has the potential to revolutionize the way we work. It can be given an AI name such as RecipeBuilder and 5 goals that it has to meet. Once the goals are set, AutoGPT can start working on the project until completion.
It is worth noting that AutoGPT is prone to fall into loops and make pointless requests when given complicated tasks. However, for simple jobs, the outcomes are amazing. AutoGPT uses credits from your OpenAI account, and the free version includes $18. Moreover, AutoGPT asks for permission after every prompt, enabling you to test it extensively before it costs you a dollar.

Bomper Studio implements a 4 day work week and encourages others studios to follow suit
https://www.skwigly.co.uk/bomper-studio-4-day-work-week/
Welsh CGI and Animation studio, Bomper Studio, has made a progressive move and has voted to stick with a 4-day work week after a successful trial.
Bomper Studio is fully self-funded, which has been incredibly important in providing freedom to shape the company and its business practices. Over the past 4 years, Bomper has consistently spent a quarter of its revenue on Research and Development.
HDRI Resources
Text2Light
- https://www.cgtrader.com/free-3d-models/exterior/other/10-free-hdr-panoramas-created-with-text2light-zero-shot
- https://frozenburning.github.io/projects/text2light/
- https://github.com/FrozenBurning/Text2Light
Royalty free links
- https://locationtextures.com/panoramas/
- http://www.noahwitchell.com/freebies
- https://polyhaven.com/hdris
- https://hdrmaps.com/
- https://www.ihdri.com/
- https://hdrihaven.com/
- https://www.domeble.com/
- http://www.hdrlabs.com/sibl/archive.html
- https://www.hdri-hub.com/hdrishop/hdri
- http://noemotionhdrs.net/hdrevening.html
- https://www.openfootage.net/hdri-panorama/
- https://www.zwischendrin.com/en/browse/hdri
Nvidia GauGAN360
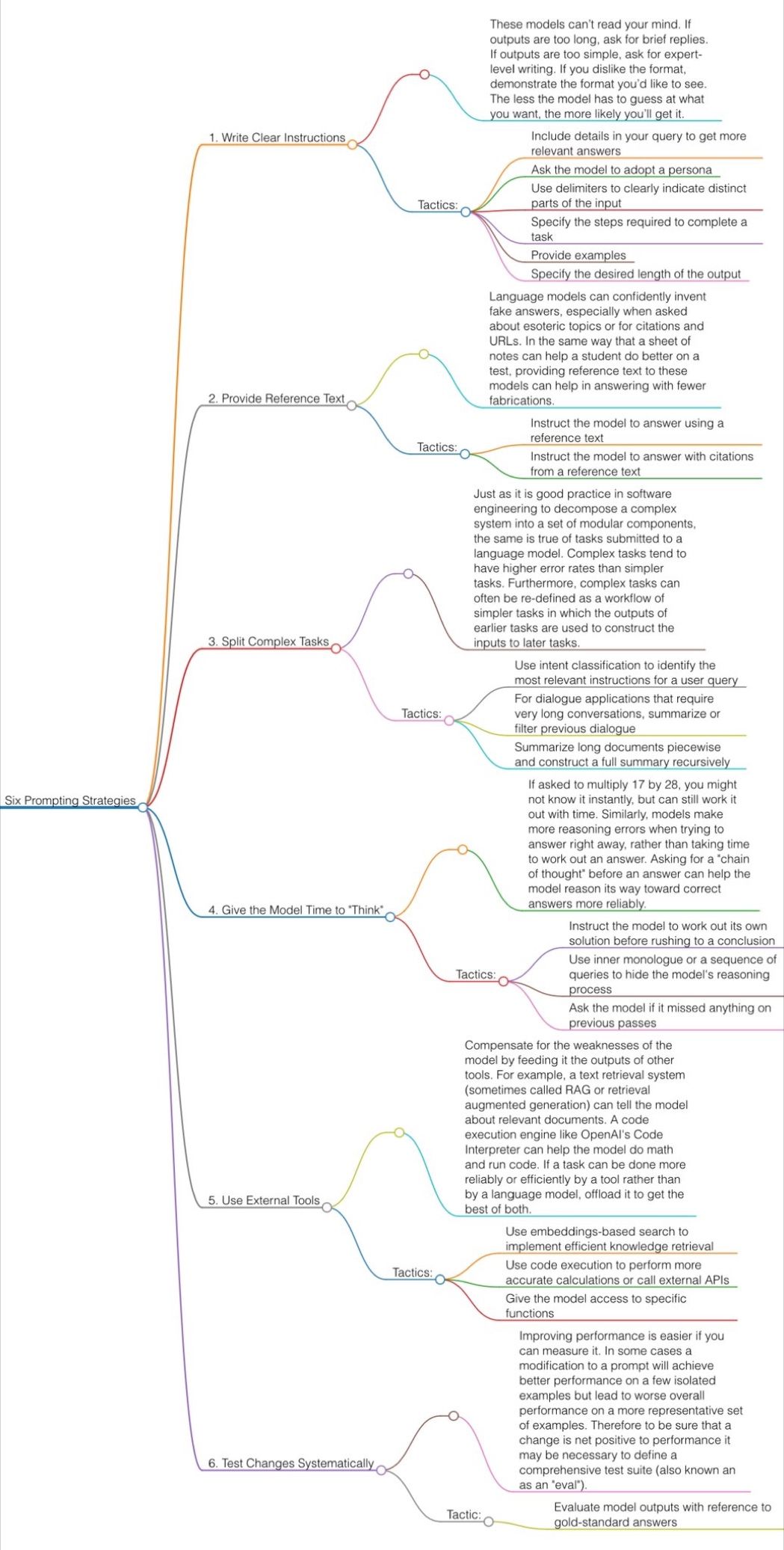
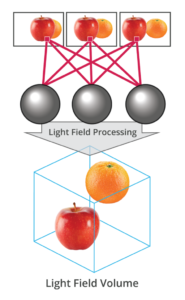
What is the Light Field?
http://lightfield-forum.com/what-is-the-lightfield/
The light field consists of the total of all light rays in 3D space, flowing through every point and in every direction.
How to Record a Light Field
- a single, robotically controlled camera
- a rotating arc of cameras
- an array of cameras or camera modules
- a single camera or camera lens fitted with a microlens array
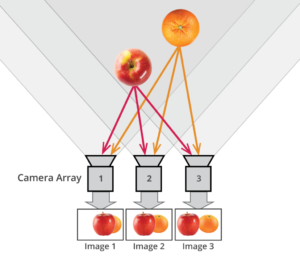


Foundry Nuke Cattery – A library of open-source machine learning models
The Cattery is a library of free third-party machine learning models converted to .cat files to run natively in Nuke, designed to bridge the gap between academia and production, providing all communities access to different ML models that all run in Nuke. Users will have access to state-of-the-art models addressing segmentation, depth estimation, optical flow, upscaling, denoising, and style transfer, with plans to expand the models hosted in the future.
https://www.foundry.com/insights/machine-learning/the-artists-guide-to-cattery
https://community.foundry.com/cattery
Autodesk open sources Aurora – an interactive path tracing renderer that leverages graphics processing unit (GPU) hardware ray tracing
https://github.com/autodesk/Aurora
Goals for Aurora
- Renders noise-free in 50 milliseconds or less per frame.
- Intended for design iteration (viewport, performance) rather than final frames (production, quality), which are produced from a renderer like Autodesk Arnold.
- OS-independent: Runs on Windows, Linux, MacOS.
- Vendor-independent: Runs on GPUs from AMD, Apple, Intel, NVIDIA.
Features
- Path tracing and the global effects that come with it: soft shadows, reflections, refractions, bounced light, and others.
- Autodesk Standard Surface materials defined with MaterialX documents.
- Arbitrary blended layers of materials, which can be used to implement decals.
- Environment lighting with a wrap-around lat-long image.
- Triangle geometry with object instancing.
- Real-time denoising
- Interactive performance for complex scenes.
- A USD Hydra render delegate called HdAurora.

Cloud based render farms
https://all3dp.com/2/best-render-farm/
“Pricing varies between companies, with fee structures based on aspects like file size and minutes of rendering. Here, we’ve put together a list of 10 great render farms, with many offering a free trial or starting credit. And we’re not playing favorites: The 10 companies are listed in alphabetical order!”
Disney’s Price Hikes Usher in Era of the Not-So-Cheap Ad Tier
“When Disney+’s ad tier launches, in December, it will cost U.S. customers $7.99 a month, the current price of the service’s ad-free tier. The price of the no-ads version will be hiked to $10.99.”
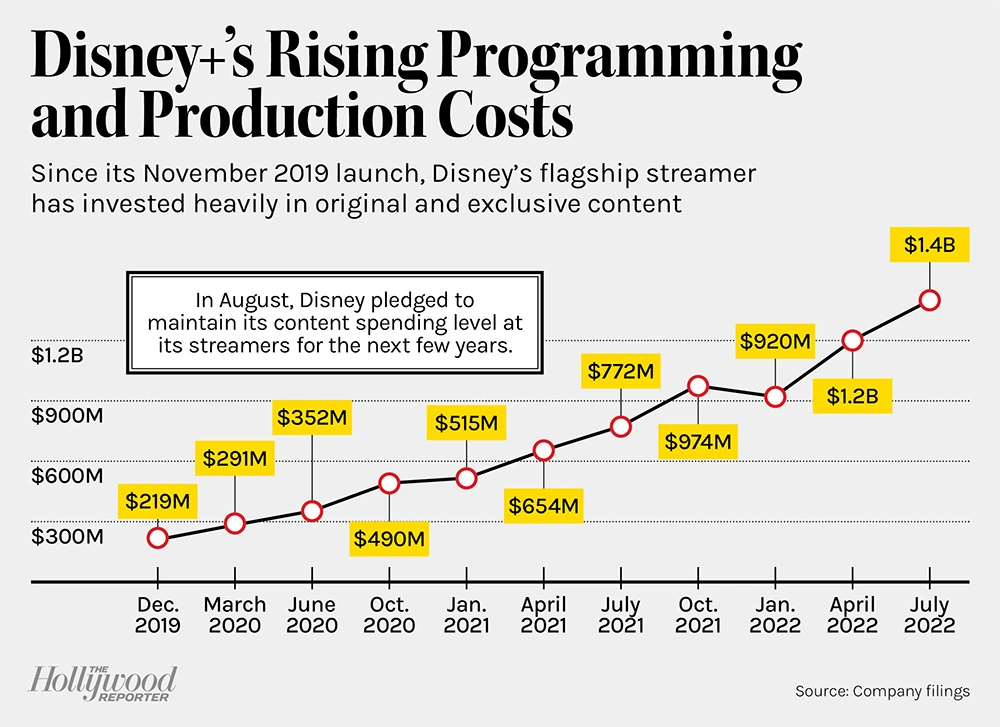
This is balanced out by the company’s plan to keep the rate of content spending for all its platforms at around $30 billion for the next few years and its measured revision of subscriber goals. “It now looks like Disney+ is tracking towards tightened and trimmed sub guidance, while the ad-supported tier + price increases + content rationalization = a much improved long-term profit outlook,” Wells Fargo analyst Steven Cahall wrote in an Aug. 11 note.
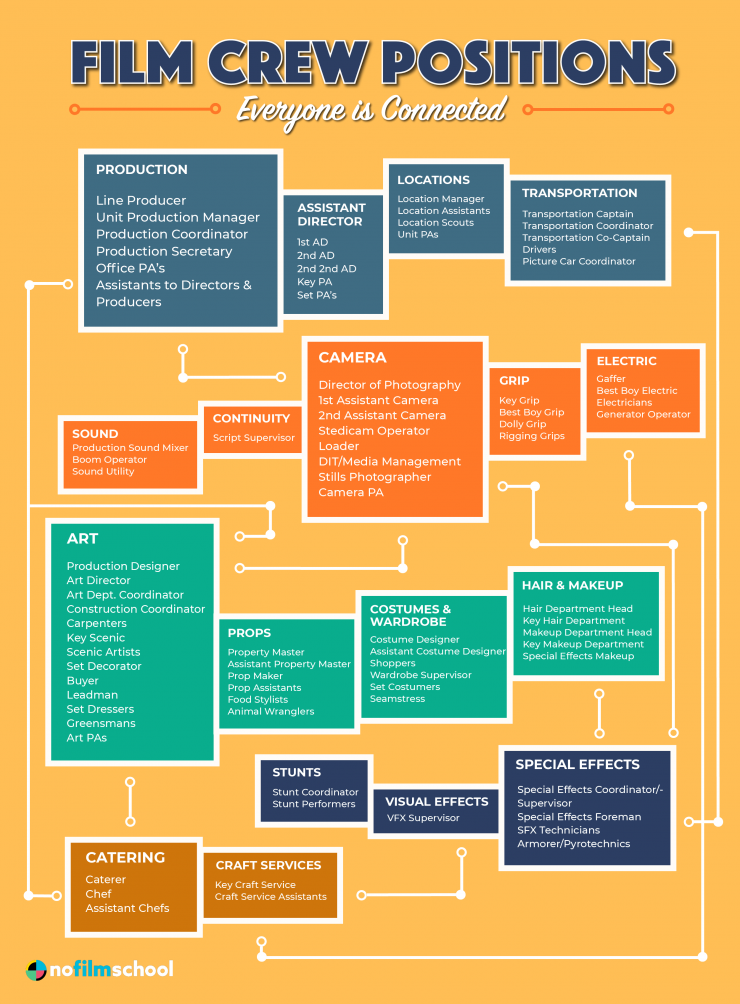
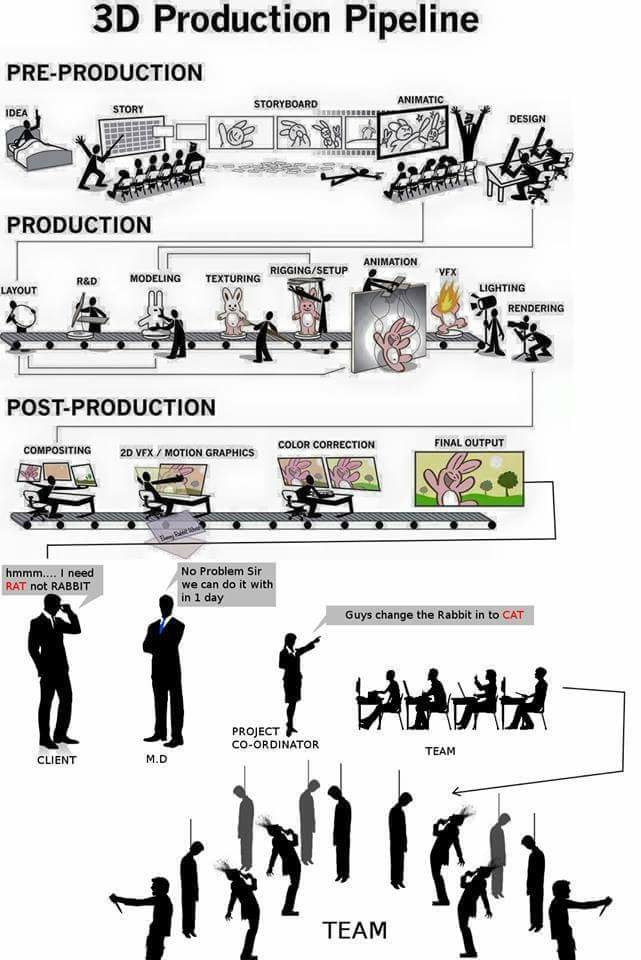
Film Production walk-through – pipeline – I want to make a … movie

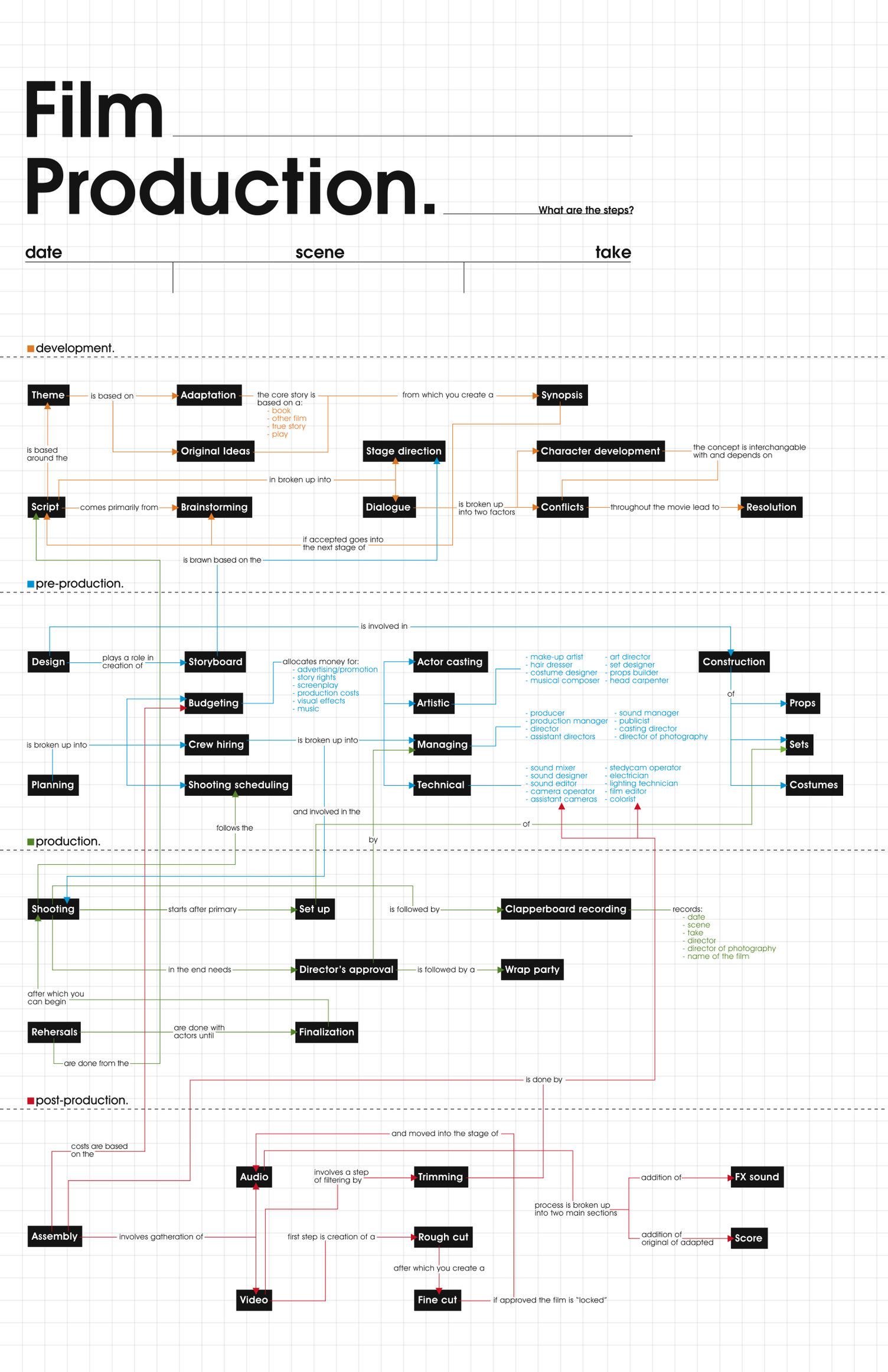
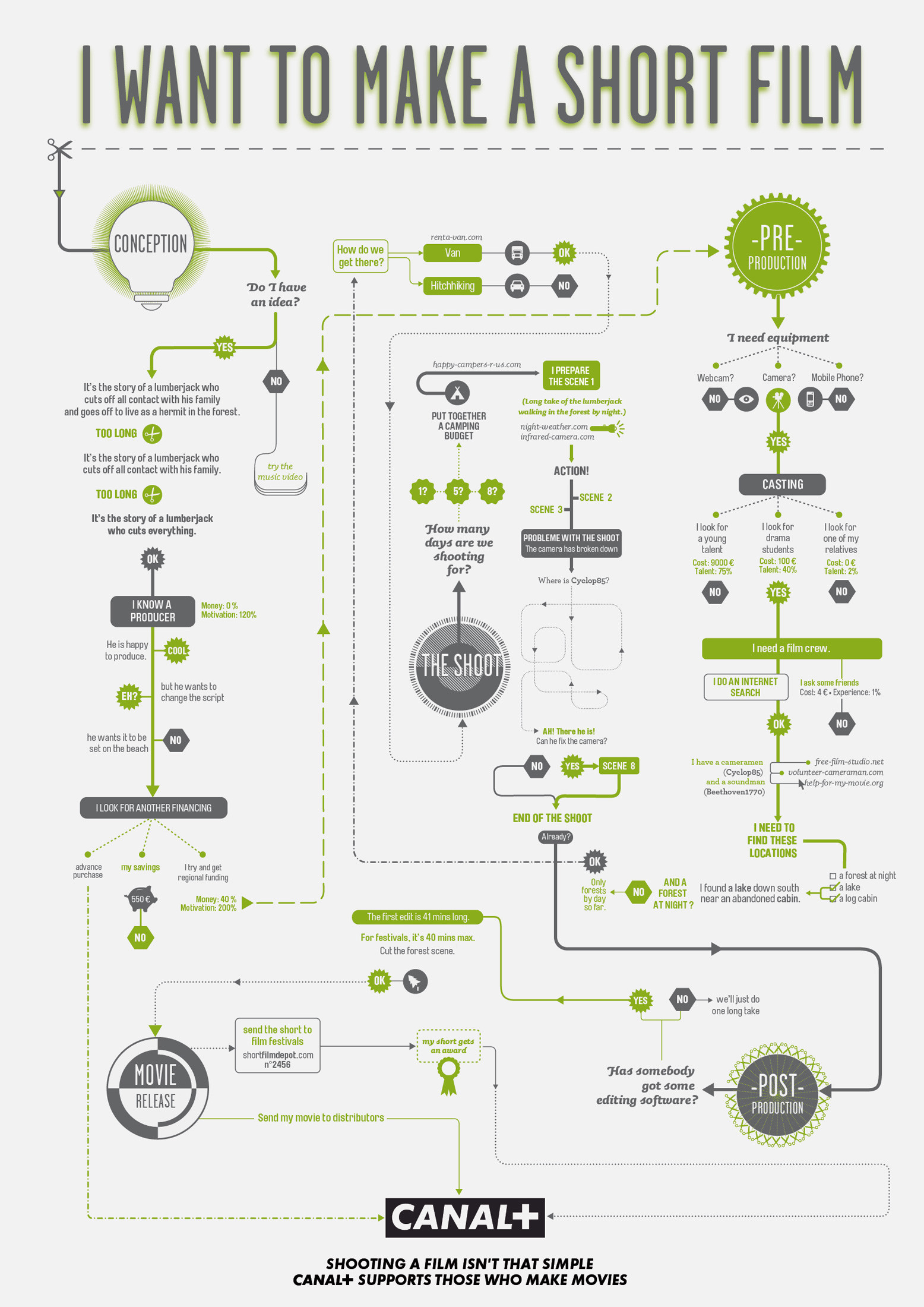
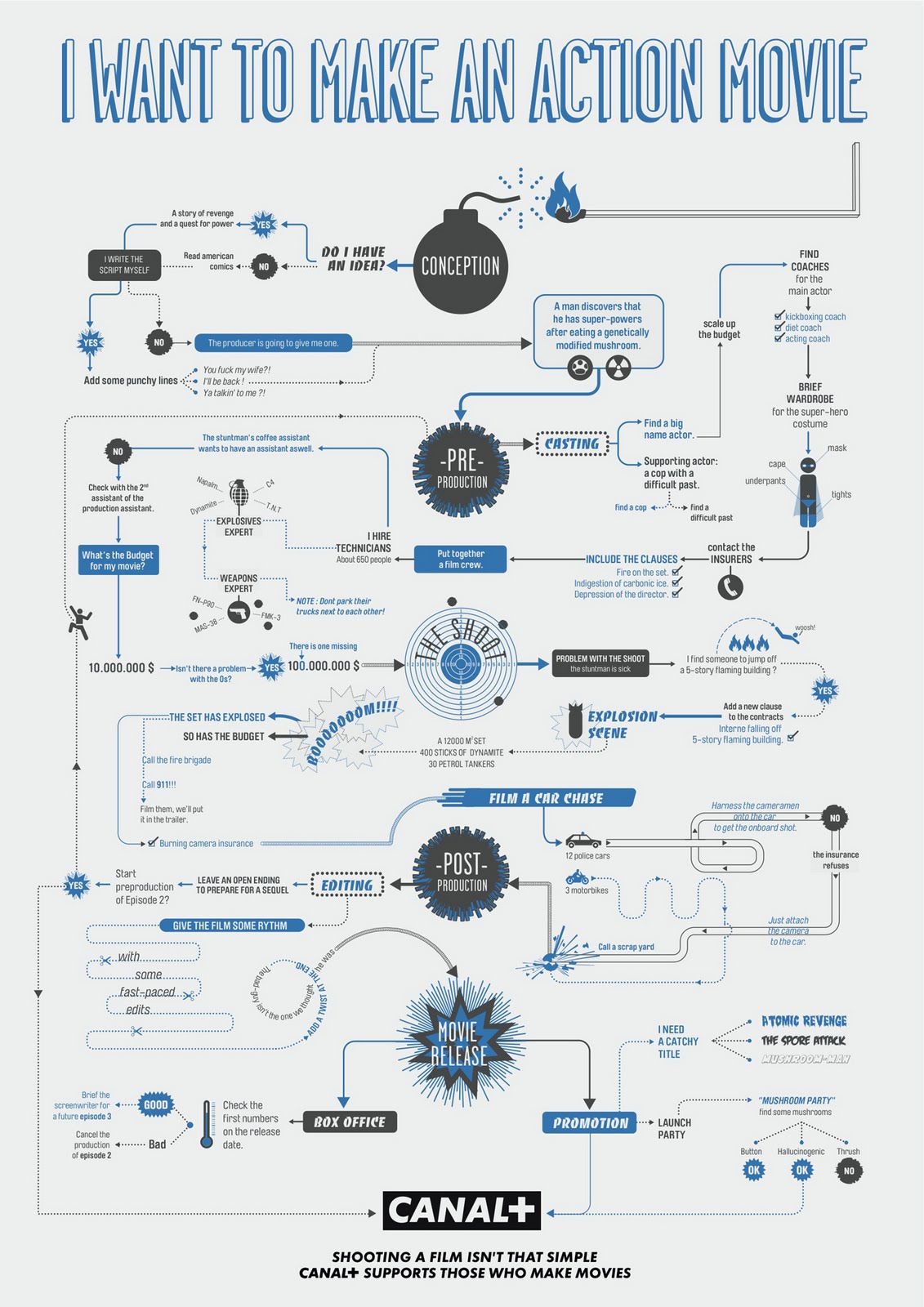



https://www.behance.net/gallery/35474413/Design-Triangle-(re-make)-2016


https://www.behance.net/gallery/9112935/Wonderful-Creative-Process-Chart

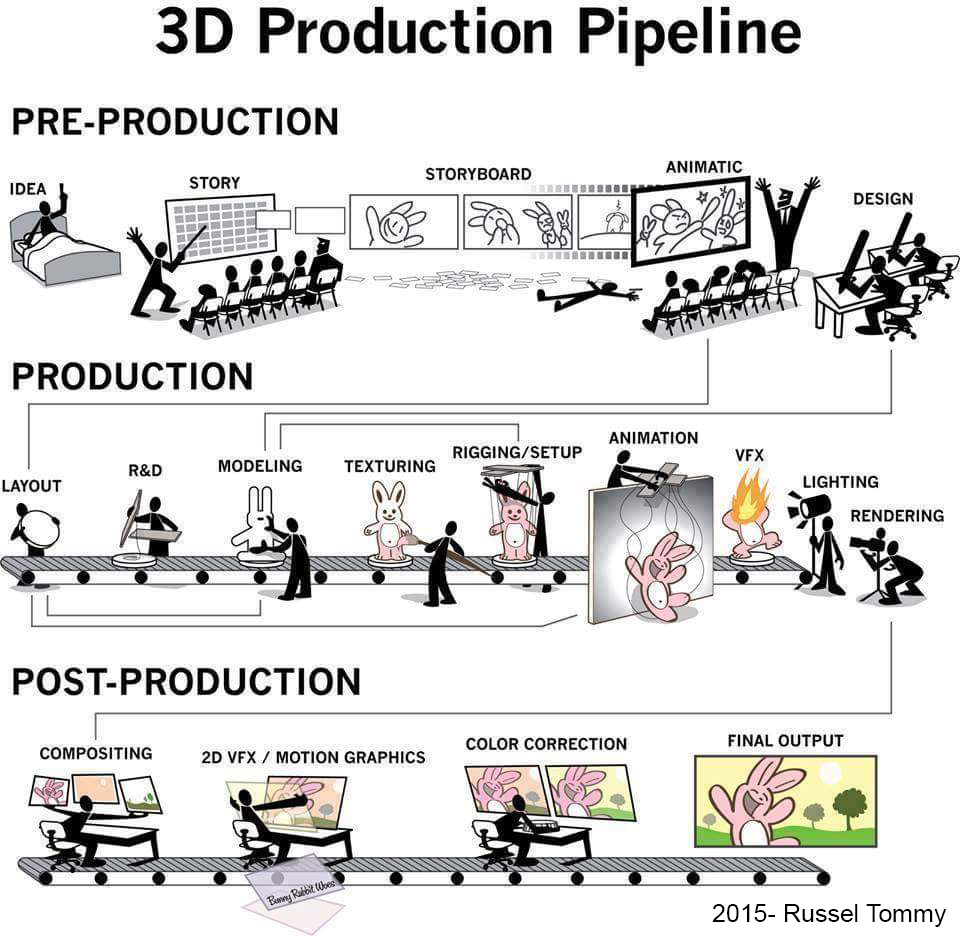
Or the more realistic version
Startup tools and support sites
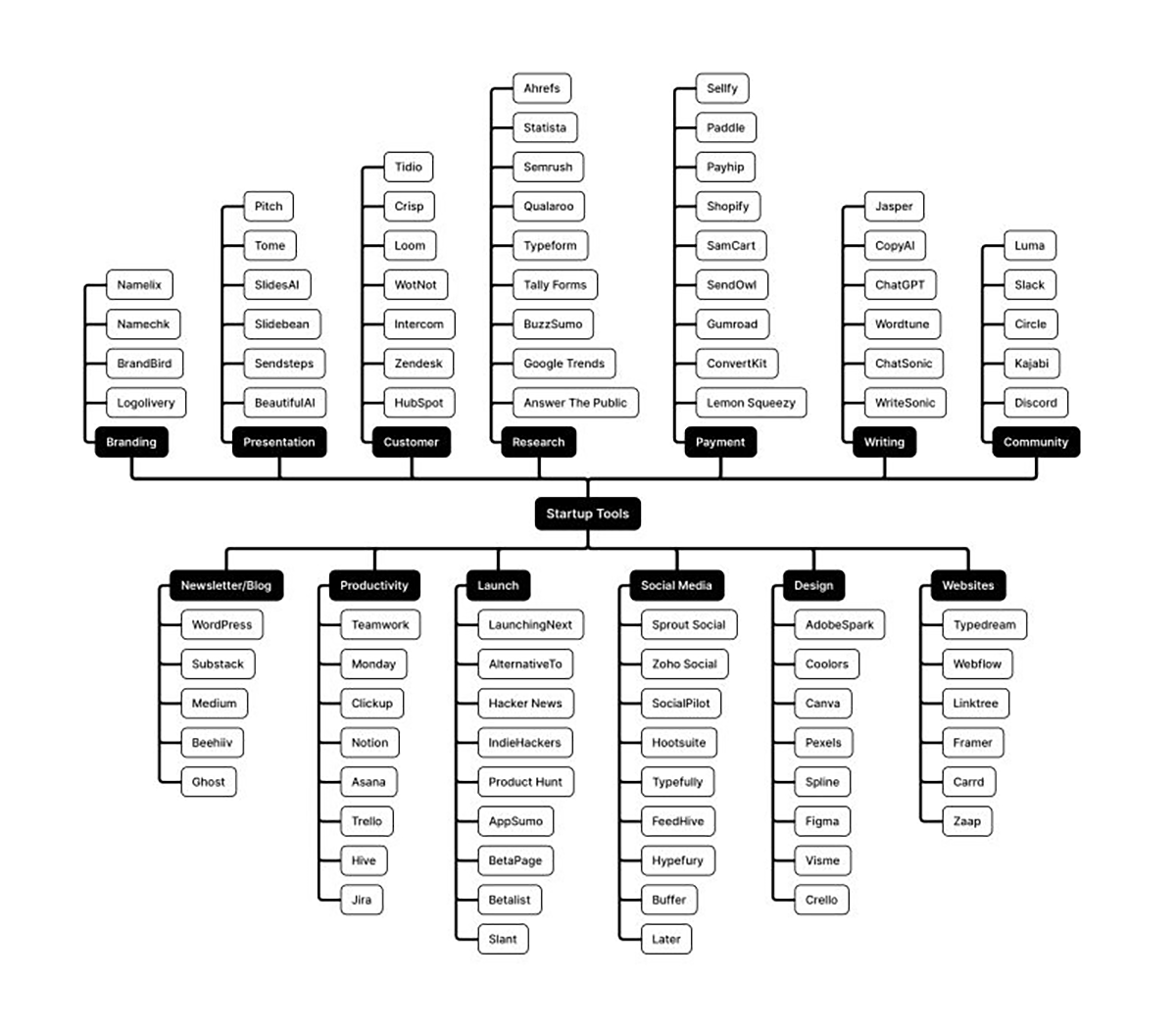
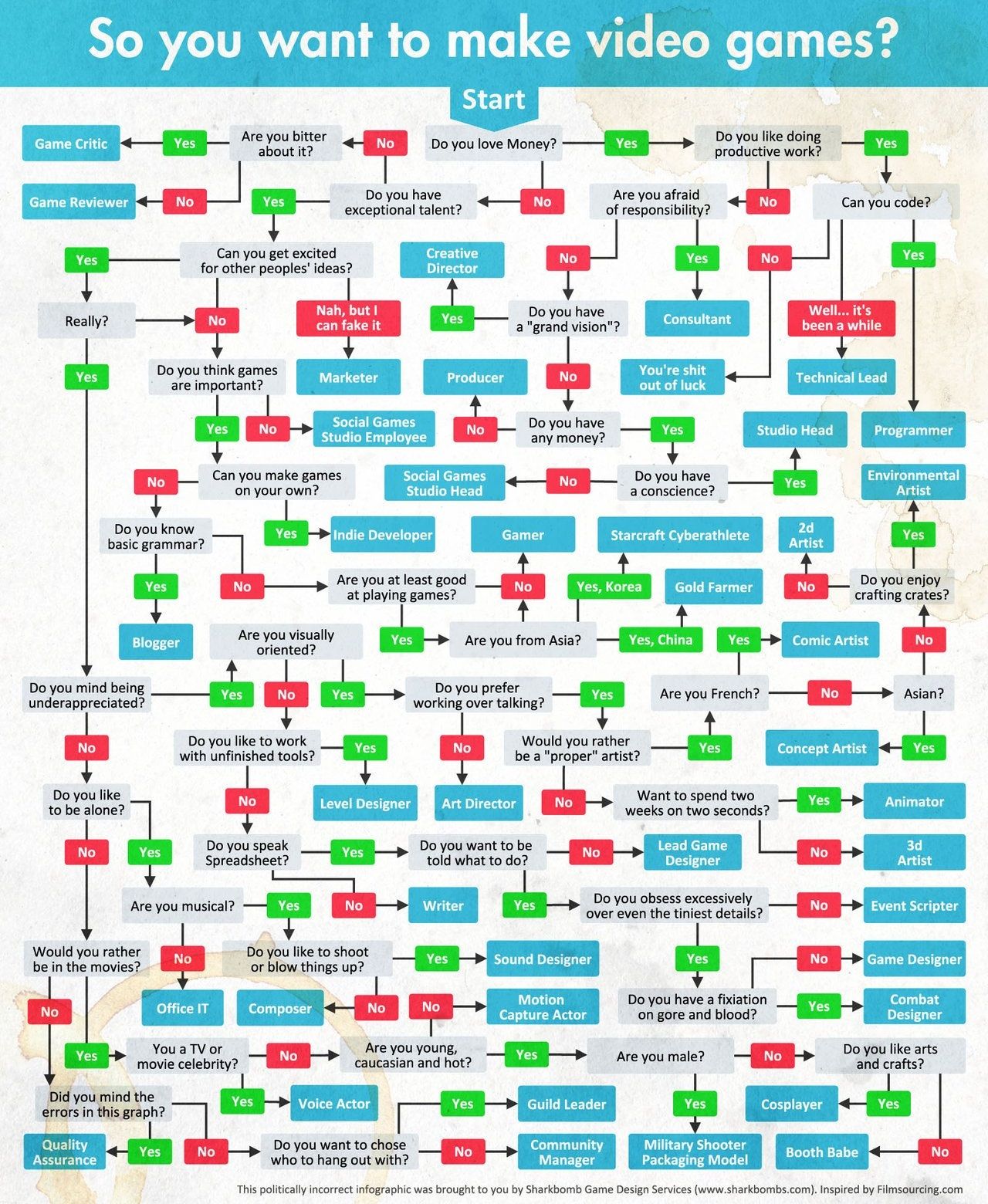
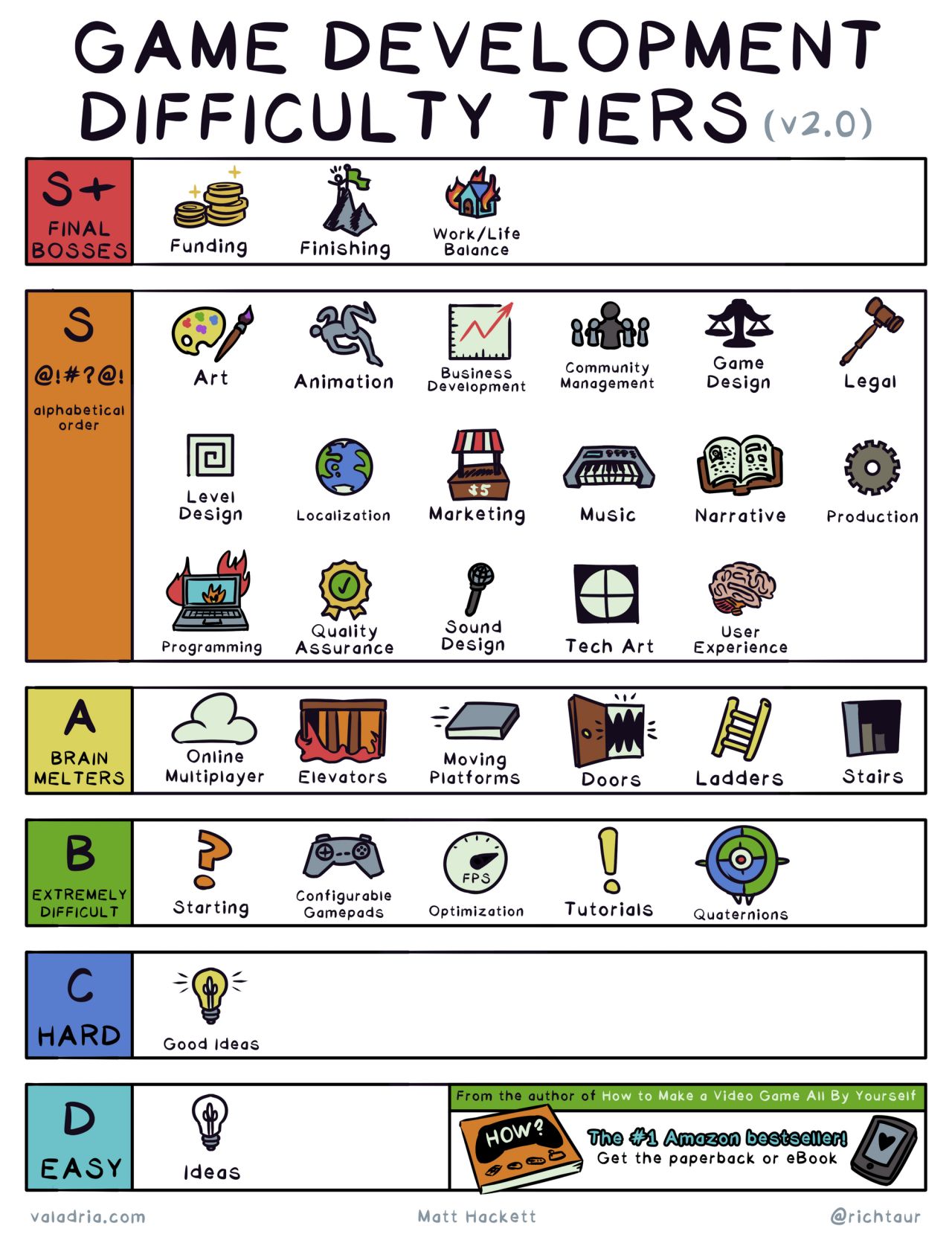
Making an animated movie for free
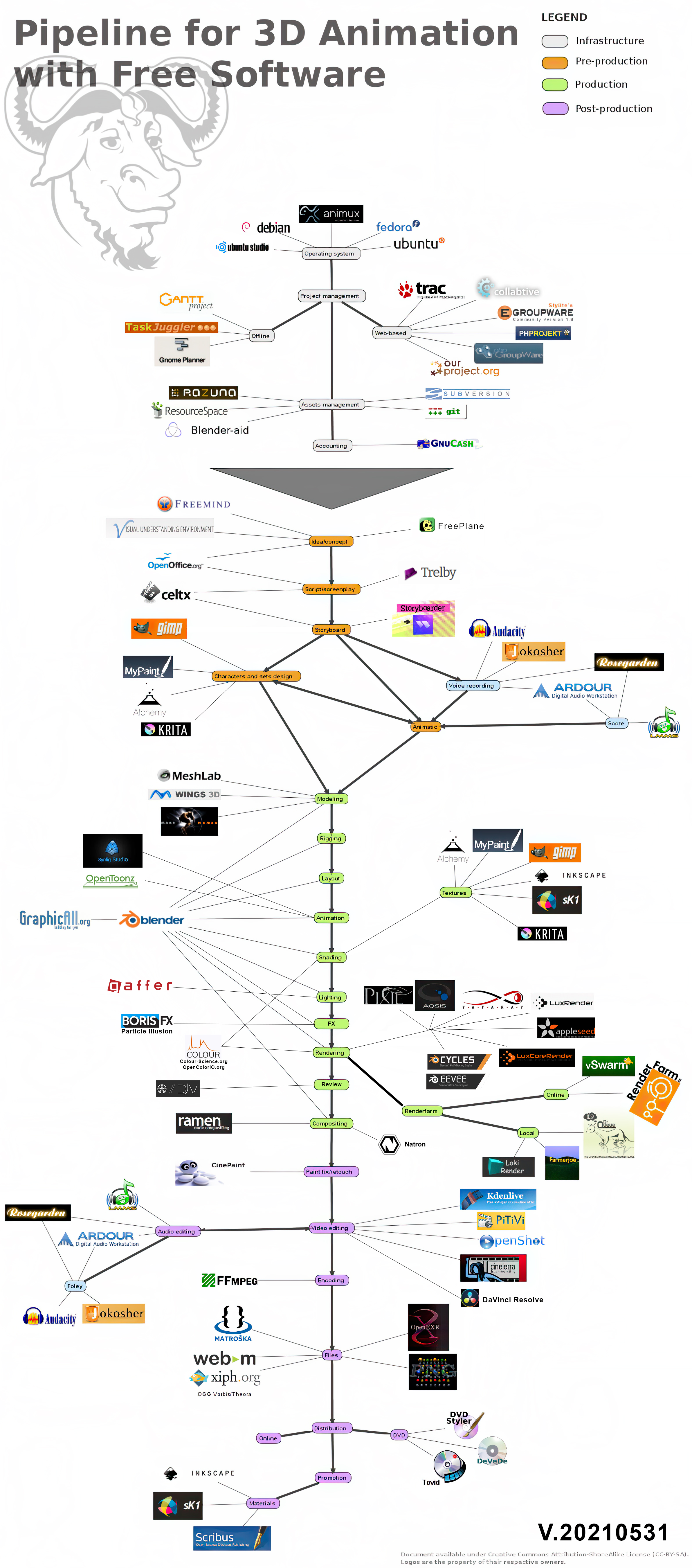
http://www.pixelsham.com/2020/12/07/an-open-source-pipeline/
Netflix removes movie noise, saves 30% bandwidth and adds it back again
https://www.slashcam.com/news/single/Netflix-removes-movie-noise--saves-30--bandwidth-a-17337.html
”’Filmmaker Parker Gibbons has drawn attention to a very interesting fact: Netflix removes film noise before streaming its movies and artificially adds it back when decoding. This is because digitally shot films are actually free of any film grain, the very specific (not to be confused with noise caused by too little light) noise that occurs in analog filming. But this type of noise has become so associated with “real” motion pictures through the long history of film (as a component of the film look) that it is unconsciously perceived by many viewers as an important feature of a motion picture.
…
This leads to a difficult-to-resolve contradiction between, on the one hand, film material that is as compressible and noise-free as possible, and, on the other hand, the noise caused by film grain that is desirable for the film look. Netflix has found a very special solution to resolve this contradiction. It uses a very special function of the open source ![]() AV1 video codec, which Netflix has been using for a long time, namely the artificial
AV1 video codec, which Netflix has been using for a long time, namely the artificial ![]() synthesis of film grain. Thus, film noise is first analyzed using statistical methods before compression and then removed for efficient compression. According to Netflix, this saves around 30% of the data during transmission.”’
synthesis of film grain. Thus, film noise is first analyzed using statistical methods before compression and then removed for efficient compression. According to Netflix, this saves around 30% of the data during transmission.”’

Disco Diffusion V4.1 Google Colab, Dall-E, Starryai – creating images with AI
Disco Diffusion (DD) is a Google Colab Notebook which leverages an AI Image generating technique called CLIP-Guided Diffusion to allow you to create compelling and beautiful images from just text inputs. Created by Somnai, augmented by Gandamu, and building on the work of RiversHaveWings, nshepperd, and many others.
Phone app: https://www.starryai.com/

docs.google.com/document/d/1l8s7uS2dGqjztYSjPpzlmXLjl5PM3IGkRWI3IiCuK7g


colab.research.google.com/drive/1sHfRn5Y0YKYKi1k-ifUSBFRNJ8_1sa39
Colab, or “Colaboratory”, allows you to write and execute Python in your browser, with
– Zero configuration required
– Access to GPUs free of charge
– Easy sharing



https://80.lv/articles/a-beautiful-roman-villa-made-with-disco-diffusion-5-2/



Working from home – tips to help you stay productive
https://www.freecodecamp.org/news/working-from-home-tips-to-stay-productive/
Tip #1 – Build a strong work-life balance
- Take breaks and go outside
- Take up a sport or activity that takes your mind off things
- Split your computer
- Don’t setup work notifications on your phone
- Work from a co-working space
Tip #2 – Create your own working environment
- Choose or create a workspace that stimulates you
- Separate your workspace from your sleeping one
- Declutter your desk
Tip #3 – Socialize at work
- Schedule virtual time with your colleagues
- Try to schedule a social meeting each week in your company
Tip #4 – Become a time-management expert
- Try to have a set work schedule
- Schedule your tasks
Tip #5 – Learn to deep focus
- Listen to focus songs
- Use the “Do not disturb” option on your phone
- Limit distractions
Major breakthrough on nuclear fusion energy
www.bbc.com/news/science-environment-60312633
The fusion announcement is great news but sadly it won’t help in our battle to lessen the effects of climate change.
There’s huge uncertainty about when fusion power will be ready for commercialisation. One estimate suggests maybe 20 years. Then fusion would need to scale up, which would mean a delay of perhaps another few decades.
And here’s the problem: the need for carbon-free energy is urgent – and the government has pledged that all electricity in the UK must be zero emissions by 2035. That means nuclear, renewables and energy storage.
In the words of my colleague Jon Amos: “Fusion is not a solution to get us to 2050 net zero. This is a solution to power society in the second half of this century.”
Streaming wars drive media groups to spend more than $100bn on new content, most at a loss
https://www.ft.com/content/ae756fda-4c27-4732-89af-cb6903f2ab40
From the Financial Times:
The top eight US #media groups plan to spend at least $115bn on new movies and #TV shows next year in pursuit of a video #streaming business that loses money for most of them.
The huge investment outlays come amid concerns that it will be harder to attract new customers in 2022 after the pandemic-fuelled growth in 2020 and 2021. Yet the alternative is to be left out of the streaming land rush.
Most of the companies — a list that includes The Walt Disney Company , Comcast , WarnerMedia and Amazon — are set to rack up losses on their streaming units. Including sports rights, the aggregate spending estimate rises to about $140bn.
But the fact that even the industry leader must invest heavily to churn out shows and keep pace with competitors has caused some investors to ask whether video streaming is a good business.
Netflix is set to spend more than $17bn on content next year — up 25 per cent from 2021 and 57 per cent from the $10.8bn it spent in 2020. The company expects to break even and become free cash flow positive in 2022.
“The market is increasingly concerned there is no pot of gold at the end of this rainbow”, the bank’s analysts said.
Open source resources for down sampling point cloud meshes
MeshLab
www.heritagedoc.pt/doc/Meshlab_Tutorial_iitd.pdf
Instant Meshes
www.blendernation.com/2015/11/16/instant-meshes-a-free-qaud-based-autoretopology-program/
github.com/wjakob/instant-meshes
igl.ethz.ch/projects/instant-meshes/
Open3D
www.open3d.org/docs/release/index.html
www.open3d.org/docs/release/tutorial/geometry/pointcloud.html
Point Cloud Utils
awesomeopensource.com/project/fwilliams/point-cloud-utils
MathWorks pcdownsample
www.mathworks.com/help/vision/ref/pcdownsample.html
Not Open Source
Various software
cmacvfx.com/how-to-decimate-lidar-or-photogrammetry/

Schofield’s Laws of Computing
https://www.freecodecamp.org/news/schofields-laws-of-computing/
“Never put data into a program unless you can see exactly how to get it out.” ― Jack Schofield (2003)
“Data doesn’t really exist unless you have at least two copies of it.” ― Jack Schofield (2008)
“The easier it is for you to access your data, the easier it is for someone else to access your data.” ― Jack Schofield (2008)
Advanced Computer Vision with Python OpenCV and Mediapipe
https://www.freecodecamp.org/news/advanced-computer-vision-with-python/

https://www.freecodecamp.org/news/how-to-use-opencv-and-python-for-computer-vision-and-ai/

Working for a VFX (Visual Effects) studio provides numerous opportunities to leverage the power of Python and OpenCV for various tasks. OpenCV is a versatile computer vision library that can be applied to many aspects of the VFX pipeline. Here’s a detailed list of opportunities to take advantage of Python and OpenCV in a VFX studio:
- Image and Video Processing:
- Preprocessing: Python and OpenCV can be used for tasks like resizing, color correction, noise reduction, and frame interpolation to prepare images and videos for further processing.
- Format Conversion: Convert between different image and video formats using OpenCV’s capabilities.
- Tracking and Matchmoving:
- Feature Detection and Tracking: Utilize OpenCV to detect and track features in image sequences, which is essential for matchmoving tasks to integrate computer-generated elements into live-action footage.
- Rotoscoping and Masking:
- Segmentation and Masking: Use OpenCV for creating and manipulating masks and alpha channels for various VFX tasks, like isolating objects or characters from their backgrounds.
- Camera Calibration:
- Intrinsic and Extrinsic Calibration: Python and OpenCV can help calibrate cameras for accurate 3D scene reconstruction and camera tracking.
- 3D Scene Reconstruction:
- Stereoscopy: Use OpenCV to process stereoscopic image pairs for creating 3D depth maps and generating realistic 3D scenes.
- Structure from Motion (SfM): Implement SfM techniques to create 3D models from 2D image sequences.
- Green Screen and Blue Screen Keying:
- Chroma Keying: Implement advanced keying algorithms using OpenCV to seamlessly integrate actors and objects into virtual environments.
- Particle and Fluid Simulations:
- Particle Tracking: Utilize OpenCV to track and manipulate particles in fluid simulations for more realistic visual effects.
- Motion Analysis:
- Optical Flow: Implement optical flow algorithms to analyze motion patterns in footage, useful for creating dynamic VFX elements that follow the motion of objects.
- Virtual Set Extension:
- Camera Projection: Use camera calibration techniques to project virtual environments onto physical sets, extending the visual scope of a scene.
- Color Grading:
- Color Correction: Implement custom color grading algorithms to match the color tones and moods of different shots.
- Automated QC (Quality Control):
- Artifact Detection: Develop Python scripts to automatically detect and flag visual artifacts like noise, flicker, or compression artifacts in rendered frames.
- Data Analysis and Visualization:
- Performance Metrics: Use Python to analyze rendering times and optimize the rendering process.
- Data Visualization: Generate graphs and charts to visualize render farm usage, project progress, and resource allocation.
- Automating Repetitive Tasks:
- Batch Processing: Automate repetitive tasks like resizing images, applying filters, or converting file formats across multiple shots.
- Machine Learning Integration:
- Object Detection: Integrate machine learning models (using frameworks like TensorFlow or PyTorch) to detect and track specific objects or elements within scenes.
- Pipeline Integration:
- Custom Tools: Develop Python scripts and tools to integrate OpenCV-based processes seamlessly into the studio’s pipeline.
- Real-time Visualization:
- Live Previsualization: Implement real-time OpenCV-based visualizations to aid decision-making during the preproduction stage.
- VR and AR Integration:
- Augmented Reality: Use Python and OpenCV to integrate virtual elements into real-world footage, creating compelling AR experiences.
- Camera Effects:
- Lens Distortion: Correct lens distortions and apply various camera effects using OpenCV, contributing to the desired visual style.
Interpolating frames from an EXR sequence using OpenCV can be useful when you have only every second frame of a final render and you want to create smoother motion by generating intermediate frames. However, keep in mind that interpolating frames might not always yield perfect results, especially if there are complex changes between frames. Here’s a basic example of how you might use OpenCV to achieve this:
import cv2
import numpy as np
import os
# Replace with the path to your EXR frames
exr_folder = "path_to_exr_frames"
# Replace with the appropriate frame extension and naming convention
frame_template = "frame_{:04d}.exr"
# Define the range of frame numbers you have
start_frame = 1
end_frame = 100
step = 2
# Define the output folder for interpolated frames
output_folder = "output_interpolated_frames"
os.makedirs(output_folder, exist_ok=True)
# Loop through the frame range and interpolate
for frame_num in range(start_frame, end_frame + 1, step):
frame_path = os.path.join(exr_folder, frame_template.format(frame_num))
next_frame_path = os.path.join(exr_folder, frame_template.format(frame_num + step))
if os.path.exists(frame_path) and os.path.exists(next_frame_path):
frame = cv2.imread(frame_path, cv2.IMREAD_ANYDEPTH | cv2.IMREAD_COLOR)
next_frame = cv2.imread(next_frame_path, cv2.IMREAD_ANYDEPTH | cv2.IMREAD_COLOR)
# Interpolate frames using simple averaging
interpolated_frame = (frame + next_frame) / 2
# Save interpolated frame
output_path = os.path.join(output_folder, frame_template.format(frame_num))
cv2.imwrite(output_path, interpolated_frame)
print(f"Interpolated frame {frame_num}") # alternatively: print("Interpolated frame {}".format(frame_num))
Please note the following points:
- The above example uses simple averaging to interpolate frames. More advanced interpolation methods might provide better results, such as motion-based algorithms like optical flow-based interpolation.
- EXR files can store high dynamic range (HDR) data, so make sure to use cv2.IMREAD_ANYDEPTH flag when reading these files.
- OpenCV might not support EXR format directly. You might need to use a library like exr to read and manipulate EXR files, and then convert them to OpenCV-compatible formats.
- Consider the characteristics of your specific render when using interpolation. If there are large changes between frames, the interpolation might lead to artifacts.
- Experiment with different interpolation methods and parameters to achieve the desired result.
- For a more advanced and accurate interpolation, you might need to implement or use existing algorithms that take into account motion estimation and compensation.
How to Build a Hackintosh
https://www.freecodecamp.org/news/build-a-hackintosh/
A Hackintosh is a non-Mac computer system, made with PC parts, that runs the macOS operating system.

The Rookies – Creative Industries Certification
The Rookies is working on an ambitious task to create a free online resource that will standardize the skills and knowledge for digital artists on a global stage. The resource will outline essential creative and technical skills required by all artists before applying for industry positions in VFX, video games and animation.
To get involved, give back and help others as they start their career pathing, click on links below and give your insights! Everyone has value to add!
3D Animation: https://lnkd.in/gSJPdFS
Visual Effects: https://lnkd.in/gk2-gNM
Games: https://lnkd.in/ghdGVbN